관련 링크 : https://arxiv.org/abs/1409.1556
Architecture : VGGNet(2014)
Abstract
논문의 목적은 아주 작은 3x3 필터들을 사용해 깊이를 늘리는 것이 정확도에 어떤 영향을 주는지 밝혀내는 것이다. 논문의 모델은 ImageNet Challenge 2014에서 localization과 classification에서 각각 첫 번째, 두 번째로 뛰어난 성능을 보였고, 다른 dataset에서도 통했다.
1. Introduction
거대한 이미지 dataset, 고성능의 계산 능력(GPU), large-scale distributed clusters(NN을 여러 Machine이 나눠서 학습)덕분에 ConvNet은 이미지 인식에서 뛰어난 성능을 보였다.
이를 더욱 발전시키기 위해서 더 작은 receptive window size와 첫 번째 Conv layer에서 더 작은 stride를 사용해보고, training과 testing에서 이미지 전체를 densly하게 적용하거나 다양한 scale로 적용하는 등의 시도가 있었다.
본 논문에서는 ConvNet 구조 설계에서 또 다른 관점인 깊이에 대해 논할 것이다.
2. ConvNet Configurations
2.1 Architecture
- Training시 input은 224x224 RGB로 고정한다. 전처리는 RGB 평균값을 빼주는것 외에는 하지 않는다.
- ConvLayer의 stride는 1로 고정시키고, Conv후 해상도를 동일하게 하기 위해 spatial padding한다.
- Max-pooling layer는 5개로, 2 stirde의 2x2 filter를 가진다.
- FC는 첫 두개는 4096 dimension, 마지막은 1000 dimension을 가진다.
- 모든 hidden layer 다음에는 ReLU를 쓴다.
- LRN(Local Response Normalization)는 효과가 없고 계산량만 늘려서 사용하지 않았다.
2.2 Configurations
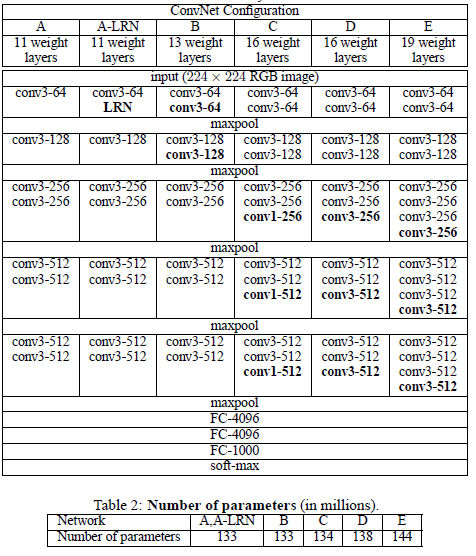
ConvNet의 구성은 위의 표에 나타냈다. 파라미터 수를 보면 더 큰 width와 receptive fields를 사용한 얕은 Net보다 파라미터수가 적다.(다른 논문의 얇은 Net은 144M개의 피라미터를 가짐)
2.3 Discussion
3x3 ConvLayer 세 개를 사용하는게 7x7 ConvLayer 하나를 사용하는 것과 같은데, 3개의 non-linear 층을 사용해서 decision function이 더 discriminative해지고, 파라미터의 수가 더 작기 때문에 효과적이다.
3x3 ConvLayer 3개 : $3(3\times 3C^2)=27C^2$
7x7 ConvLayer 1개 : $7 \times 7C^2=49C^2$
$C^2$의 경우는 입력의 채널과 출력의 채널이 각각 $C$라고 가정했기 때문
여기서 1x1 ConvLayer는 Non-linearity를 추가해준다.
GoogleNet의 경우처럼 채널수를 줄여서 연산량을 줄이지는 않음
3. Classification framework
3.1 Training
학습법은 mini-batch gradient descent(momentum)으로, batch size : 256, momentum : 0.9, weight decay : $5\times 10^{-4}$ 를 사용했다. 앞의 두 FCL에는 0.5의 확률로 Dropout layer를 사용했다. Learning rate는 $10^{-2}$로 시작해서 학습이 멈출때마다 10씩 나눠주었다.
파라미터 수는 많지만, 작은 필터 사이즈와 깊은 층에 의한 implicit regularization과 특정 층의 pre-initialisation 때문에 빨리 학습된다고 추측했다.
implicit regularization이 뭘 의미하는걸까?
파라미터 초기화가 잘못되면 성능에 영향을 주므로 이를 막기 위해 무작위 초기화로 학습될 수 있는 얇은 모델을 학습시키고, 학습된 후의 값으로 더 깊은 모델의 특정 층들을 초기화시켰고, 추가된 층들은 평균이 0이고 분산이 0.01인 정규분포를 사용해 초기화했다.
이후, 위 과정들 없이 파라미터들을 초기화하는 방법이 있다는 것을 알았다.(Understanding the difficulty of training deep feedforward neural networks, p249~256, 2010)
Xavier initialization
224x224의 고정된 이미지를 얻기 위해서 rescaled된 이미지에서 무작위로 잘라냈고, Alexnet에서 사용한 수평 뒤집기와 RGB shift를 이용했다.
Training image size
왜곡없이 rescaled된 훈련용 이미지의 가장 작은 변을 $S$라고 하자. $S$는 최소 224이다. 사용한 학습은 고정된 $S$값을 이용하는 single-scale training과 여러 개의 $S$값을 사용하는 multi-scale training으로 두 가지다.
- single-scale training은 $S=256$, $S=384$로 rescale시켰고, 학습 속도를 위해서 $S=384$일때는 선학습된 $S=256$ 모델의 파라미터를 이용하고 learning rate는 으로 $10^{-3}$줄여서 사용했다.
- multi-scale training은 $[256, 512]$사이에서 무작위로 뽑은 $S$값으로 rescale 시켰고, 이를 scale jittering이라고 한다. 학습 속도를 올리기 위해서 선학습된 $S=384$모델의 피라미터를 이용했다.
3.2 Testing
미리 정의한 $Q$값에 따라서 왜곡없이 rescaled시키고, 이 이미지들을 desnly하게 네트워크에 입력한다. 입력값의 해상도가 제각각이므로 FCL를 Fully-convolutional net으로 바꾸어서 최종적으로 class 수와 같은 채널수를 가진 class score map을 얻고, 입력에 따라 다른 해상도를 가진 score map을 고정된 형태의 벡터로 만들기 위해 평균을 취한다. 입력 이미지의 수평 뒤집기도 이용한다.
Fully-convolutional net은 이미지 전체를 사용하므로 crop할 필요가 없어서 연산량이 줄지만, large crop set을 사용하는게 성능이 향상된다. 즉, multi-crop evaluation(pre-proccess)이 dense evaluation(pooling)을 보완하므로 둘 다 사용한다. multi-crop에 따른 계산량 증가가 정확도에 영향을 미치는지는 불분명하다고 생각했지만, 실험을 위해서 각 이미지당 3개의 스케일과 각 스케일당 50개를 crop해서 사용했다.
Dense evaluation은 pooling layer의 입력에 bias를 행, 렬에 각각 주면서 여러개의 feature map을 만들고, 이를 channel이 아닌 resolution에서 합쳐주어 pooling layer의 출력의 resolution이 줄어들지 않아 더 많은 정보를 담게하는 방법이다. 자세한 내용은 OverFeat 논문에 나온다.
3.3 Implementation Details
학습에는 여러개의 GPU를 병렬로 이용했고, 단일 GPU보다 3.75배 빨랐다.
4. Classification Experiments
Dataset
ILSVRC-2012 dataset으로 1000개의 class를 가진 이미지로 이루어져 있다. training(1.3M), validation(50k), testing(100K). 분류 평가는 top-1, top-5 error로, 전자는 잘못 분류한 이미지의 비율, 후자는 5개의 예측 class에 정답이 없는 이미지의 비율이다.
4.1 Single scale evaluation
Single scale evaluation에서는 고정된 $S$에선 $Q=S$를 사용했고, scale jittering의 경우 $Q=0.5(S_{min} +S_{max})$를 사용했다.
- LRN은 효과가 없음이 나타났다(A-LRN, A).
- Non-linearity의 추가가 성능을 향상시켰다(B, C).
- B의 3x3층 두 개를 모두 5x5로 바꾸어서 비교했을 때, 작은 필터를 가진 깊은 network가 큰 필터를 가진 얕은 network보다 성능이 뛰어났다.
- training시 scale jittering이 고정된 $S$를 사용한 것보다 효과가 좋았다.
4.2 Multi-Scale Evaluation
training과 testing의 스케일이 크게 다르면 성능이 떨어진다. 따라서, 고정된 $S$일때 $Q={S-32,\;S,\;S+32}$를 사용했고, scale jittering시에는 $Q={S_{min},\;0.5(S_{min}+S_{max}),\;S_{max}}$를 사용했다.
결과적으로 scale jittering이 효과가 좋았다.
4.3 Multi-Crop Evaluation
dense evaluation과 multi-crop evaluation을 둘 다 사용하는게 효과가 제일 좋았다.
4.4 ConvNet Fusion
여러 모델에서 Softmax이후의 고정된 벡터를 평균낸 값을 이용해서 성능을 향상시킬수 있다. 논문에선 가장 성능이 좋은 모델 두 개를 합치는게 가장 성능이 좋았다.
4.5 Comparision with the state of the art
5. Conclusion
망의 깊이가 분류 성능에 효과가 있다.
A. Localisation
A.1 Localisation ConvNet
object localisation을 위해선 마지막단의 FCL의 출력을 중심좌표, 너비, 높이를 가지는 4-D 벡터로 바꿔주면 된다. 출력은 두가지로 선택할 수 있는데, 하나는 SCR(single class regression)으로 하나의 class만 예측하고 다른 하나는 PCR(per-class regression)으로 전체 class를 예측하므로 출력이 4000-D 벡터로 바뀐다.
Training
모델은 classification과 유사한데, 가장 큰 차이는 loss function이 ground-truth와 예측값 간의 Euclidean loss로 바뀐 것이다. $S=256$과 $S=384$의 single scale 모델을 학습시켰고, 바뀐 마지막 FCL를 빼고 모두 fine-tuning했다.
Testing
Testing은 두 가지 방식으로, 첫 번째는 classification error를 고려하지않고 가장 좋은 localisation 성능을 가진 모델을 찾는데, center crop을 이용한다. 두 번째는 그 모델을 이용해서 Sect 3.2에서와 동일하게 Testing하는 것이다. 이때 이전과는 달리 마지막단 출력이 bounding box prediction이므로 greedy merging procedure을 거친다. 출력에 class는 없으므로, class 예측에는 앞서 학습된 모델을 사용한다.
greedy merging은 spatially하게 가까운 prediction끼리 좌표를 평균내서 합치고, 다른 분류 모델에서 얻은 각 prediciton의 class값에서 가장 큰 것을 이용한다
A.2 Localisation Experiments
Settings comparison
PCR이 SCR보다 성능이 좋았고, FCL만 fine-tuning하는 것 보다 모든 layer를 하는게 성능이 좋았다. $S=256$ 과 $S=384$가 성능이 비슷해서 표에는 $S=384$만 나타냈다.

Fully-fledged evaluation
위의 실험으로 가장 성능이 좋은 PCR 모델을 이용해서 앞서 정의한 Fully-fledged evaluation을 실시한다.
Comparison with the state of the art
B. Generalisation of Very Deep Features
VGGnet의 feature extroactor로서의 성능이 다른 dataset에도 잘 적용된다. 마지막 FCL만 목적에 맞게 변형하고, 다른 layer들의 weights는 고정시킨채로 학습을 시키면 가능하다.



Leave a comment