관련 링크 : https://arxiv.org/abs/2006.06882
컴퓨터 비전에서 ImageNet pre-training을 이용하는것은 흔한 일이고, 꽤 좋은 성능을 보여왔다. 하지만 최근에 이를 이용했더니 오히려 COCO object detection에서는 성능이 떨어지는 현상을 발견했다. 따라서 본 논문은 pre-training이 특정 경우에 성능이 떨어지고, 대부분의 경우에 self-training이 효과가 좋음을 보인다. 본 논문에서 얻을수 있는 통찰은 다음과 같다.
- 풀고자 하는 문제를 위한 많은 labeled data가 있고, 강한 data augmentation을 이용하면 pre-training의 성능이 떨어진다.
- Pre-training과 달리 Self-training은 강한 data augmentation을 사용하는게 유용하다.
- Pre-training이 성능을 향상시키는 경우라면, Self-training은 그 이상의 성능향상을 가져온다.
논문에서는 위 통찰들을 검증하기위해 두 가지를 통제변인으로 설정해서 실험을 수행했다. 첫 번째 통제변인은 Data Augmentation의 강도로, Augment-S1, S2, S3, S4로 이름 붙였다. 각각은 FilpCrop, AutoAugment, AutoAugment with higher scale jittering, RandAugment with higer jittering으로 S4가 가장 강하다. 두 번째 통제변인은 pre-training 모델의 종류로, Rand, ImageNet, ImageNet++ Init으로 이름 붙였다. 사용된 네트워크는 EfficientNet-B7으로, ImageNet(84.5% top-1)은 AutoAugment만 적용해 학습시켰고 ImageNet++(86.9% top-1)는 Noisy Student로 학습시켰다.
Pre-training을 이용했을때 성능과 비교할 Self-training 모델의 학습 방법은 Noisy Student로, Teacher는 COCO로 학습시키고 Student에는 COCO와 ImageNet을 모두 사용해 학습시켰다. 그럼 실험 부분을 보자.
Augmentation과 Labeled 데이터셋 크기의 영향
먼저 Pre-training의 경우부터 살펴보자.

- Augment-S2부터 Rand Init의 성능이 우세하므로, 강도가 강하면 pre-traning의 성능이 떨어진다.
- COCO 데이터셋의 50%부터 Rand Init의 성능이 더 좋아지므로, Labeled 데이터셋이 많을수록 pre-training이 좋지 않음을 알 수 있다.
다음으로 Self-training의 경우를 살펴보자.

- Pre-training과 달리 강도에 상관없이 Rand Init보다 성능이 좋다.

- Self-training은 모든 경우에 Rand Init보다 성능이 좋다.
모든 실험 결과들은 COCO Obejct Detection에서의 성능이다
그런데 왜 이런 결과가 나오는걸까? 간단히 생각해 볼 수 있는 이유는 ImageNet pre-training은 classification으로 학습되었으므로, task mismatch가 생기기 때문일 수 있다. 따라서 본 논문에서는 일반화된 representation을 얻기 위한 Self-Supervised pre-training 네트워크도 이용해 보았다.
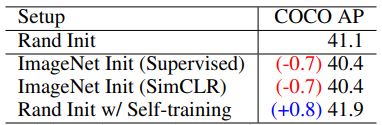
- 가장 뛰어난 성능을 보인 SSL 방식인 SimCLR의 경우도 Supervised method처럼 성능 하락이 발생했다.
결과적으로, 어떤 종류의 pre-training 모델을 사용하는 것 보다 self-training이 효과가 더 좋았다.
Self-Training이 왜 효과적일까?
위 결과로 보듯 Self-Training이 모든 경우에 더 뛰어났다. 이는 Self-Training의 경우 풀고자 하는 task로 학습된 Teacher가 만든 pseudo-label을 이용해 Student를 학습시키므로, Student는 Teacher와 task mismatch가 없기 때문이다. 이는 기존 Pre-Training과의 가장 큰 차이이고, Self-Supervised Pre-Training 역시 동일 한계를 가지고 있다. 그럼 이를 줄이면 성능이 개선되지 않을까? 논문에서는 ImageNet Classification과 COCO Detection을 함께 학습시켜서 이를 줄여보고자 했다.

Sup. Training을 제외한 나머지 방법들은 추가 데이터로 ImageNet을 이용했고, Augment-S4를 적용한 COCO의 20%만 이용했다.
- Rand Init과 ImageNet Init의 Sup. Training의 차이는 2.6%이지만, Rand Init의 Joing Training은 2.9%의 성능 향상을 가져왔다.
Joint Training의 설명이 부족하지만, Joint는 COCO 데이터셋으로는 Detection을 학습하면서 동시에 ImageNet 데이터셋에서는 Classfication을 학습하는 것으로 보인다. Self-Training에 적용하면, Student를 학습시킬때 Joint하게 학습하는 것을 뜻하는 것 같다. 하지만, ImageNet Classficiation 학습을 위해 Label을 사용한다면, Noisy Student의 장점인 Unlabeled 데이터셋을 이용한다는 점이 사라진다. 현재 비교하는 대상이 Pre-training이고, 이를 학습할때 Label이 필요하므로 공정한 비교를 위해 사용한 것일까?
예상대로, Joint로 task mismatch를 줄이는 것이 성능 향상의 해답이었다. 하지만, 항상 그럴까? 논문에서 참조한 다른 논문에 따르면 Detection을 위해 만들어진 Open Image 데이터셋으로 학습한 모델도 COCO로 transfer할 경우 성능이 저하됐다. 이는 task mismatch가 없지만, Detection에 사용된 annotation의 종류만 달라진 경우다. 이를 통해, pre-training이 데이터가 많고 augmentation이 강한 환경에서 효과를 보려면 task mismatch도 없으면서 사용된 annotation들도 같아야함을 알 수 있는데, Self-Training은 pseudo-label을 사용해 이런 문제가 발생하지 않아 성능이 향상되었다.
결론
결과적으로, Pre-training은 Self-Training보다 좋은점이 없어보인다. 하지만 Self-Trainng이 Pre-training을 완전히 대체할 수는 없는데, 이는 다음의 이유들 때문이다.
- Self-Training은 Pre-Training보다 최소 1.3배에서 최대 8배까지의 추가 연산을 필요로 한다.
- 풀고자하는 문제에 데이터셋이 충분하지 않을때 두 방법의 성능이 비슷하다.
하지만, 데이터셋이 충분한 경우에는 Self-Training은 최신 모델에서도 적용가능하고, 어떤 문제에도 적용할 수 있다는 장점이 있다.

Leave a comment