관련 링크 : https://arxiv.org/abs/1911.05722
Self-Supervised Learning : MoCo(2019)
Abstract
Dictionary와 Contrastive Learning을 이용한 unsupervised learning 방법인 MoCo를 제안한다.
1. Introduction
이미지는 high-dimensional space에 존재하는 연속적인 데이터로 언어처럼 구조화되지 않고 따라서 tokenized dictionaries를 만들기 어렵다. 하지만 NLP는 이를 위한 별도의 signal space(단어, 문자)가 있고, 단어나 문자에는 unsupervised method가 적용되기 쉽다. 따라서 unsupervised learning은 NLP에서 뛰어난 성능을 보이지만, visual task에는 아직 supervised learning에 미치지 못한다.
몇몇 연구들은 contrastive loss를 이용해 unsupervised learning을 시도했다. 이 연구들의 핵심 동기는 제각각이다. 하지만 모두 dynamic dictionaries를 만드는 것으로 볼 수 있다. 이 경우 데이터를 encoder에 통과시켜 key와 query를 만들고, unsupervised learning을 이용해 query를 매칭되는 key와는 유사하게, 매칭되지 않는 key와는 차별화 되도록 학습시킨다.
CPCv2에서 ResNet을 이용해 이미지를 벡터화하고 이를 Masked ConvNet에 통과시켜 얻은 벡터를 projection해 Masked ConvNet을 통과하기 전의 값과 비교하는 방식으로 contrastive loss를 이용한다. 이때 Masked ConvNet을 통과시켜 얻은 벡터를 query, 통과 시키기 전의 벡터를 key라고 볼 수 있다.
이런 관점에서 dictionary는 Large, key들은 Consistent 할수록 좋다고 가정한다. 이는 이미지가 연속적이고 high-dimensional space에 존재하므로 dictionary가 클수록 negative sample하기 좋고, encoder에 의해 만들어진 key들은 query와 비교해서 consistent 할수록 좋기 때문이다. 하지만 기존 방식들은 두 관점 중 하나가 제한된다.
consistent 할수록 loss가 급격히 변하지 않기 때문에 좋다.
따라서 본 논문은 위 두 관점을 모두 수용한 Momentum Contrast(MoCo)를 제안한다.
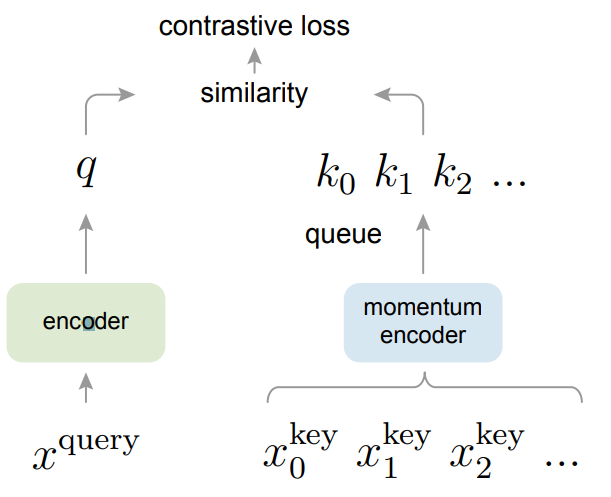
-
Dictionary는 queue로 mini-batch 크기와 무관하게 커질 수 있으며, 새로운 mini-batch의 encoded representation이 들어오면 가장 오래된 representation이 빠진다.
-
Dictionary의 key는 이전 mini-batch들로 만들어지기 때문에 query encoder의 momentum-based moving average로 구현되는 slowly progressing key encoder가 가능하다.
PIRL의 경우 memory bank안의 represnetation에 moving average를 적용했다.
-
다양한 pretext task를 사용할 수 있다.
2. Related Work
- Loss functions
- L1, L2, Cross-entropy : pretext task에 따라 다르게 사용됨
- Contrastive Loss : representation space에서 sample pair의 유사도를 측정할때 사용
- NPID, CPC, CMC
- Adversarial Loss : 확률분포 사이의 차이를 측정. 주로 GAN에서 사용되며 NCE와 어느정도 관계가 있음
- Pretext tasks
- 변형이 가해진 입력을 복원 : denoising/context/cross-channel(colorization) auto-encoder
- Pseudo-label을 이용 : Exemplar/Jigsaw/Deep Clustering
- Contrastive learning vs. pretext task
- NPID는 Exemplar와, CPC는 context auto-encoder와, CMC는 cross-channel auto-encoder와 관계있음
3. Method
3.1 Contrastive Learning as Dictionary Look-up
Contrastive Learning을 위해 InfoNCE라 불리는 loss function을 사용한다.
\[\mathcal L_q = -\log \frac {\exp(q\cdot k_{+}/\tau)}{\sum ^K_{i=0}\exp (q\cdot k_i \tau)} \tag 1\]- $q$ : encoded query
- $\{k_0, k_1, k_2, \ldots\}$ : dictionary의 key들로 encoded sample의 집합, $k_+$는 $q$와 일치하는 key,
- $\tau$ : temperature hyper-parameter
직관적으로 $q$를 $k_+$로 분류하는 $K+1$개의 softmax-based classifier의 log loss로 볼 수 있다.
이 loss function은 query와 key를 만들어내는 encoder network를 학습시키기 위한 함수다. 일반적으로 query는 $q=f_q(x^q)$로, key는 $k=f_k(x^k)$로 만들어지는데, 각각의 encoder $f_q$, $f_k$는 방법에 따라 동일하거나 일부 요소만 공유하거나 완전히 다를 수 있다. 입력인 $x^q$, $x^k$또한 마찬가지로 pretext task에 따라 이미지/패치/패치들일 수 있다.
3.2 Momentum Contrast
Dictionary는 negative sample을 많이 포함하기 위해 크고, key들은 가능한 consistent해야 한다는 기준에 맞춰서 Momentum Contrast를 제안한다.
Dictionary as a queue
- Dictionary를 queue로 사용해 dictionary의 크기를 mini-batch 크기와 무관하게 조절해 dictionary를 크게 만든다.
- 직전에 계산된 mini-batch의 encoded representation이 queue에 들어오면 가장 오래된 representation을 제거해 dictionary를 consistent하게 유지한다.
Momentum update
-
Queue를 이용해 dictionary를 크게 만들면 queue안의 모든 샘플에 대해 gradient를 backpropagation해야 하므로 $f_k$를 학습시키기 어렵다.
- 단순한 방법은 gradient를 무시하고 $fq$를 이용해 $f_k$를 구성하는 것인데, 성능이 처참했다. 이는 $f_k$가 급격히 변해 key representation의 consistency를 감소시켰기 때문으로 보인다.
-
이 문제를 Momentum update를 이용해 해결한다.
-
\[\theta_k \leftarrow m\theta_k + (1-m)\theta_q \tag 2\]
- $m \in [0, 1)$ : momentum coefficient로 $m=0.999$가 $m=0.9$보다 성능이 좋다.
- $\theta_q$ : $f_q$의 파라미터, $\theta_k$ : $f_k$의 파라미터
- $k$가 변화하는 encoder $f_k$에 의해 만들어 지더라도 변화의 정도가 느리므로 consistency가 유지된다.
-
\[\theta_k \leftarrow m\theta_k + (1-m)\theta_q \tag 2\]
Relations to previous mechanisms
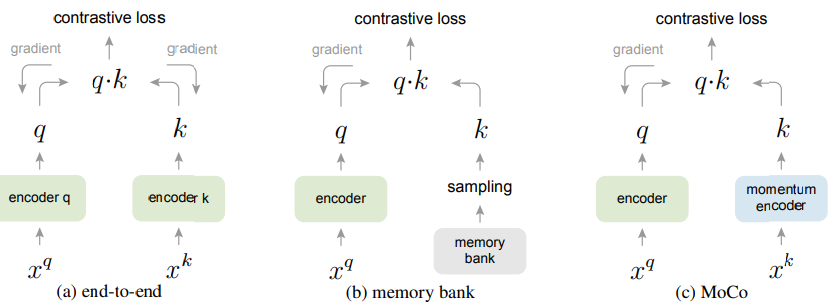
- (a) : 각 학습당 입력되는 mini-batch 하나를 dictionary로 사용하여 key들의 consistency를 유지한다.
- Dictionary 크기가 mini-batch 크기로 제한되고 dictionary를 크게 하기위해 mini-batch 크기를 키우면 large mini-batch optimization 문제에 직면한다.
- pretext task에 따라 특별한 네트워크가 필요해 downstream task로 transfer하기 힘들다.
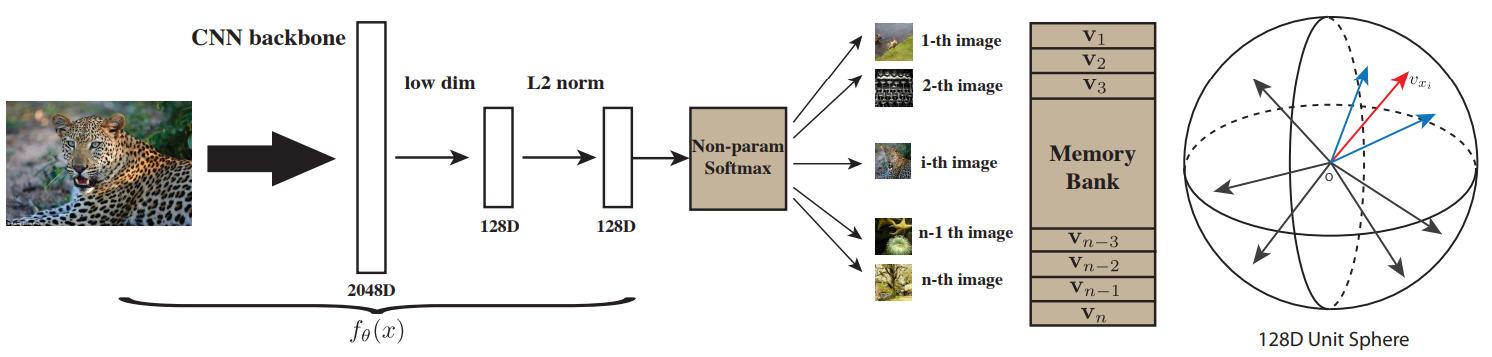
- (b) : 데이터셋의 모든 샘플들의 representation을 memory bank에 저장해 dictionary로 사용해 dictionary의 크기가 커진다.
- memory bank의 representation은 각 샘플이 $f_q$에 들어갔을때만 업데이트된다. 즉, key들은 여러 epoch에 걸친 다른 $f_k$에 의해 만들어 졌으므로 consistency가 떨어진다.
- MoCo처럼 Momentum update를 사용하지만 $f_k$가 아닌 memory bank안의 represnetation에 사용한다.
3.3 Pretext Task
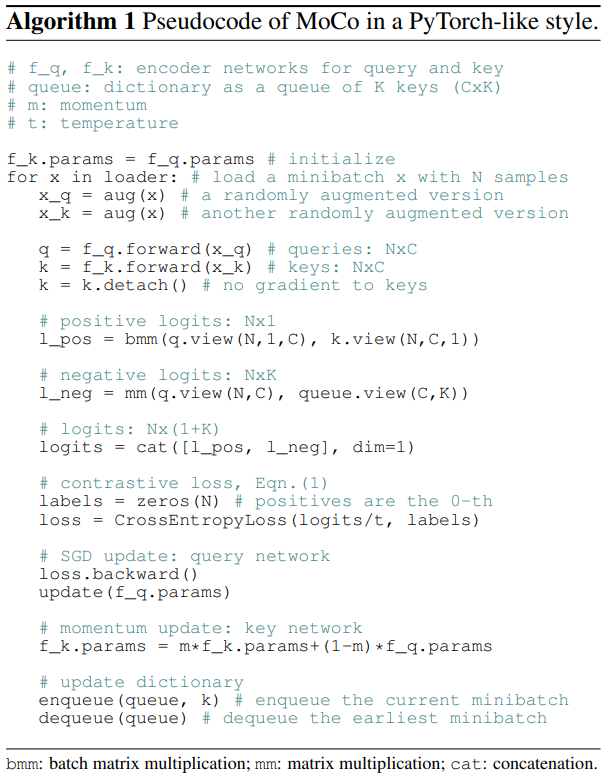
NPID와 Exemplar의 각 이미지 하나를 class로 보는 방식을 사용했다.
Technical details
- Encoder로 $\mathrm {ResNet-AvgPool-FCL-L2\;norm}$를 사용해 128-D의 $q$와 $k$를 얻었다.
- Data augmentation : 이미지를 randomly resized한 후 224x224로 crop하고 color jittering/horizontal fip/grayscale conversion를 적용했다.
- $\tau=0.07$을 사용했다.
NPID에 적용된 방식들이다. $f_\theta$가 encoder와 동일하다.
Shuffling BN
-
BN은 모델이 배치 의존성을 이용해 shortcut을 찾는데 일조하므로 모델의 성능을 떨어뜨린다.
- 따라서 GPU에 따라 독립적으로 BN을 적용하고 추가적으로 $f_k$의 경우 mini-batch를 여러 GPU에 나누기 전에 뒤섞고, encoding한 후 다시 한번 섞는다. 이로서 $k$는 encoding되기 전 batch statistic과 encoding된 후 batch statistic이 달라져 모델이 이를 shortcut으로 이용할 수 없다.
CPCv2, simCLR에서도 동일한 이유로 다른 방법을 사용했다.
- Memory bank를 사용하는 경우에는 각 key들이 다른 mini-batch에서 온 것이므로 상관 없다.
4. Experiments
Datasets
- ImageNet-1M : well-balanced class distribution을 가지고 iconic view들로 이루어져 있다.
- Instagram-1B : unbalanced, long-tailed class distribution를 가지고 iconic object/scene-level image로 이루어져 있다.
Training
- Optimizer
- SGD with weight decay is $0.0001$ and momentum is $0.9$
- Learning Rate
- ImageNet : $0.03$ multiplied by $0.1$ at $120$ and $160$ epochs(Total $200$ epochs)
- Instagram : $0.12$ with exponentially decayed by $0.9\times$ every $62.5\mathrm k$ iteration(Total $\sim1.4$ epochs)
- Mini-Batch Size
- ImageNet : $256$ in $8$ GPUs
- Instagram : $1024$ in $64$ GPUs
4.1 Linear Classification Protocol
- Feature들은 frozen시킨 상태로 linear classification 성능을 검증한다.
- Classifier를 학습하기위해 grid search를 수행해서 hyper parameter를 찾았다.
- optimal initial learning rate : $30$, weight decay : $0$
- 이 hyper parameter는 supervised training과 unsupervised learning의 feature distributions이 상당히 다를 수 있음을 의미한다.
Ablation: contrastive loss mechanisms
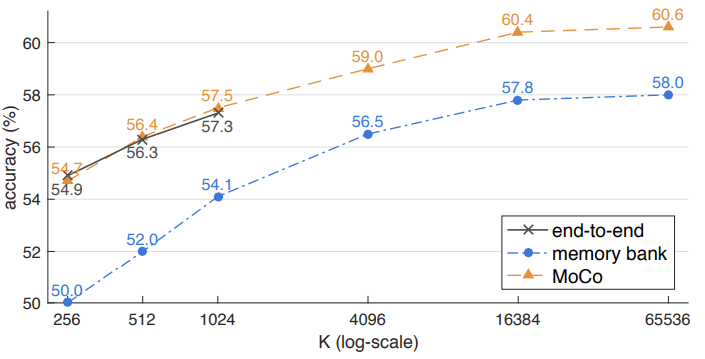
- 3.2에서 언급한 세가지 방법 모두 negative sample의 수가 많아지면 성능이 좋아진다. end-to-end의 경우 dictionary 크기 제한때문에 mini-batch가 너무 커지면 학습 시킬 수 없었다.
Ablation: momentum
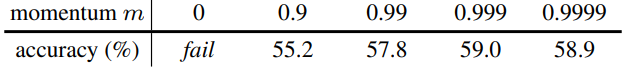
$K=4069$일때의 MoCo로 ResNet-50을 pretrain했을때 성능이다.
- consistency를 위해 momentum을 크게 해야한다.
Comparison with previous results
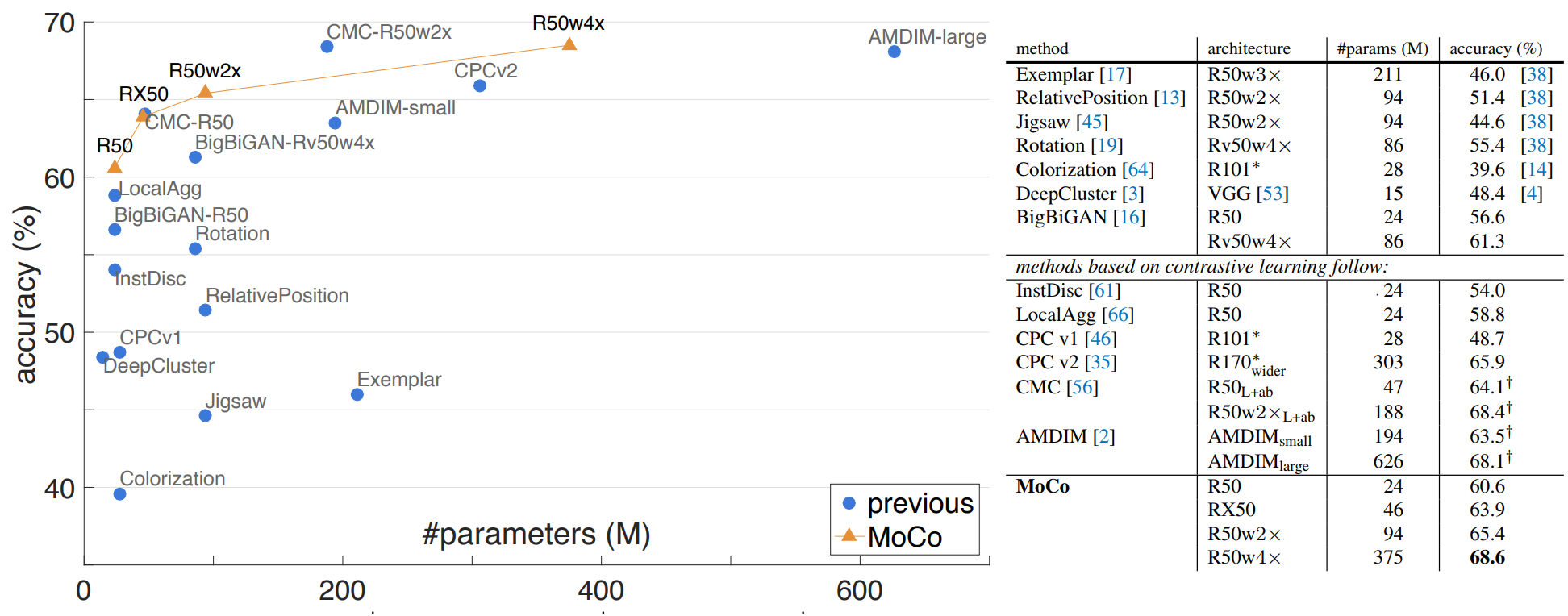
비교하기에 각 방법들이 다양한 모델과 사이즈를 가지고 있으므로, parameter 수를 이용해 비교했다.
- MoCo는 특별한 patched input이나 네트워크 구조를 사용하지 않고 좋은 성능을 보인다.
- MoCov2는 simCLR의 장점 몇개를 가져와 MoCo에 적용시킨 것으로, 71.1%의 정확도를 보인다.
4.2 Transferring Features
- Unsupervised learning의 목적 중 하나는 downstream task로 잘 trasfer 될 수 있는 feature를 학습하는 것이다.
- ImageNet pretrained model로 PASCAL VOC, COCO 등의 다양한 task에서 성능을 비교한다.
Normalization
- 4.1에서 논의한것 처럼 supervised와 unsupervised의 feature distribution은 상당히 다르다.
- 따라서 fine-tuning동안 BN은 freeze하지 않고, downstream task에 사용될 추가된 네트워크에도 BN을 사용한다.
- Fine-tuning동안 normalizaiton을 수행하므로 supervised setting과 동일한 hyper parameter를 사용한다.
Schedules
-
Fine-tuning 시간이 길다면 random initialized된 detector도 좋은 성능을 보일 수 있다. 하지만 trasferability를 측정하기 위해서 supervised method처럼 짧은 시간동안만 학습시킨다.
- 비교를 위해서 random initialization도 학습시킨다.
Supervised는 detector와 feature extractor를 함께 학습하므로 시간이 짧아도 되지만, MoCo는 transfer하기 위해서는 더 많은 시간이 필요하다. 하지만 실험에서는 Detectron에 사용된 것과 동일하게 학습한다. 이는 Supervised ResNet을 transfer할 때보다 적은 시간이다.
-
결과적으로 MoCo는 supervised setting으로 학습하므로 완벽한 최고 성능을 보이지 못하지만, 그럼에도 상당히 좋은 성능을 보인다.
4.2.1 PASCAL VOC Object Detection
Ablation: backbones
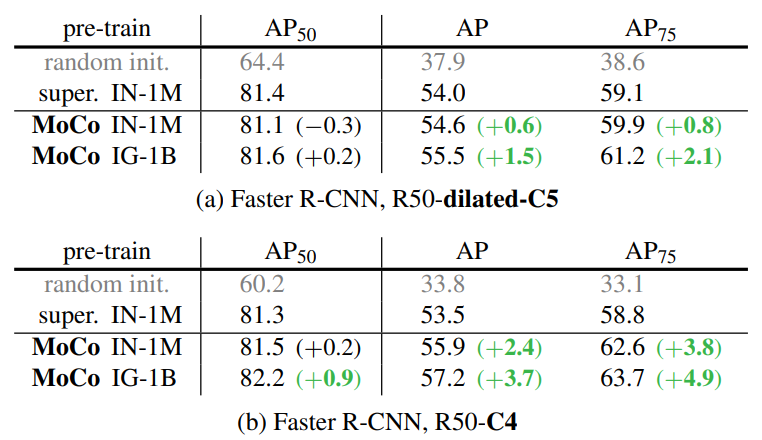
$24\mathrm k$ iteration($\sim 23$ epochs)동안 학습시켰다.
Ablation: contrastive loss mechanisms
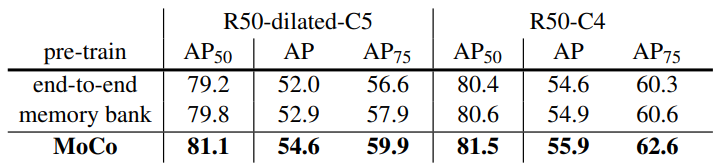
3.2에서 언급한 기존 방식들과의 성능 비교
Comparison with previous results

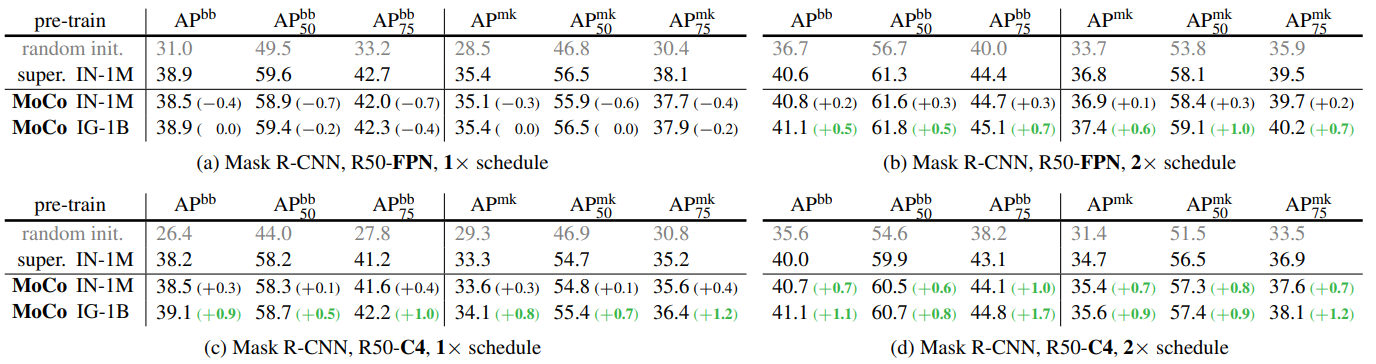
4.2.2 COCO Object Detection and Segmentation
Results
4.2.3 More Downstream Tasks
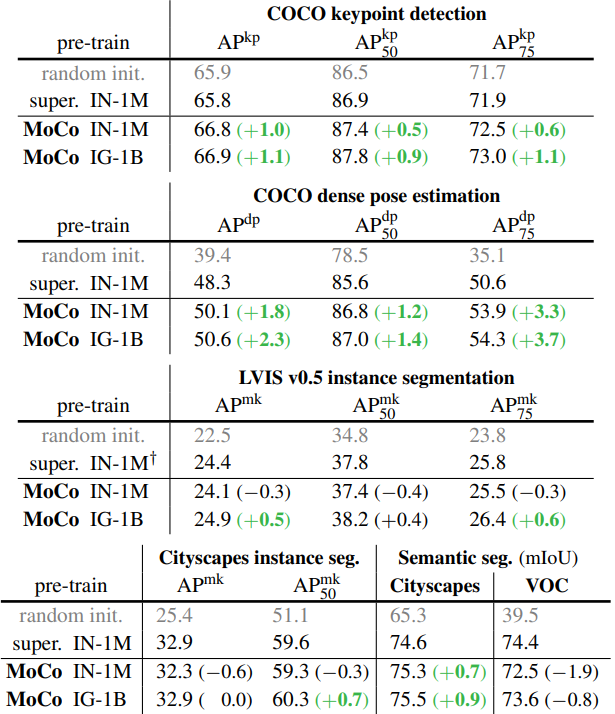
Summary MoCO는 대부분의 downstream task에서 좋은 성능을 보이고, large-scale, relatively uncurated dataset에서 좋은 성능을 보인다.
5. Discussion and Conclusion
- MoCo는 다른 방법들과 비교해봐도 상당히 뛰어난 성능을 보인다.
- 더 큰 데이터셋을 사용하면 성능이 증가했으나, 데이터셋의 크기가 늘어난 것에 비하면 상당히 조금 증가했다.
- 더 간단한 pretex task가 발견된다면 MoCo에 적용해 볼 수 있을 것이다.
A. Appendix
- 흥미로운 몇가지만 정리하였다.
A.7 Fine-tuning in ImageNet
본문의 실험에서는 encoder의 feature는 freeze시키고 classification을 학습시켰다. 이번에는 freeze시키지 않고 학습시켜본다.
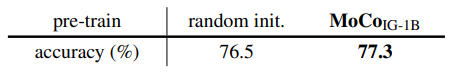
MoCo pretraining에 사용된 데이터셋이 downstream task와 다른 Instagram Dataset임에도 random init보다 뛰어난 성능을 보인다.
A.9 Ablation on Shuffling BN
4.2절에서 언급한 Normalization을 하지 않았을때의 성능을 확인해본다.
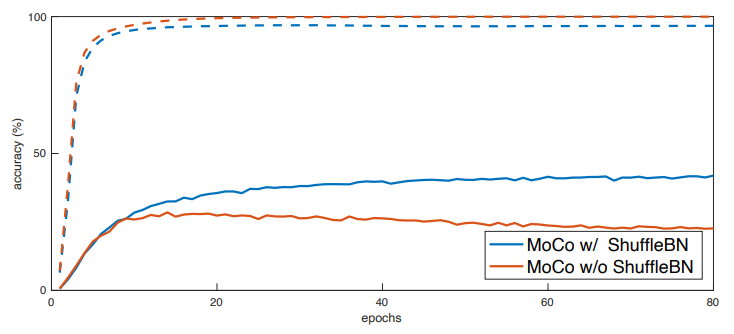
점선은 pretext task($(K+1)$-way dictionary lookup)의 training curve, 실선은 classification accuracy
Leave a comment