관련 링크 : https://arxiv.org/abs/2101.11986
- Vision에 적합하게 토큰 수를 줄여 차원을 늘리는 T2T 모듈을 제안
- CNN에서 효과적인 여러 모델 구조가 Vision Transformer에서도 유효하다는 가능성을 보임
Intro
ViT가 처음으로 Transformer로만 이루어진 모델이 Vision에도 효과적임을 보였다. 하지만, 파라미터 수가 비슷한 CNN 계열에 비해 성능이 좋지 않았고, 비슷하거나 좋은 성능을 내기 위해서는 더 많은 데이터를 요구했다. 저자들은 이를 NLP와 Vision의 차이를 충분히 고려하지 않은 ViT의 두 가지 문제점 때문이라고 생각했다.
첫 번째는 ViT가 Edge나 Line 같은 Local Structure를 잘 포착하지 못한다는 점이고, 두 번째는 ViT는 CNN 모델들과 달리 파라미터를 효과적으로 활용하지 못해 불필요한 Feature를 너무 많이 만든다는 점이다. ViT는 이미지를 $14\times 14$ 혹은 $16 \times 16$의 패치로 나누고, 모든 층에서 패치들 간의 Global Relation을 모델링 한다. 따라서 모든 층이 Global Relation에 치중되므로 유사한 Feature들이 너무 많이 생성되면서 Local Relation을 표현하는 Feature들은 적다. 이는 CNN이 낮은 층에서 Local Structure를 포착하고 깊은 층에서는 좀더 Global한 Texture, Object 같은 Feature를 포착하는 것과는 다르다. 이 문제는 저자들이 한 예비실험 결과를 보면 더 잘 나타난다.

초록색 상자는 Edge나 Line 같은 Low-level Structure를 강조한 것이고, 빨간색 상자는 불필요한 Feature들을 강조했다. ViT는 CNN과 달리 모든 층에서 Global 한 형태를 거의 유지하고 있으며, Edge와 Line이 두드러진 Feature들이 거의 없는 것을 알 수 있다. 저자들이 제안한 T2T-ViT는 앞선 문제들이 어느정도 개선되었다.
따라서 저자들은 Vision에 맞게 Local Structure를 어느정도 포착할 수 있도록 패치를 재구성하는 T2T 모듈과 CNN에서 효과적이었던 방법들을 Transformer에 가져와서 실험 한 후, 가장 좋았던 Deep-narrow Backbone을 이용해 최종적으로 T2T-ViT를 제안한다.
T2T-ViT
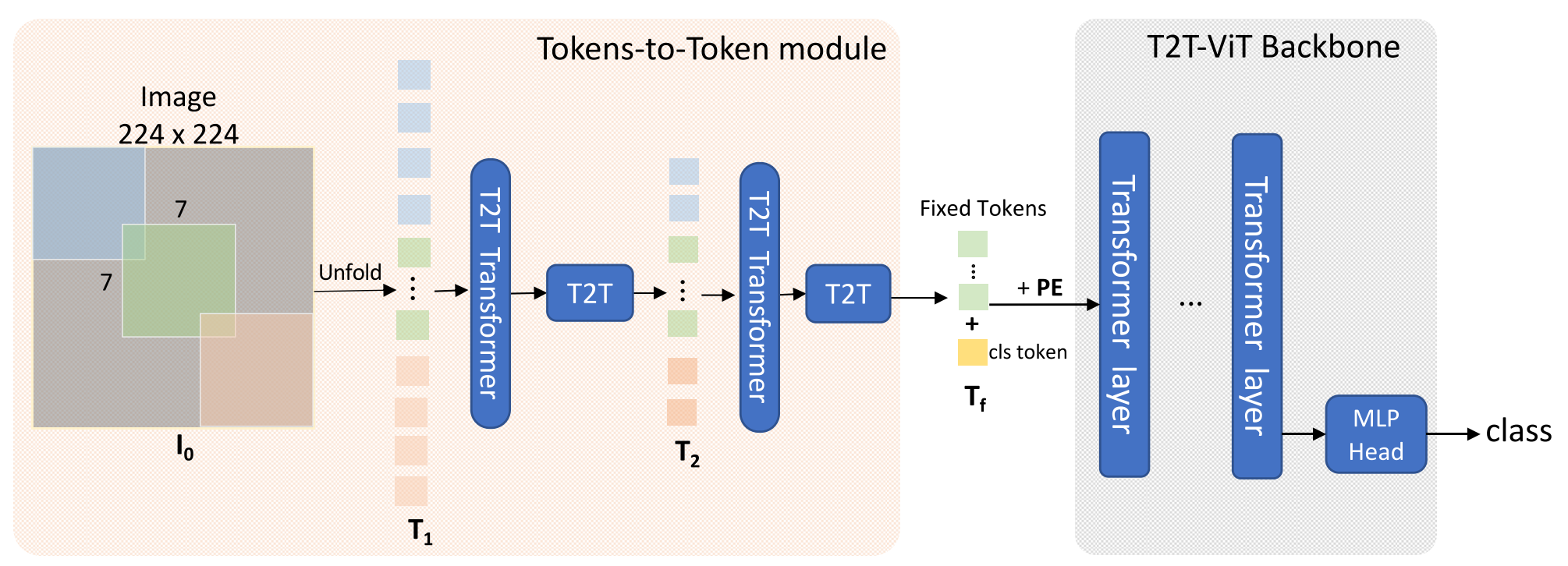
Tokens-to-Tokens(T2T) Module
T2T 모듈은 패치 단위로 나뉘어진 토큰들을 다시 이미지 형태로 합쳐주는 Re-structurization과 이렇게 합친 이미지를 Local Structure를 잘 포착하도록 다시 패치로 나눠주는 Soft Split으로 이루어져 있다.
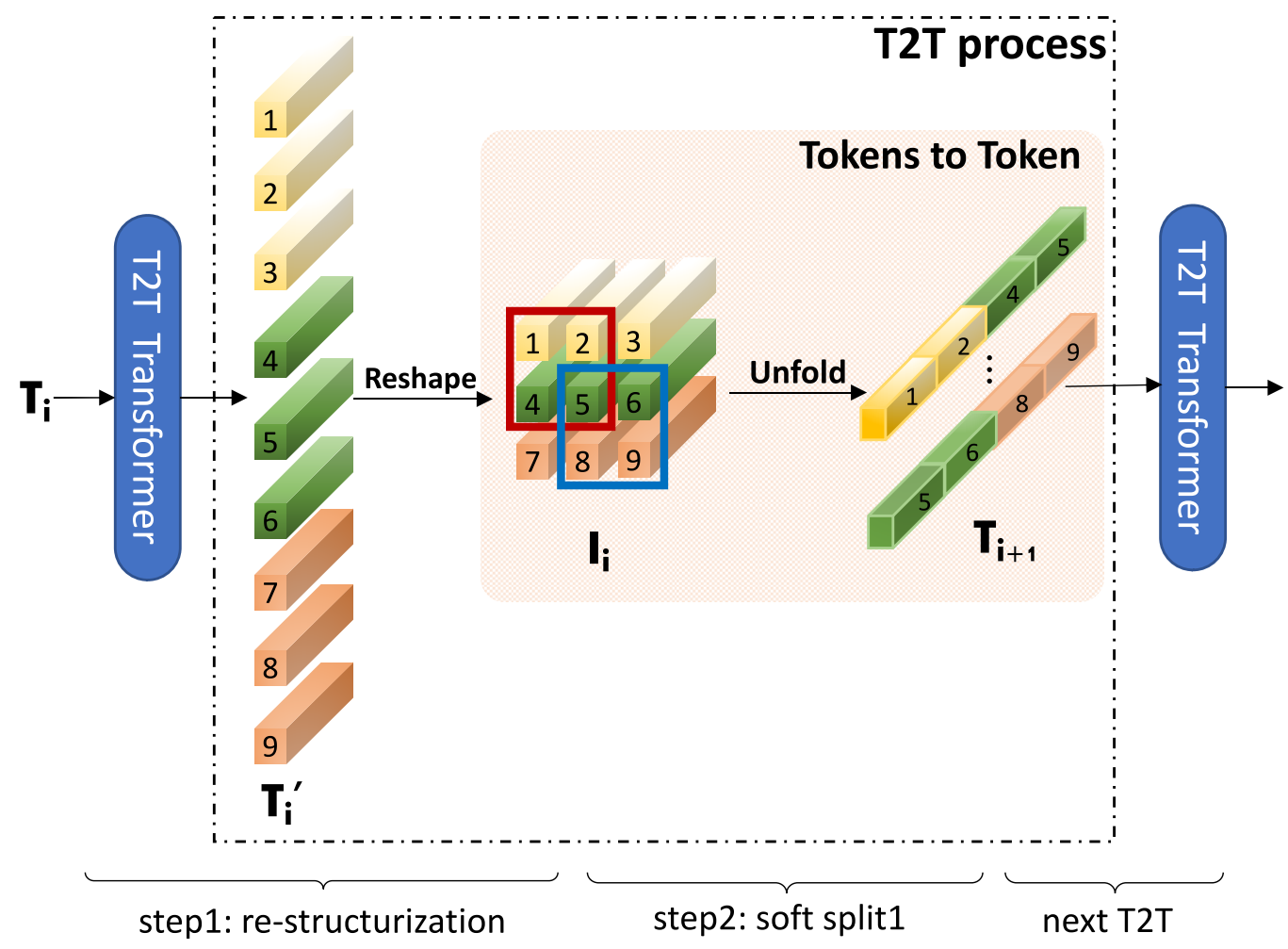
Re-structurization: $\mathsf{T_i}\in \mathbb R^{l\times c}$를 받아서 T2T Transformer에 넣어 $\mathsf {T_i}’$를 얻고, 이미지 $\mathsf{I_i}\in \mathbb R^{h\times w\times c}$로 Reshape한다.
- T2T Transformer는 연산량을 줄이기 위해 Performer를 사용, 아래첨자 $t$가 붙은 모델이 ViT의 Transformer를 이용한 것
Soft Split: $\mathsf {I_i}$를 패치 사이즈 $k$, 패딩 사이즈 $p$, 중복 사이즈 $s$를 이용해 $\mathsf{T_{i+1}}\in \mathbb R^{l_o\times ck^2}$로 Unfold한다.
\[l_o = \left\lfloor \frac{h+2p-k}{k-s}+1\right\rfloor \times \left\lfloor \frac{w+2p-k}{k-s}+1\right\rfloor\]
- 이후 실험에서는 T2T 모듈을 3개 사용하는데, 이때 $p=[7, 3, 3]$, $s=[3, 1, 1]$을 이용한다. 첫 번째 모듈에서 토큰 수가 너무 많으므로, 패치의 임베딩 차원을 32 혹은 64로 대폭 줄인다.
Deep Narrow Backbone
저자들은 T2T 모듈과 함께, Redundancy를 줄일 수 있는 방법을 고심했고, CNN에서 효과적이었던 여러 구조들을 가져와 비교했다. 비교한 방식들은 아래와 같다.
-
DenseNet에서 가져온 Transformer Layer간의 Dense Connection
DenseNet처럼 Transformer Layer로 이루어진 Block을 구성하고, Block간 Dense Connection 구성
-
Wide-ResNets에서 가져온 Deep-narrow vs. Shallow-wide
Hidden 384, depth 16 vs. Hidden 1024, depth 4
-
SENet에서 가져온 각 패치 채널에 대한 SE 모듈
각 패치의 채널에 사용된 SE 모듈은 패치 하나의 Spatial Local Attention 효과를 준다.
-
ResNeXt에서 영감받은 MSA의 헤드 개수 증가
헤드 개수를 8개에서 32개로 늘려 줌
-
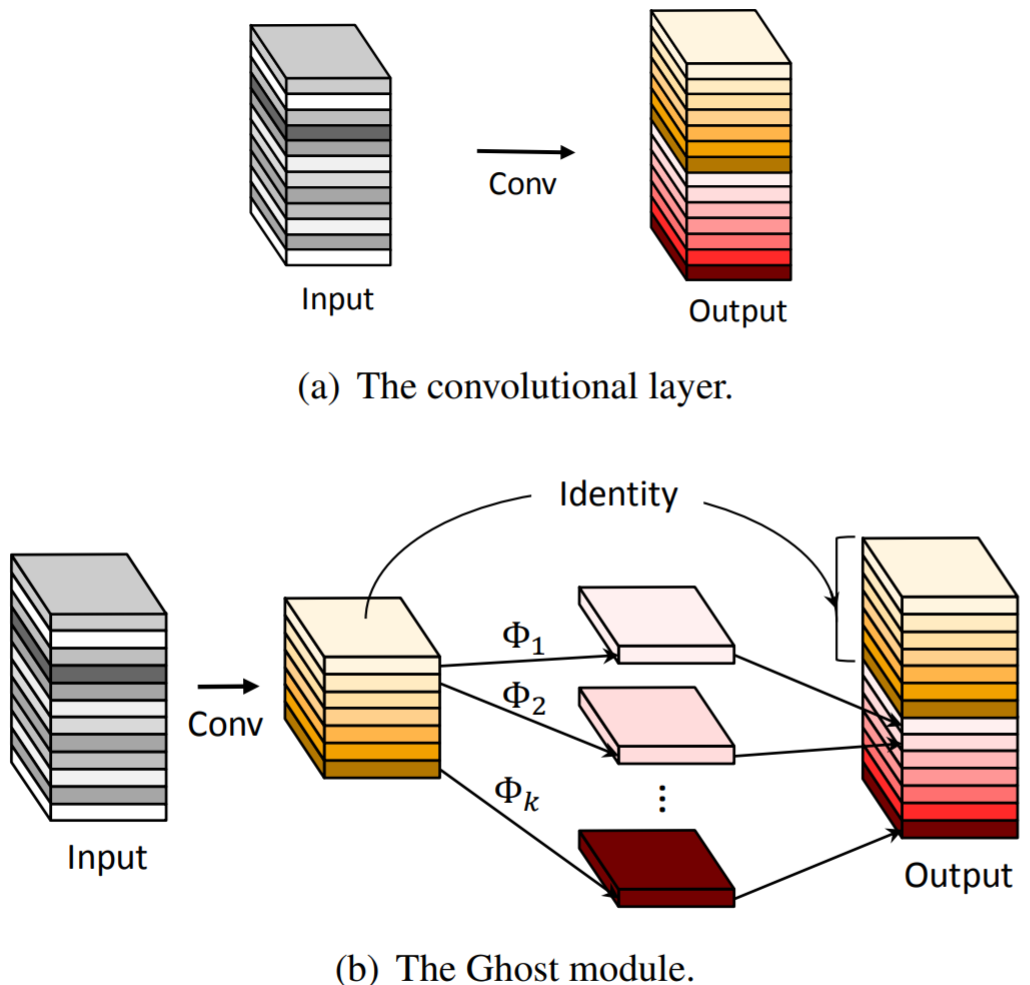
GhostNet에서 가져온 MSA와 FFN에서의 Ghost Operation
아래 그림의 $\Phi$는 Cheap Operation을 뜻 하는데, 기존 Conv보다 작은 Conv를 이용하고, 작은 Conv의 결과에 훨씬 적은 연산량을 요구하는 Cheap Operation을 취해 이를 합쳐 기존과 동일한 크기의 Output을 얻으면서 연산량을 줄이는 방식이다. 성능 감소는 거의 없으면서 연산량을 줄일 수 있다. T2T-ViT에서는 MSA와 FFN의 Linear 연산에 Ghost Operation을 사용했다.
최종적으로 Deep-narrow가 효과가 가장 좋았고, SE 모듈도 약간 효과적이었다. 이는 CNN에서 효과적인 방식이 ViT 계열에도 좋을 수 있음을 시사한다. 위 방식들 간의 성능 비교 결과는 다음과 같다.
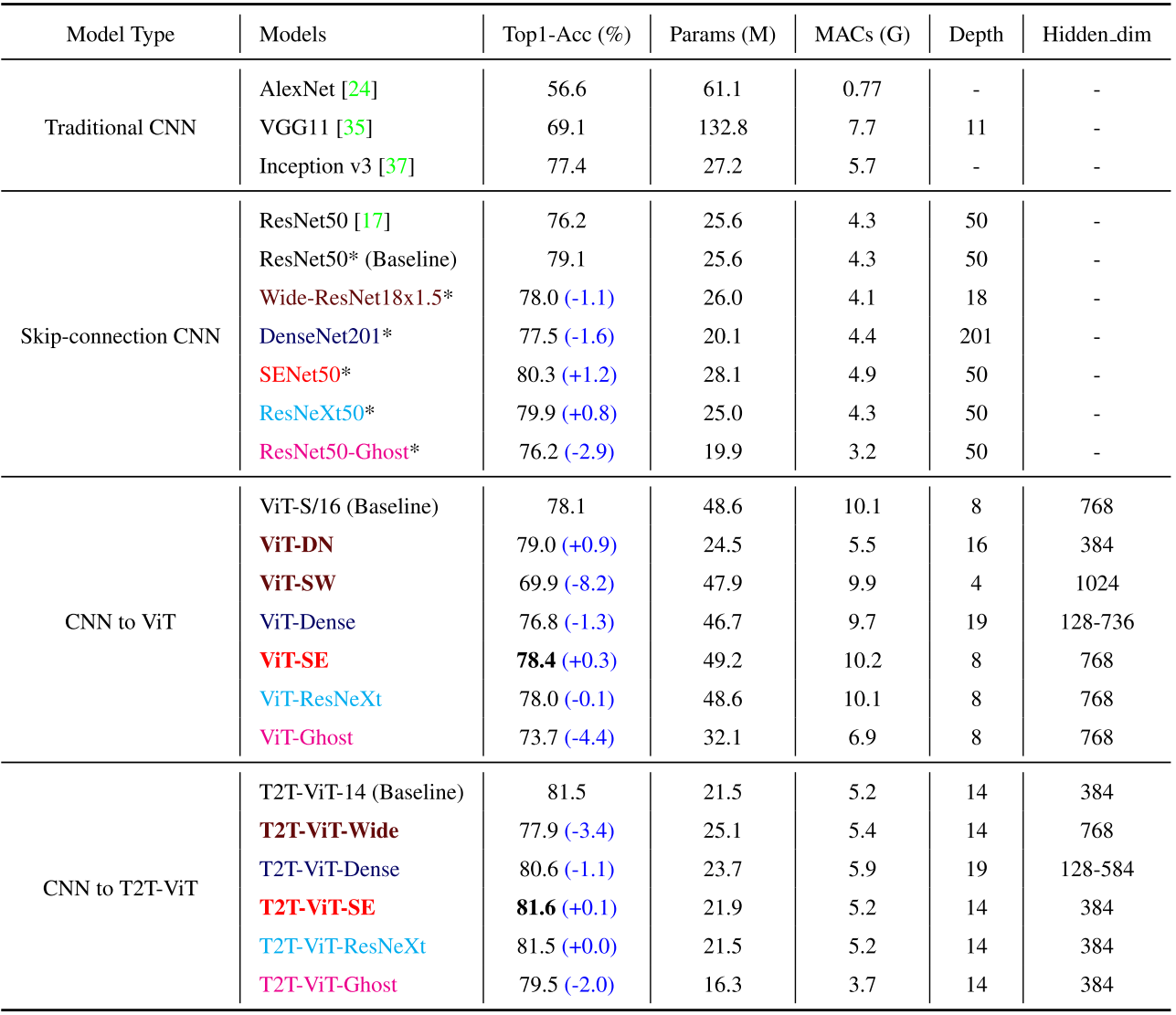
$*$가 표시된 모델들은 저자들이 동일한 학습 스케쥴을 이용해 새로 학습시킨 것이다.
T2T 모듈이나 Deep Narrow가 아니라면?
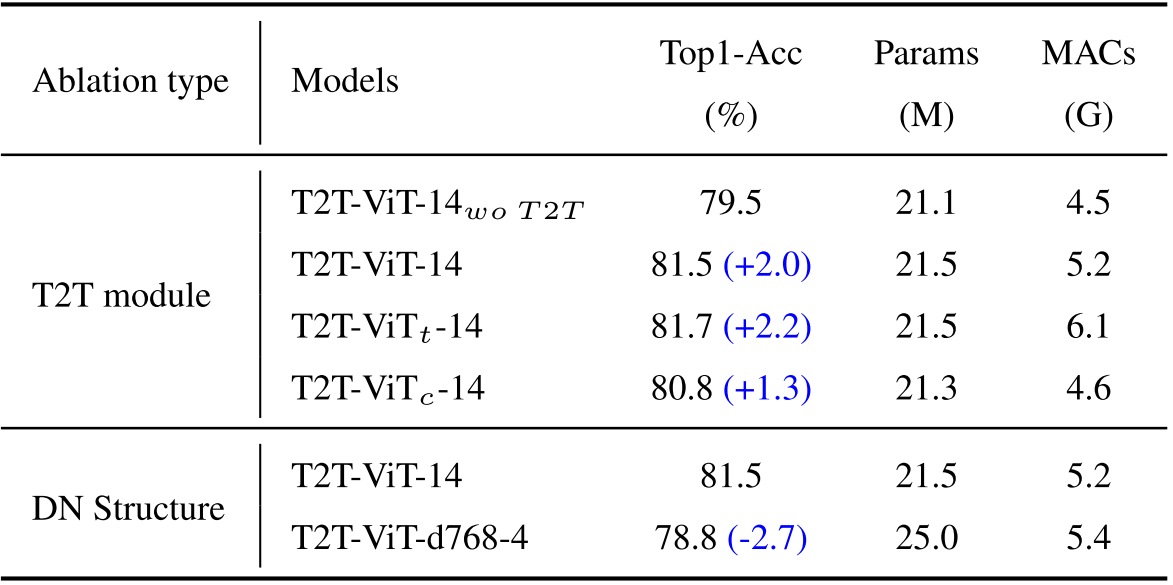
위 실험은 저자들이 제안한 T2T 모듈과 Deep Narrow Backbone이 효과가 있음을 보여준다. T2T 모듈에 관한 실험을 먼저 보자. 앞서 언급했듯이 $\text{T2T-ViT}_t \text{-14}$는 Performer를 사용하지 않은 모델이다. $\text{T2T-ViT}_c \text{-14}$는 T2T모듈을 Conv로 대체한 모델로, T2T모듈을 사용했을 때 보다 성능이 낮다. 저자들은 T2T 모듈을 Global Relation과 Local Structure를 동시에 모델링하는 반면 Conv는 Local Structure를 모델링하는데 특화되 있어서 성능차이가 난다고 말한다.
두 번째 DN Structure는 앞서 CNN to T2T-ViT에서 실시한 것과 유사하지만 약간 다르게 Deep Narrow와 Shallow Wide를 비교한 실험이다. 앞서 Deep Wide가 Deep Narrow에 비해 성능이 낮았던 것과 동일하게, 연산량과 파라미터는 늘었음에도 성능이 감소한 것을 볼 수 있다. 결론적으로 저자들이 제안한 두 방식이 효과적이었음을 알 수 있다.
비슷한 크기의 모델과 비교
그럼 현존하는 여러 모델들과 동일한 사이즈를 맞춘 후 성능을 비교해 봐도 여전히 효과적일까? 실험 결과를 보면 알겠지만, T2T-ViT는 비슷한 파라미터와 연산량을 가지는 모델들에 비해 성능이 더 높다.
ViT 계열 vs. T2T-ViT
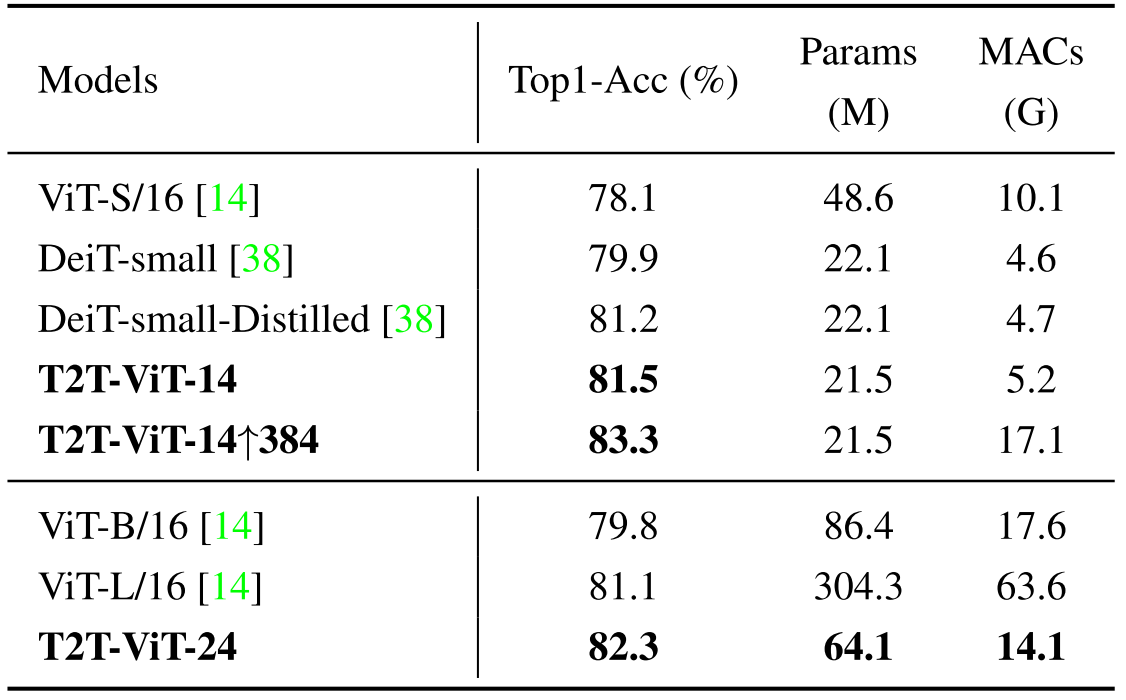
$\uparrow384$는 입력 이미지의 크기를 $384\times 384$로 늘려서 학습시켰음을 의미한다.
CNN 계열 vs. T2T-ViT
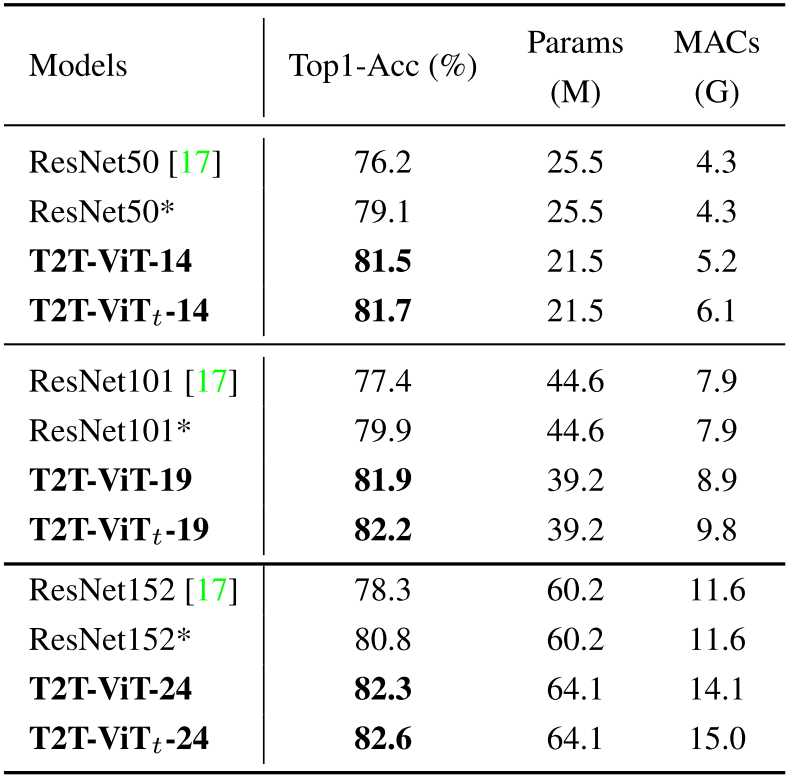
Performer를 쓰지 않은 $\text{ViT}_t$ 모델들이 연산량은 높지만 성능이 더 높다.
MobileNet vs. T2T-ViT
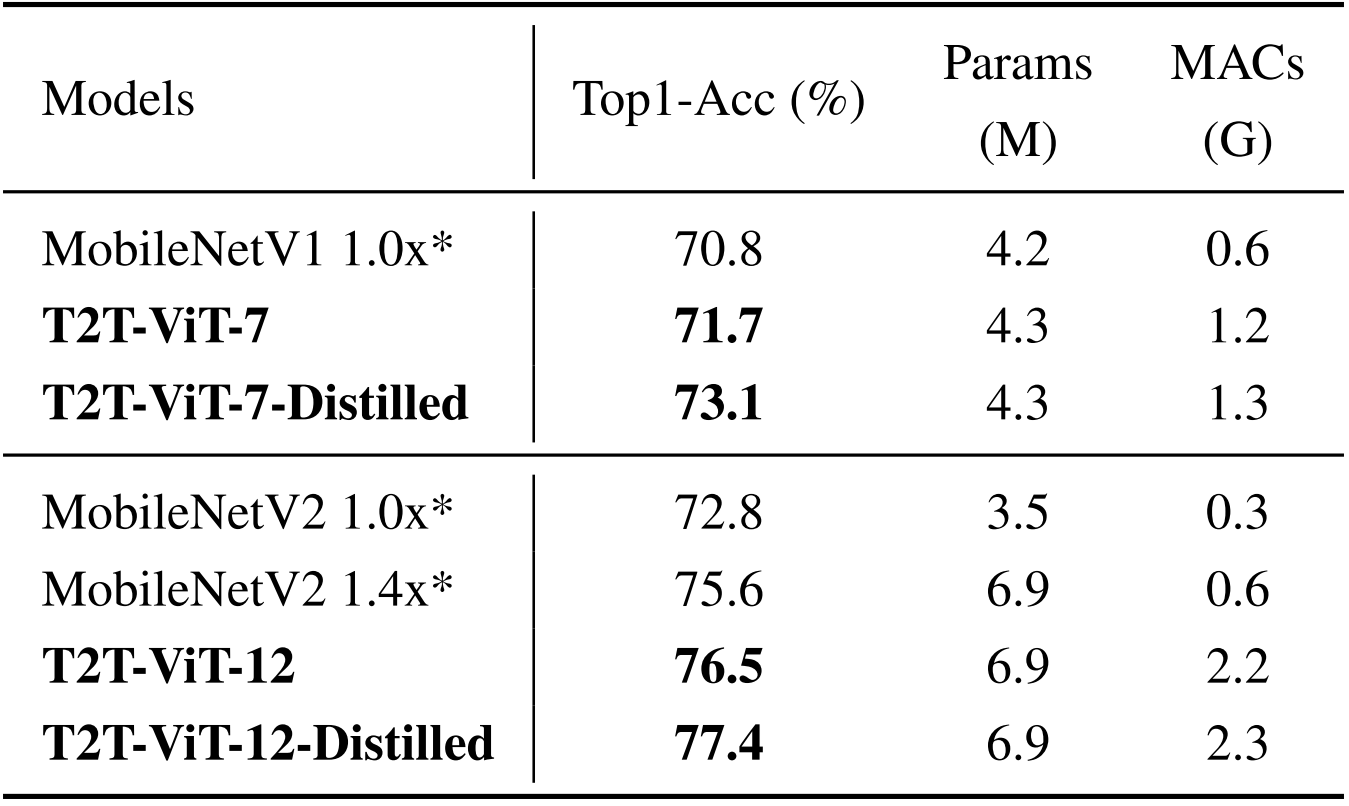
모바일 환경을 위한 별다른 추가사항 없이 층 수만 줄여 모델 크기를 비슷하게 만들어 주었는데, 연산량은 높지만 성능도 높다. Distilled는 DeiT에서처럼 Teacher Network를 사용해 학습시킨 모델이다.
Remarks
Patch Merging을 중점으로 내세운 연구를 찾지 못하다가, An Image is not worth 16x16 words를 보면서 알게된 논문이다. 논문에서 제안한 T2T 모듈 뿐만 아니라, CNN에서 유효한 Inductive Bias들을 ViT에도 적용하려는 시도를 했다는 점이 공감가면서도, 역시 왠만한 연구들은 다 이루어지고 있다는 아쉬움을 준다.

Leave a comment