관련 링크 : https://arxiv.org/abs/1805.09501
- NAS와 동일한 방식으로 유용한 Data Augmentation을 찾는 과정을 제안
Intro
AlexNet이 획기적인 성능 향상을 불러내면서 딥 러닝에 대한 관심이 집중 되었을 때, 사람들은 ReLU와 ConvNet을 이용한 AlexNet 모델 구조에 집중했다. 이 후 연구 방향도 새로운 모델이 더 나은 성능을 보였기 때문에, 연구진들은 유용한 Inductive Bias를 주는 모델을 찾기 위해 노력했고, 이는 VGG와 Inception, ResNet, 그리고 DenseNet 등의 결과물을 내놓았다. 하지만 이는 너무 소모적인 일이었고, 이를 개선하고자 Neural Architecture Search가 등장해 AutoML의 시대를 열었지만, 이 역시도 더 좋은 모델을 효율적으로 찾는 방법이었다. 하지만, 유용한 Inductive Bias는 모델을 통해서만 얻을 수 있는게 아니다.
ConvNet을 떠올려보자. ConvNet이 왜 잘 되는가에는 여러 의견이 있지만, 지역 정보를 사용한다는 Locality와 각 지역 정보를 뽑아내기 위한 커널들이 동일한 가중치를 가지는 Parameter Sharing이 중요한 역할은 한다는데는 대부분 동의할 것이다. 이 두 가지는 ConvNet이 유용한 Inductive Bias인 Translation Invariance를 가지도록 한다. 그런데, 사실 이는 Data Augmentation(DA)으로도 만들 수 있다.
Translation Invariance는 간단히 말해서 이미지 안에 위치에 상관없이 동일한 패턴을 보인다면 최종 출력 값이 같음을 의미한다. 그런데, DA에서 패턴의 위치를 바꾸거나 크기를 줄이거나 늘리는 등의 Gemetric Transform들은 학습할 때 모두 동일한 라벨을 가진다. 따라서, 모델은 이미지안의 동일한 패턴들이 위치에 상관없이 존재한다면 동일하다고 말할 수 있다. 즉, MLP에서도 DA만 잘 주면 이런 Translation Invariance를 가지게 할 수 있다.
결과적으로, 새로운 모델을 찾는 방법은 모델이 커지거나 연산량이 늘어나거나 하는 부작용이 따라올 수 있지만, 새로운 DA를 찾는 것은 이런 부작용 없이 유용한 Inductive Bias를 줄 수 있다. 하지만 특정 도메인과 데이터, 모델에 유효한 DA를 찾는 것은 새로운 모델을 찾는 것 만큼이나 소모적인 일이다. MNIST와 CIFAR만 비교해봐도 효과적인 DA가 다르기 때문이다. 따라서, 논문의 저자들은 NAS에서 사용하던 방식을 그대로 DA에 적용해 데이터셋에 적합한 Augmentation을 찾는 AutoAugment를 제안한다.
AutoAugment
NAS 방식의 구성 요소는 Search Space와 Search Algorithm이다. 초기 NAS는 RNN Controller가 찾은 모델과 그 모델의 Validation 성능 사이의 미분 불가능한 관계를 REINFORCE 알고리즘을 이용, Policy Gradient 방식으로 Controller를 학습시켰다. 하지만 이는 연산량을 너무 많이 요구해 이후 연구들은 이를 개선하기 위해 여러 시도를 거쳤고, AutoAugment에서는 다음 연구의 Search Algorithm을 이용한다. 저자들이 구현상 편리함을 위해 사용했고 다른걸 사용해도 상관없다고 했으므로 자세히 설명하지는 않겠지만 기본적으로 초기 NAS와 비슷한 방식이다.
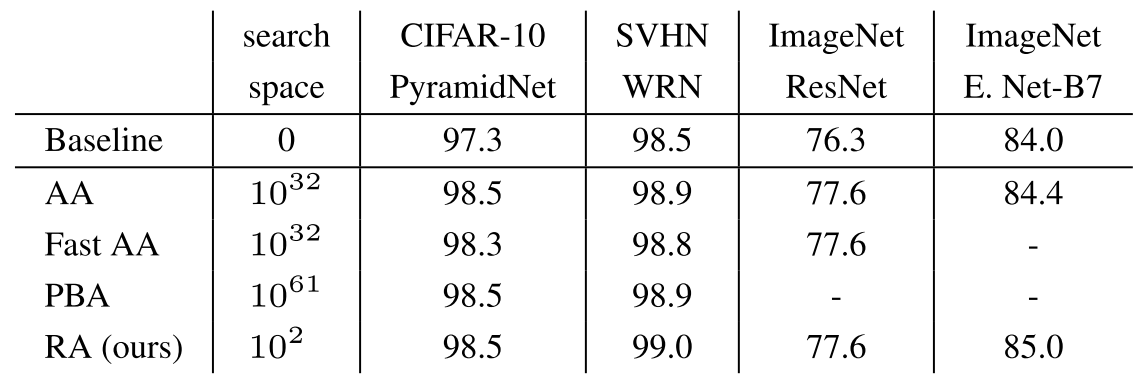
Search Space는 찾아야하는 파라미터들의 가능한 모든 경우의 수를 의미한다. NAS에서 층 수를 2, 층의 종류를 3이라고 설정했다면 가능한 경우의 수는 $2\times 3=6$이 된다. 저자들은 AutoAugment의 구성 요소로 Image Processing Operation의 종류, Operation의 적용 확률, Operation의 적용 정도로 정했다. Operation의 종류는 16개, 적용 확률은 이산적으로 나누어 10단계, 적용 정도는 11단계로 나누었다.
저자들은 두 개의 Operation을 연속적으로 적용하는 것을 Subpolicy라 정의하고, 다섯 개의 Subpolicy를 Policy라 정의했다. 따라서 하나의 Policy의 Search Space는 $(16\times 10 \times 11)^{2\times 5}\approx 2.9\times 10^{32}$이고, RNN Controller는 총 열 개의 Operation을 찾고, 한 Operation당 종류, 확률, 정도로 세 개이므로 총 서른 개의 값을 내뱉는다.
16개는 ShearX(Y), TranslateX(Y), Rotate, AutoContrast, Invert, Equalize, Solarize, Posterize, Contrast, Color, Brightness, Sharpness, Cutout, Sample Paring이다. 자세한 설명은 논문의 Appendix를 참조

요약하면, 고정된 Child Network를 RNN Controller가 내뱉는 Policy를 적용한 데이터로 학습시키고 이때의 Validation 성능으로 Controller를 학습시킨다.
RNN Controller를 학습시키기 위한 Child Network를 학습시킬 때, Policy에 있는 다섯 개의 Subpolicy 중 하나를 무작위로 적용시킨다. AutoAugment의 성능을 평가할 때는 Controller가 내놓은 Policy중 가장 성능이 좋은 5개를 하나로 합쳐 스물 다섯 개의 Subpolicy를 가진 Policy를 만들어 적용한다. Policy안의 Subpolicy는 동일 확률로 하나가 선택되므로 학습에서 Subpolicy의 수에 따라 학습 시간을 늘려주어야 하는 점을 주의해야 한다.
그런데, 위 과정을 일반적으로 NAS에서 사용하는 CIFAR에 그대로 적용하면 어마어마한 연산량을 요구한다. NAS에서 모델의 Search Space는 $6\times 10^{16}$이다. 하지만 위에서 말했듯 AutoAugment는 이것보다 대략 $10^{16}$배 더 많은 Search Space를 가진다. 그래서 저자들은 전체 데이터셋을 그대로 이용하지 않고, 두 가지 방식으로 AutoAugment의 실효성을 입증했다. 하나는 AutoAugment-direct이고, 다른 하나는 AutoAugment-transfer이다.
AutoAugment-direct
데이터셋을 그대로 사용하지 않고, 무작위 추출로 작은 데이터셋을 구성한 후 이를 이용해 Augmentation을 찾는 방식이다. Baseline으로는 Standardization/Flips/Zero Padding and Crop + Cutout을 두고 여러 데이터셋에서 검증한다.
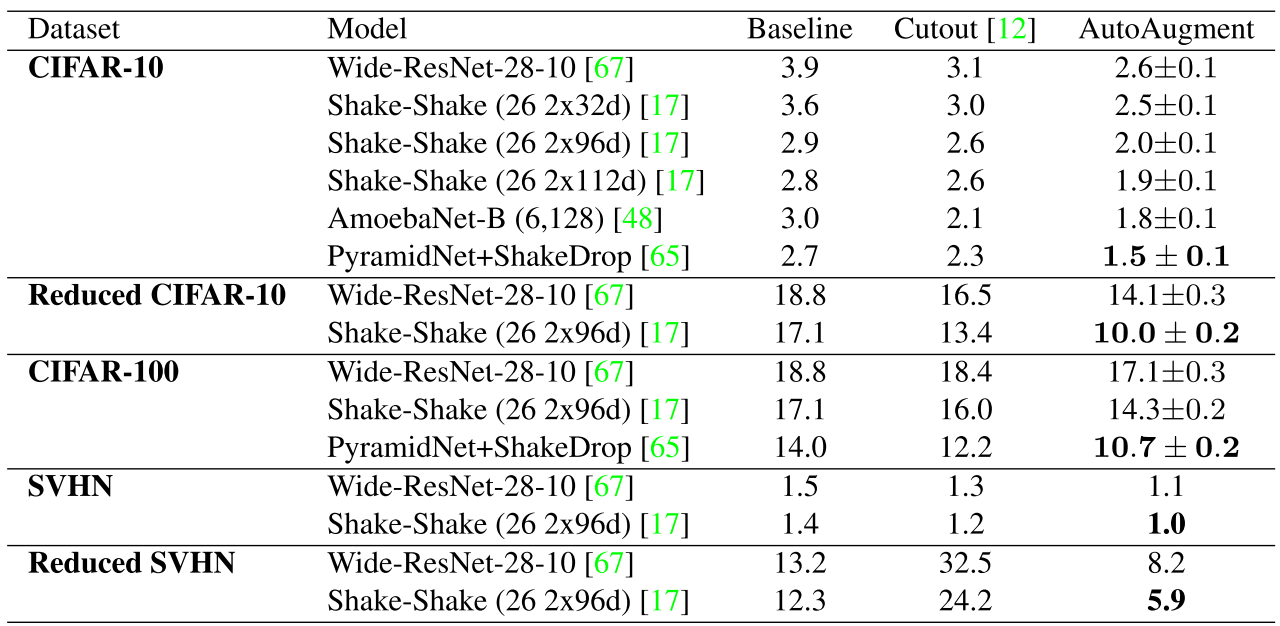
AutoAugment는 Reduced 데이터셋에서 찾고, 이를 전체 데이터셋에서 성능 확인한다
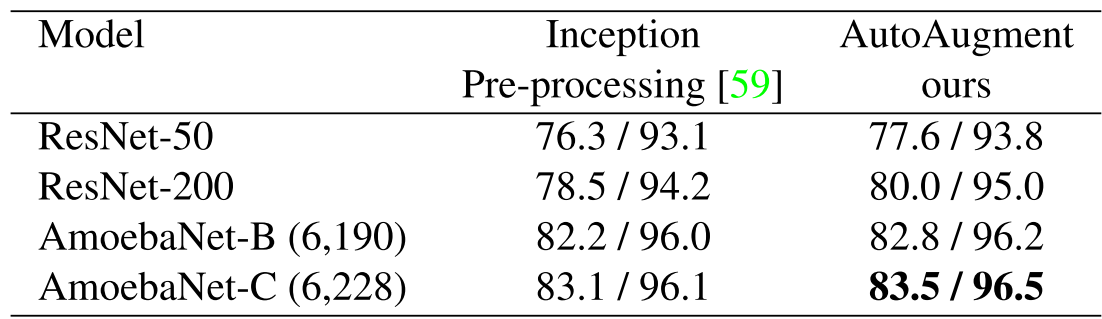
ImageNet역시 Reduced 버전에서 AutoAugment를 찾았다. 왼쪽은 Top-1, 오른쪽은 Top-5
재미있는 점은 숫자가 두드러지는 SVHN과 이미지들이 주를 이루는 CIFAR과 ImageNet에서 선택된 Operation들이 다르다는 것이다. 이는 AutoAugment가 도메인 지식이 없음에도 이에 적절한 Operation들을 찾음을 말해준다.
AutoAugment-transfer
위 실험을 통해서 AutoAugment가 확실히 효과가 있다는 것은 보였다. 하지만 비슷한 도메인의 데이터셋에서 위 DA들이 효과가 없다면, 위에서 찾은 DA들은 특정 데이터에 Overfit되었다고 볼 수 있다. 따라서 저자들은 비슷한 도메인의 데이터셋들에서 위에서 찾은 DA들이 유의미한 효과를 나타내는지 확인했다.
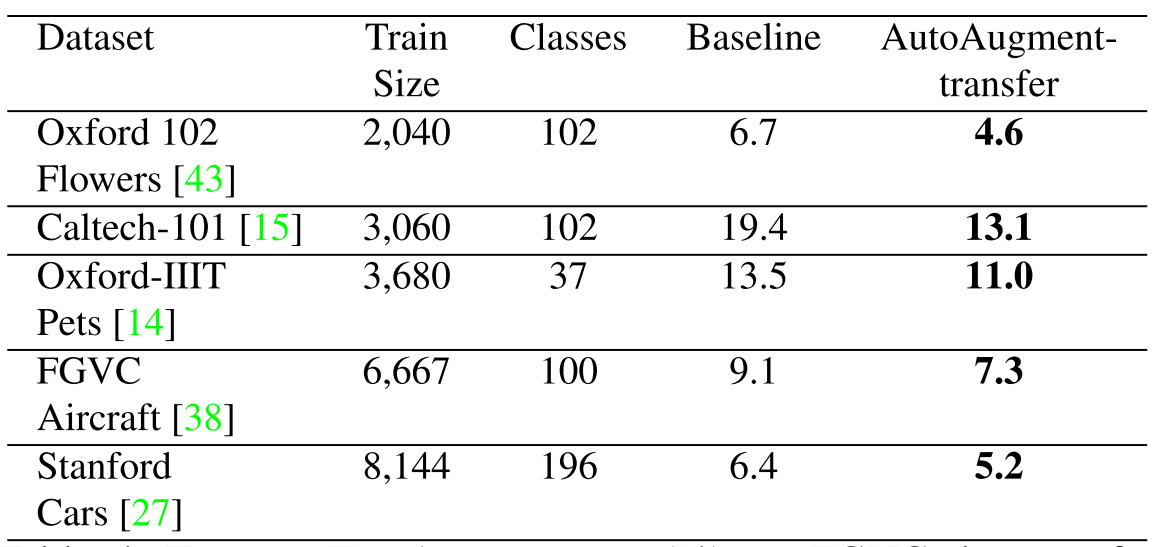
위 결과대로 Reduced ImageNet에서 찾은 DA들이 Reduced ImageNet과 비슷한 도메인의 데이터셋에서 성능 향상을 가져왔다. 심지어 Stanford Cars는 이전 SOTA가 ImageNet Pretrained 모델을 Transfer 사용한 방법(5.9%)이었는데, Pretrained 모델을 사용하지 않았음에도 더 높은 성능을 보이며 SOTA를 달성했다. 위 표에는 나타나지 않지만 알아야할 점은 CIFAR에서 찾은 AutoAug를 SVHN에 적용했을 때 성능 하락이 잃어나지 않았다는 점이다. 위 결과들을 종합해 봤을 때 특정 도메인에 적절한 DA들을 찾지만 Overfit되지 않았음을 알 수 있다.
Abalation Studies
위의 결과들 외에도 저자들은 여러가지를 실험했다. 위 실험에서는 Subpolicy의 개수를 다섯 개로 고정했고, 최종 Policy에 Subpolicy의 개수는 스물 다섯 개였다. 이를 늘리면 어떨까? 즉, 하나의 Policy에 더 다양한 Subpolicy가 있다면 어떨까에 관한 실험이다.
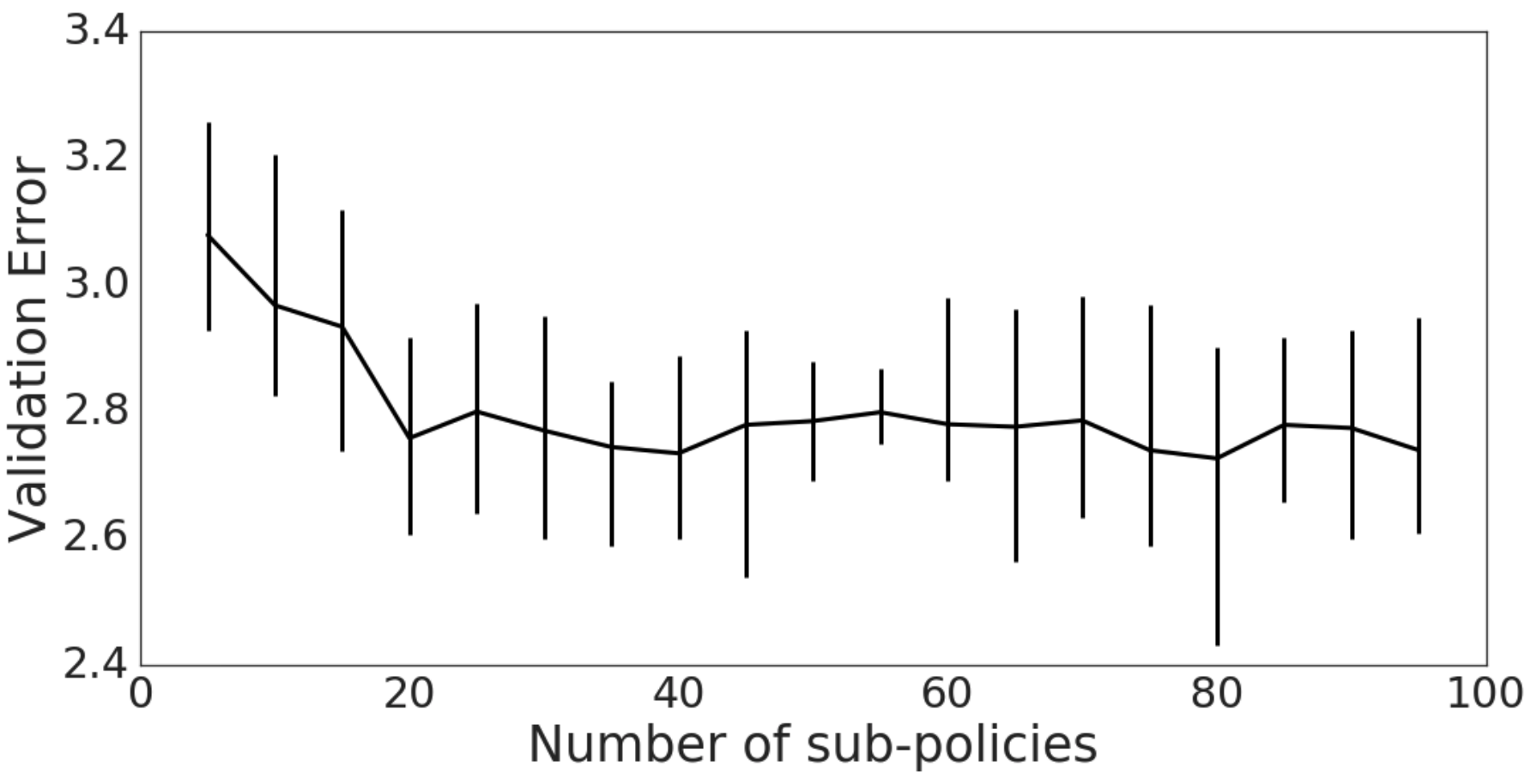
결과는 위와 같다. 스무 개의 Subpolicy까지는 성능이 증가하다가 이후 거의 고정됨을 볼 수 있다. 논문에는 별 다른 의견이 없지만, Operations들의 종류가 늘어난다면 아마 이것도 바뀌지 않을까?
또 다른 실험은 동일한 Search Space에서 완전히 무작위로 DA들을 찾았을 때, AutoAug와의 성능 비교 실험이다. 하나는 Operations은 찾고 적용 확률과 정도만 무작위로 비교했고, 다른 하나는 Operations까지 무작위로 비교했다. 결과적으로, 두 경우 모두 Baseline보다는 뛰어났다는데 두 경우의 성능차이는 미미$(0.1\%)$했지만, 두 경우와 AutoAug와의 성능 차이는 $0.4\%$로 상당했다. 즉, 적용 확률과 적용 정도가 상당히 중요함을 알 수 있다.
Remarks
RandAugment 논문을 읽기 전에 관련 연구가 어떻게 시작되었는지를 알고 싶어서 읽게 되었다. NAS의 방법론을 DA에 가장 단순하게 적용한 논문이 아닐까 싶다. 그래서 그런지 연산량이 어마무시하고, RandAugment에서 지적하듯 Reduced Dataset에서 찾은 DA들이 Whole Dataset에서 유효할 거라는 너무 직관정인 가정을 가지고 실험했다는 단점을 가지고 있지만, 이후 연구들의 기준점을 제시한 좋은 연구라고 생각한다.

Leave a comment