관련 링크 : https://arxiv.org/abs/1904.12848
- Semi-Supervised Learning의 방법 중 하나인 Consistency Training 관련 논문
- Consistency Training과 Data Augmentation을 접목한 Unsupervised Data Augmentation을 제안
- 적은 수의 라벨링된 데이터만으로 당시 SOTA를 기록
Method
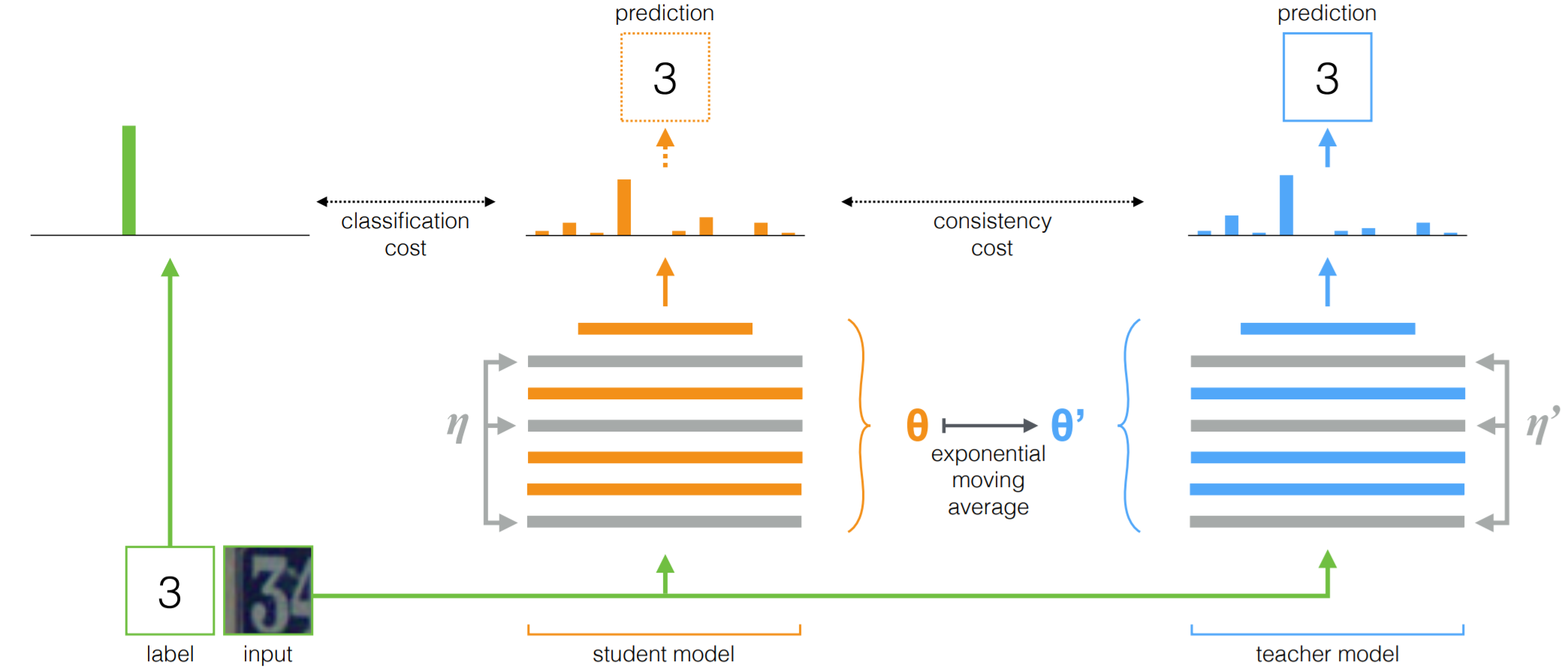
Unsupervised Data Augmentation

-
$y^*$를 정답으로 가진 데이터 $x$를, $\theta$를 파라미터로 가지는 모델 $\mathrm{M}$에 넣어 출력분포 $p_\theta(y|x)$를 얻어 Supervised Cross-entropy Loss(SCL)를 계산한다.
\[\mathrm{SCL} = \mathbb E_{x\sim p_L(x)}[-\log p_\theta(y^* |x)]\] -
정답이 없는 데이터 $x$와, DA를 이용해 변형한 데이터 $\hat x$를 앞서 이용한 모델 $\mathrm M$에 넣어 출력분포 $p_\theta(y|x)$와 $p_\theta(y|\hat x)$을 얻고, 두 분포의 Divergence와 비례하는 Unsupervised Consistency Loss(UCL)를 계산한다.
\[\mathrm{UCL} = \mathbb E_{x\sim p_U(x)}\mathbb E_{\hat x\sim q(\hat x|x)}[\mathrm {CE}(p_\theta(y |x)\|p_\theta(y |\hat x))]\]Divergence는 통계학이나 정보이론에서 사용되는 용어로, 어떤 분포와 다른 분포사이의 거리를 측정하는 방법이다. Distance보다는 약한 개념으로 symmetric하지 않아도 된다.
-
두 loss를 더해 최종 Loss를 계산하고 이를 이용해 모델을 학습시킨다.
\[\underset {\theta}{\min}[\mathrm{SCL}+\mathrm{UCL}]\] -
Additional Techniques
-
Confidence-based Masking: 모델의 예측 확률이 특정 값 $\beta$를 넘지 않으면 UCL을 계산하지 않는 방법. 보통 큰 값을 사용한다. CIFAR-10과 SVHN에서는 0.8, ImageNet에서는 0.5를 사용했다.
-
Sharpening Predictions: Softmax temperature $\tau$를 이용해, 라벨이 없는 데이터의 라벨로 이용할 모델의 예측을 과장한다.
\[p_{\tilde\theta}^{(sharp)}(y|x)=\frac{\exp(z_y/\tau)}{\sum_{y'}\exp(z_{y'}/\tau)}\] -
Domain-relevance Data Filtering: 라벨이 없는 데이터를 가져올 때 쉽게 가져올 수 있는 out-domain 데이터를 주로 이용한다. 하지만, 이 데이터가 in-domain 데이터와 너무 다르면 성능이 나빠지므로, In-domain 데이터로 학습한 모델을 이용해 예측 확률이 낮은 데이터를 걸러 낸 후 이용했다.
신문에서 가져온 글들을 A, 백과사전에서 가져온 글들을 B라고 하자. 모델을 A로 학습시켰다면 A는 in-domain 데이터가 되고, B는 out-domain 데이터가 된다.
-
Analysis
How more advanced DA can provide Extra Advantages?
-
Valid: 이미 Supervised Learning에서 동일한 라벨을 공유하는 현실적인 샘플을 만드는 것이 검증되었다. 따라서, 원본과 변형된 샘플사이의 Consistency 증가의 위험성이 적다.
-
Diverse: 기존의 노이즈들이 가져다주는 사소한 변화들에 비해 훨씬 더 다양한 샘플들을 만들어 낸다.
-
Targeted Inductive Biases: 기존의 노이즈들은 모델이 풀고자 하는 문제와는 동떨어져 있다. 즉, 노이즈들의 설계에서 풀고자 하는 문제는 전혀 고려되지 않았다. 하지만 DA들은 구체적인 문제를 위해 설계되었고, 좋은 성능을 보이는 것까지 검증되었으므로 올바른 inductive bias를 가진다.
Inductive Bias는 머신러닝에서 학습시 보지 못한 데이터를 처리하기 위해 필요한 가정이란 의미로 쓰인다. 딥러닝으로 확장시켰을 때, 모델의 구조를 결정하는 가정을 의미한다. 예를들어 이미지는 각 픽셀들이 공간적으로 관련있다는 가정을 두어 CNN을 이용하고, 시계열 데이터는 시간적으로 관련있다고 가정해 RNN을 사용한다.
Intuitive Sketch
-
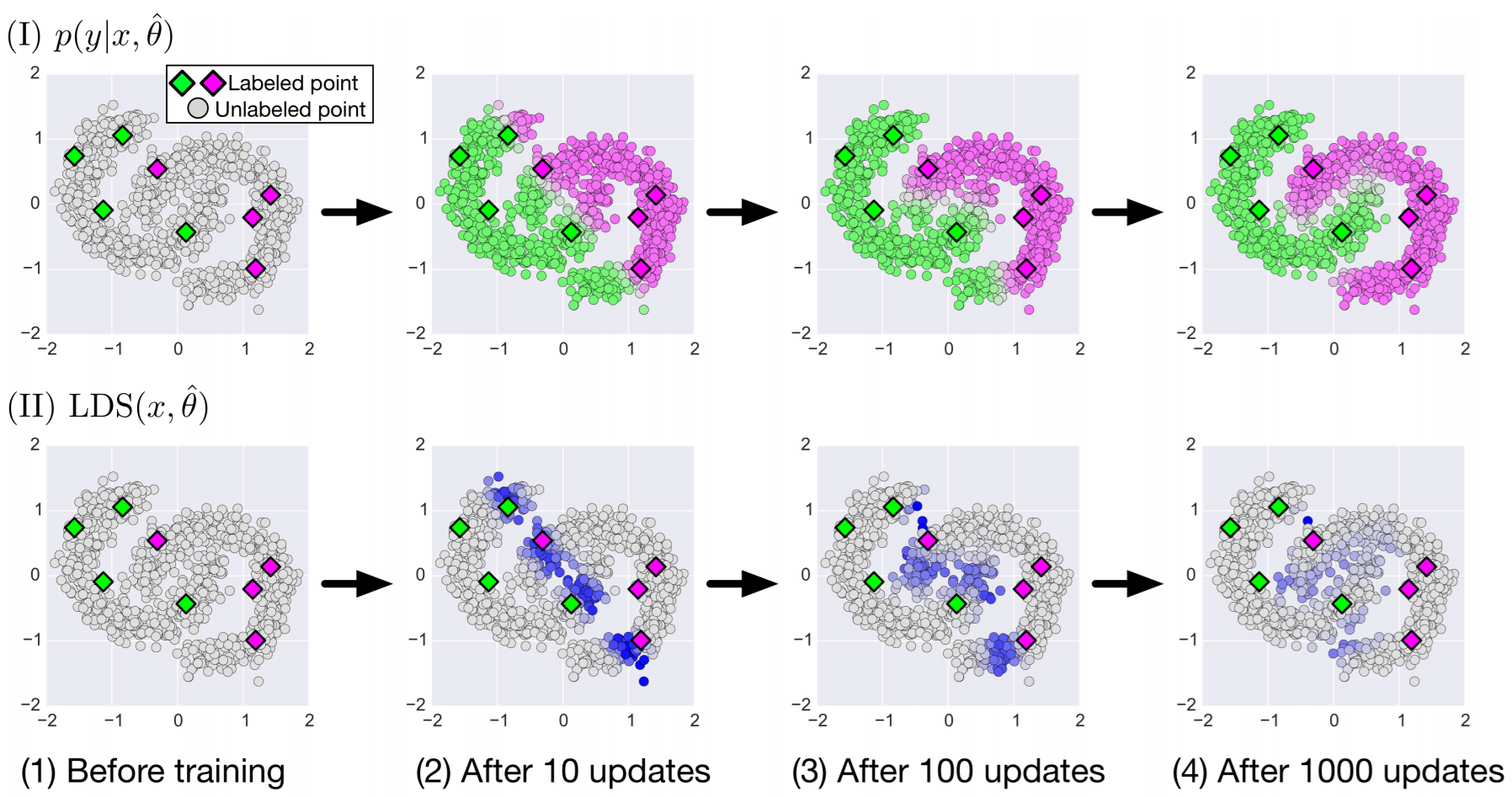
각 노드가 데이터를 나타내고, DA를 통해 한 노드를 다른 노드로 바꿀 수 있을때만 선이 연결되는 그래프 $G$가 있다고 생각해 보자. 라벨이 있는 데이터만 색으로 표시했을 때, Supervised Learning은 다음과 같다.

- 서로 연결되지 않은 하위 그래프들의 개수를 $N$이라고 할 때, 위 경우는 연결이 없으므로 $N=15$이고, 모든 샘플을 학습하기 위해서는 하위 그래프 내부의 모든 샘플이 라벨을 가지고 있어야 한다.
-
여기서, Supervised Learning에 간단한 DA를 사용하면 어떨까? 라벨이 없는 데이터들 중 몇몇은 라벨이 있는 데이터와 연결 될 것이고, DA를 통해 라벨을 전파받는다. 라벨을 전파 받았을때는 연한 색으로 표시했을때, 그림은 다음과 같이 바뀐다.

- DA를 사용해 연결을 늘려서, 위 경우는 $N=7$이 되고, 라벨이 있는 노드와 직접적으로 연결되면 라벨을 전파받는 것을 고려하면 DA를 사용하지 않은 경우보다 훨씬 적은 샘플만 라벨을 가지면 된다.
-
아직까지 Supervised Learning이라, 라벨이 없는 노드들이 서로 연결 되어 있지만, 라벨을 전파 받은 노드는 직접적으로 라벨이 있는 노드와 연결된 노드 뿐이다. 가장 성능이 좋은 DA들을 사용하면 어떨까?

- 간단한 DA보다 연결이 많아져 $N=3$이 되고, 라벨을 가져야 하는 샘플 수 역시 줄어든다.
-
간단한 DA를 쓴 것보다 연결이 늘어나 직접적으로 연결된 노드들이 증가했다. 하지만 그 수가 많지는 않다. 여기서 UDA를 쓰면 다음과 같이 바뀐다.

- 연결만 존재하면 라벨은 전파받을 수 있으므로, $N$ 내부에 라벨이 있는 샘플이 하나씩만 존재하면 된다. 즉, 학습을 위해 요구되는 라벨이 있는 데이터의 수가 가장 적다.
Experiments
- 성능 비교 실험과 핵심적이지 않은 여러 실험을 기록하지 않았다.
Better augmentation Can lead better performance in SSL

Vary the size of labeled data




Leave a comment