관련 링크 : https://arxiv.org/abs/1811.12231
딥 러닝이 시작인 퍼셉트론이 사람의 뇌를 본따 만들어진 이후, 실제 생물의 신경 활동을 기반으로 많은 연구들이 이루어졌다. 현재 컴퓨터 비전에서 가장 많이 사용되는 분야인 CNN도 그 중 하나로, 그 구조가 제안된 순간부터 지금까지 대부분의 이미지 처리 모델에서 사용되고 있다. 하지만 많은 딥 러닝 모델들이 그렇듯, 모두가 CNN의 성능이 좋음은 알고 있지만 왜 효과가 좋은지는 몰랐고, 현재까지 이와 관련된 많은 연구들이 제안되었다.
오늘 소개할 논문은 CNN과 관련된 연구로, 가장 널리 받아들여지고 있는 ‘CNN은 대각 성분 같은 Low-level features를 조합해 사물의 모양같은 복잡한 High-level features를 만들어 사물을 분류한다’는 직관을 반박한다. 이 직관은 사람의 사물 인식 체계에서 가장 중요한 것이 Texture나 Size가 아닌 Shape라는 것과 더불어 많은 실험적 결과들에 의해 뒷받침 되었고, 논문에서는 이를 ‘Shape hypothesis’라고 말한다.
하지만 최근 이를 반박하는 많은 연구들이 제안되었다. 가장 결정적인 것은 모든 레이어의 Receptive field를 제한시켰을때도 CNN이 높은 성능을 보였다는 Brendel & Bethge(2019)의 연구로, 모델이 입력 사진의 일부만 보고도 분류 성능이 좋게 나왔다는 것은, 전체를 봐야 알 수 있는 사물의 Shape보다 일부만 보고 알 수 있는 Texture를 이용해 분류 했음을 뜻한다. 논문에서는 이를 ‘Texture hypothesis’라고 부르며, 둘 중 어느 이론이 맞는지를 검증한다.
Shape Vs Texture
그럼, 이때까지 CNN이 무엇을 더 중요시해서 판단해 왔는지 어떻게 알 수 있을까? 저자들은 먼저 기존에 사용된 모델들에게 Texture 정보를 제거했을때와 Texture 정보만 있을때 성능을 비교했다.
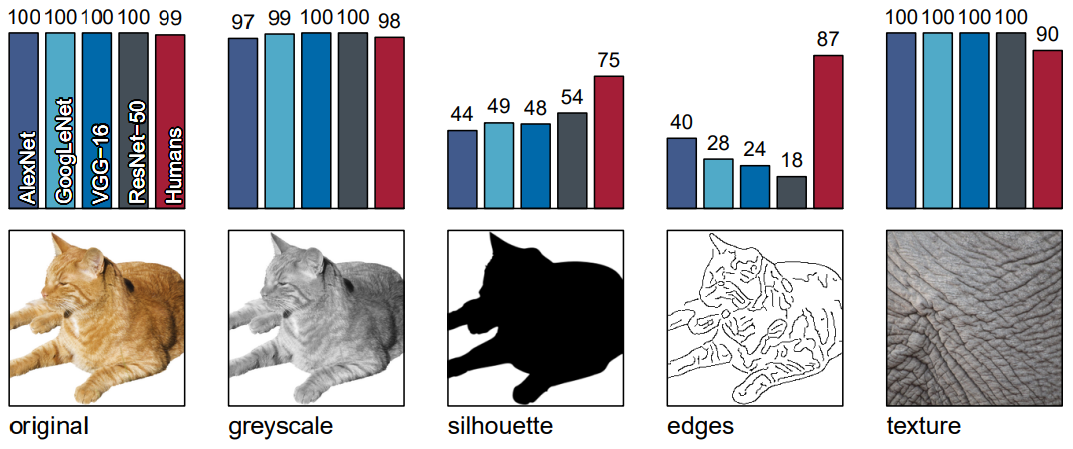
위 그림에서 알 수 있듯, Original과 Greyscale은 Shape와 Texture를 모두 보존한 반면, Silhouette과 Edges는 Texture 정보가 많이 제거되었다. 따라서 모델의 성능은 급격히 떨어졌지만, 사람의 경우는 Shape를 이용해 판단하므로 잘 대처했다. 하지만 이 결과가 모델이 Texture 정보에 의존해 결과를 도출함을 뜻할까? 이는 Texture hypothesis의 근거일 수 있지만, 단지 CNN 모델이 통계적으로 부자연스러운 이미지들에 대처 능력이 떨어짐을 뜻 할 수도 있다. 따라서 저자들은 자연스러우면서 원래의 Texture 정보를 제거한 이미지를 만들어 실험을 진행했다.

이미지는 Style Trasnfer를 이용해 만들었고, 위의 (c)처럼 생겼다. 이렇게 만들어진 이미지는 Texture에 기반한 정답 Indian elephant와 Shape에 기반한 정답 tabby cat을 가지면서 통계적으로 자연스러우므로, 모델에게 결과를 예측하도록 시켜 의존성을 측정했다.

위 그림에서 빨간색 원은 사람: 95.9% shape vs 4.1% texture, 보라색 다이아몬드는 AlexNet: 42.9% vs 57.1%, 파란색 삼각형은 VGG-16: 17.2% vs 82.8%, 하늘색 원은 GoogLeNet: 31.2% vs 68.8%, 회색 사각형은 ResNet-50: 22.1% vs 77.9%이다. 각 선은 위의 수치로 나타난 선택 비율을 뜻하고, 오른쪽의 막대 그래프는 맞춘 비율을 의미한다.
실험 결과를 보면 대부분의 모델이 Shape보다는 Texture에 근거해서 결과를 도출해 냄을 알 수있다. 이는 위 네가지 모델 외에도, 더 크고 복잡한 DenseNet-121, SqueezeNet등에서도 공통적으로 나타나는 현상이다. 그럼, 실제로 사람이 판단하는 것처럼 Shape-biased하게 모델을 만들수는 없을까?
논문에서는 Texture 정보를 제거한 SIN(Stylized-ImageNet)을 만들어 이를 이용해 학습한 모델은 어느정도는 Shape-biased라고 가정하고 동일한 실험을 수행했다.

위는 SIN의 예시로, (c)와 유사하지만 Texture로 다양한 화가의 그림을 이용했다.
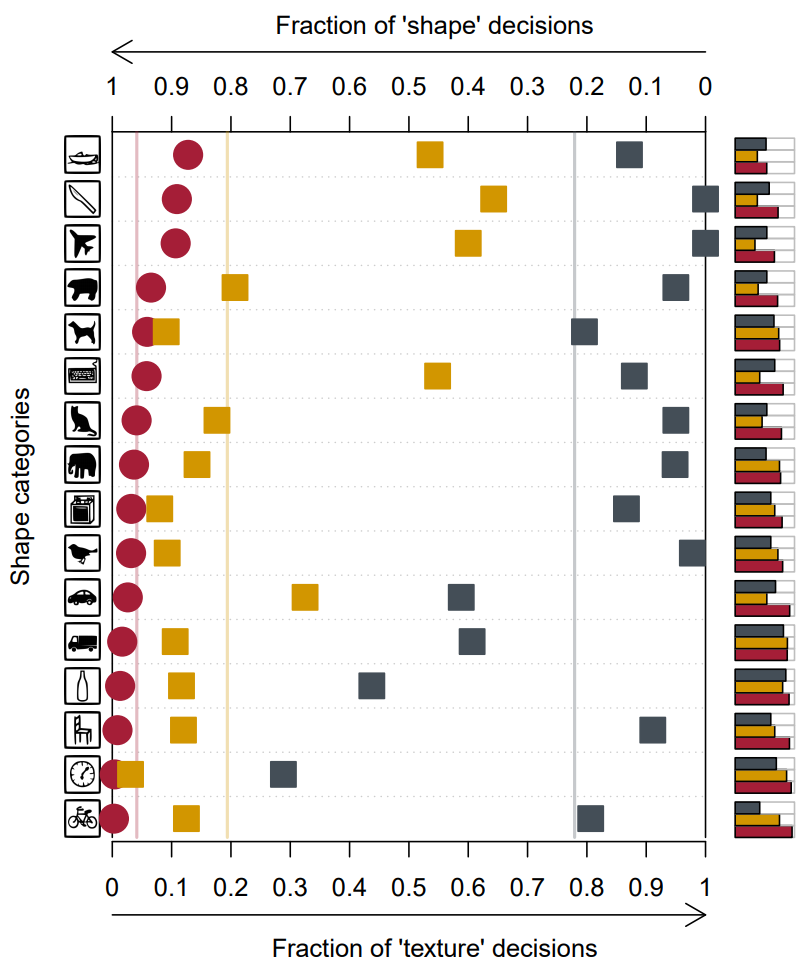
위 그림에서 주황색 사각형은 SIN으로 학습된 ResNet-50이다.
앞서 실험과 다르게, SIN으로 학습시킨 모델은 Texture보다 Shape에 의존해 결정을 내렸고, 이는 Texture hypothesis가 옳음을 뒷받침한다.
Shape-Biased 모델의 장점
앞서 실험으로 현재 CNN들은 Texture를 이용해 결정을 내림을 밝혔고, 이를 Shape-biased하게 만드는 방법도 알아냈다. 하지만, 사람이 Shape를 이용해 판단한다고 이를 모방하는게 실제로 성능 개선에 도움이 될까? 논문에서는 이를 위해 IN과 SIN을 함께 학습시킨 모델의 성능을 측정했다.

결과를 보면 Classification과 Detection에서 모두 성능 향상이 있었다. 특히 Detection에서 향상이 컸는데, 이는 Detection에서는 객체를 포함하는 정답 사각 좌표들은 물체의 모양에 의해 할당되므로 Shape-based representation이 중요할 것이라는 직관과 일치한다.
이 외에도, 왜곡을 추가한 데이터셋에서 Shape-biased 모델의 성능을 측정했다.

위 결과를 보면 (d)를 제외하면 모든 면에서 기존 모델보다 왜곡에 잘 견딘다. (d)의 경우가 성능이 낮은 이유도 생각해보면, 날카로운 선들을 뭉게는 Blurring이라 Shape 정보를 없애고 이 정보가 없을때 기존 Texture-biased 모델들이 더 우세한 것은 당연하므로 이해가 가는 부분이다.
결론
결론적으로 이 논문은 기존 CNN 모델들이 Texture보다 Shape를 이용한다는 통념을 반박했고, 이러한 Texture-biased되는 경향이 ImageNet 데이터셋의 문제임을 밝히며 이를 해결할 수 있는 SIN을 제시했다. 논문이 이야기하는 주제가 흥미로워서 상당히 잘 읽힌 논문인데, 간단히 왜곡에 강건함을 추가하면서 약간의 성능향상을 기대할 수 있는 새로운 Augmentation의 등장으로 볼 수도 있을것 같다.
논문을 보면서 흥미로웠던 것 중 하나는 ResNet과 VGGnet이 AlexNet과 GoogleNet보다 훨씬 Texture biased 하다는 것이다. 이는 Conv filter 사이즈의 크기가 Shape biased와 관련있기 때문이으로 보이는데, 단순히 Filter 사이즈가 커서 더 큰 범위의 Texture를 인식했고, 큰 크기의 Texture는 Shape와 동일하므로 이런 결과가 나온 걸까 아니면 뭔가 다른 이유가 있을까? ICLR 2019에 억셉된 논문인데, 후속 연구가 기대된다.

Leave a comment