관련 링크 : https://arxiv.org/abs/2106.01548
- ViT와 MLP-Mixer의 Loss Landscape에서 Sharp Local Minima가 낮은 일반화 성능의 원인이라 추정
- Sharpness-aware Optimizer인 SAM을 이용해 Sharp Local Minima를 해결
Intro
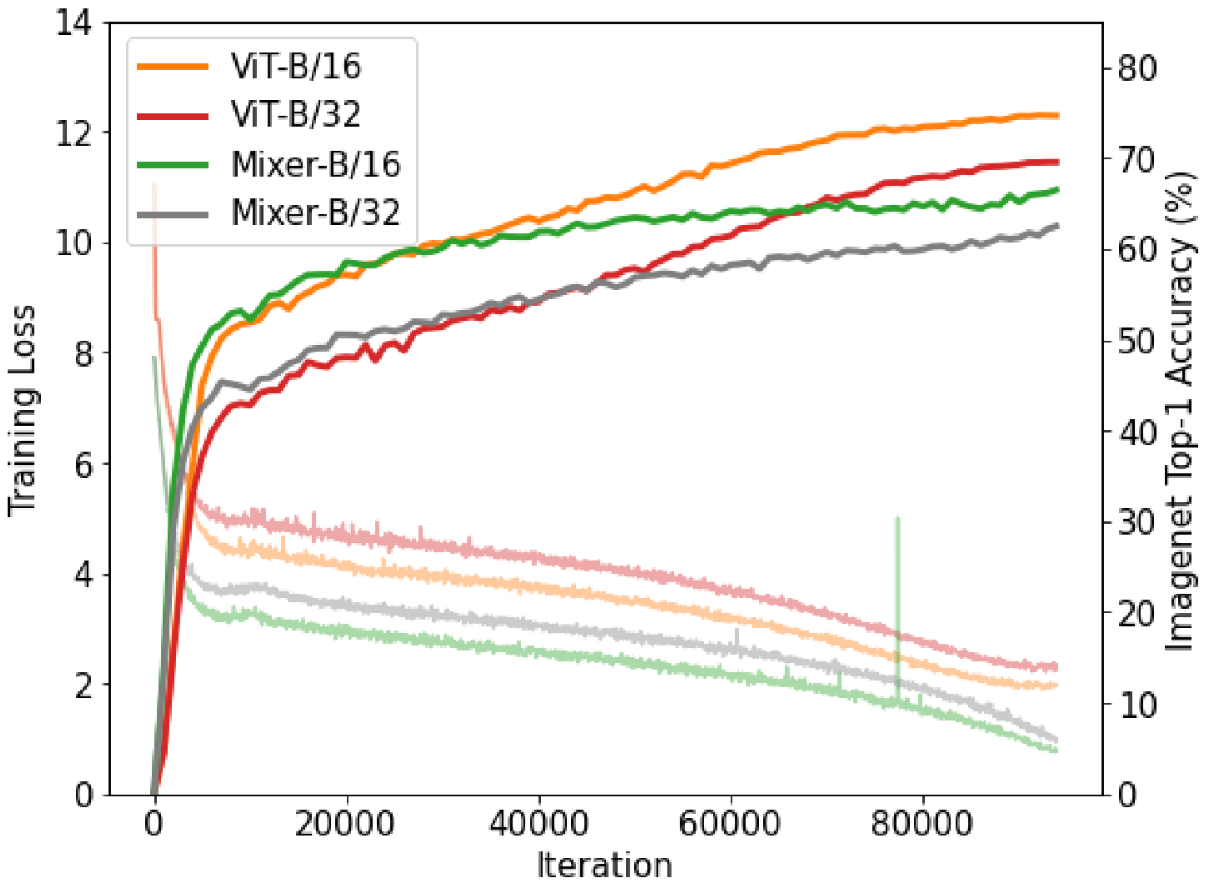
ResNet-152가 78.5%의 성능을 기록한 것에 비해, 보다 많은 파라미터를 가진 ViT-B/16은 74.6%의 성능을 기록했다.
NLP에서 Transformer가 대량의 데이터를 이용한 Pretraining으로 좋은 성능을 보였고, 이 방법론이 Vision에도 이용되기 시작하면서, Convolution이 가진 같은 구조적인 Inductive Bias를 대량의 데이터를 통해 대체하려는 움직임이 활발해졌다. 이런 시도들은 당연히 Large Scale Pretraining을 요구했는데, 이 때문에 Transformer나 Only MLP 모델들(MLP-Mixer, Res-MLP 등)은 대용량의 데이터 셋 없이는 ResNet을 이기지 못했다.
딥 러닝의 대가 중 한 명인 Bengio 교수님의 설명에 따르면 Inductive Bias는 러프하게 추가 데이터로 해석될 수 있다. 따라서, 대규모의 추가 데이터를 이용한 Pretraining이나 강한 Data Augmentation을 사용 했을 때, 부족한 Inductive Bias가 보충되어 성능이 향상하는 것은 타당해 보인다.
대량의 데이터를 이용한 대체이므로, 당연히 ImageNet과 같은 중간 규모의 데이터 셋에서는 Inductive Bias가 부족 할 수 밖에 없다. 오늘 리뷰 할 논문은 그런 면에서 흥미롭다. CNN을 Teacher Model로 이용하거나, Self-Attention을 수정하는 방식으로 Inductive Bias를 도입하지 않고, 추가적인 데이터를 이용한 Inductive Bias도 도입하지 않는다. 그럼에도, ViT와 Mixer를 ResNet과 동등하거나 더 뛰어나게 만들어 준다.
Lens of Loss Landscape
먼저 Regularization 기법들(Dropout, Stochastic Depth, Weigth Decay 등)을 적용해도 Strong Data Augmentation 없이 ResNet을 이길 수 없다는 잘 알려진 단점 외에 ViT와 MLP-Mixer(MLP 계열의 모델의 대표로 Mixer를 선택)의 단점들을 살펴보자.
-
학습 과정에서 Gradient가 뾰족하게 튀어 오르는 부분(Spike)이 생겨 정확도가 급강하 할 수 있다.
제일 첫 번째 그림의 Mixer-B/16을 보라
-
학습이 파라미터 초기화와 하이퍼 파라미터에 민감하다.
-
Generalization Gap이 크다.
제일 첫 번째 그림을 보면 낮은 Training Loss가 높은 성능을 보장하지 못한다.
한 눈에 위의 단점들은 데이터 셋 크기의 문제가 아닌 Optimization의 문제임을 알 수 있다. 따라서, 저자들은 이 문제들의 원인 알아보기 위해 ResNet, ViT 그리고 Mixer의 Weight에 따른 Loss Landscape를 살펴본다.
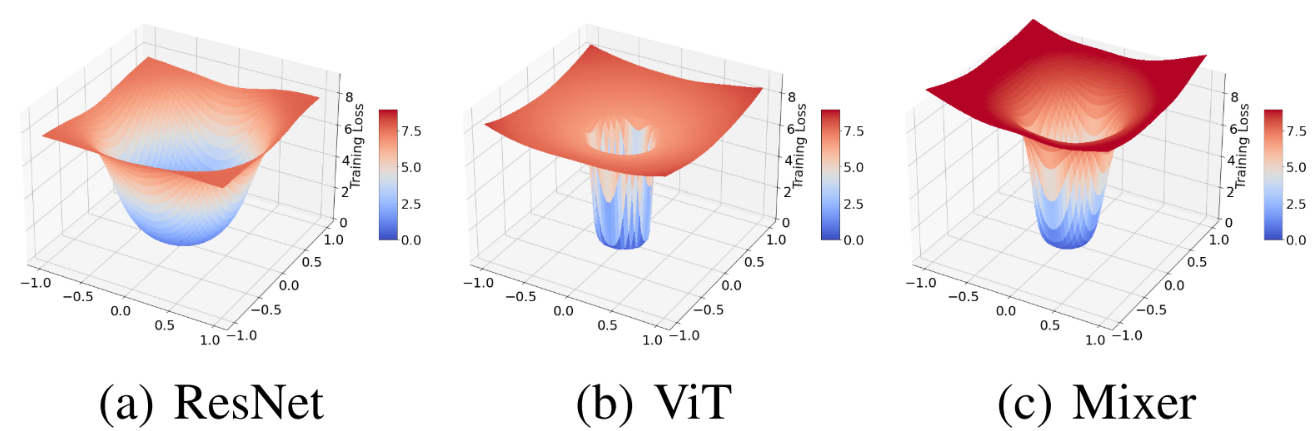
시각화 방식은 이 논문의 방식을 따른다. 간단히 설명하면, 중심 파라미터 $\theta^*$를 두고, 임의의 두 방향 $\delta$와 $\eta$를 이용해 다음 식의 $\alpha$, $\beta$를 바꿔가며 시각화 한다.
\[f(\alpha, \beta) =L(\theta^*+\alpha\delta+\beta\eta)\]이때, ReLU 같은 일부의 출력을 그대로 내보내는 Activation의 경우에 Layer의 1의 파라미터에 10을 곱하고, 2의 파라미터에 10을 나누어도 원래 모델과 출력이 같은 Scale Invariant 특성이 존재하게 되어 Loss 시각화를 이용해 여러 방식들 간의 비교를 할 수 없게 된다. 따라서, 각 방향 $\delta$, $\eta$에 파라미터 크기를 이용하도록 $\frac{\delta}{|\delta|}\times |\theta|$와 같은 Normalization을 수행해 준다(식에 나타내진 않았는데 Filter-wise Normalization이다. 헷갈리면 원 논문을 보자).
그림에서 알 수 있듯, ViT와 Mixer는 날카로운 Loss Landscape를 가지고 있다. 이는 다른 방식으로도 확인할 수 있는데, 다음 표를 보자.
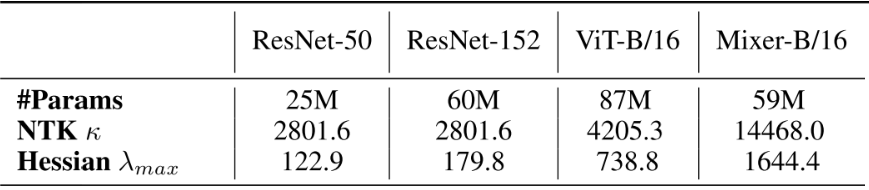
- Landscape curvature를 Loss에 대한 파라미터의 Hessian이 가지는 최대 고유값 $\lambda_{max}$로 나타낼 수 있다.
- NTK의 Hessian의 최대 고유값 $\lambda_1$과 최소 고유값 $\lambda_m$의 비 $\kappa=\frac{\lambda_1}{\lambda_m}$가 클 수록 학습이 불안정하다는 연구가 있다.
- Mixer의 $\lambda_{max}$와 $\kappa$가 제일 큰 것은 가장 Inductive Bias가 적은 모델이기 때문으로 추정된다.
표에서 나타난 것처럼, ViT와 Mixer가 ResNet에 비해 $\lambda_{max}$와 $\kappa$가 매우 크다. 즉, 앞서 말한 Gradient Spike나 초기화에 민감한 학습 불안정성이 당연히 나타날 수 밖에 없는 형태이고, 논쟁의 여지가 있지만 Flat Minima로의 수렴이 일반화 성능에 약간 이득이 된다는 여러 연구들을 생각해 보면 Generalization Gap이 큰 것도 타당해 보인다.
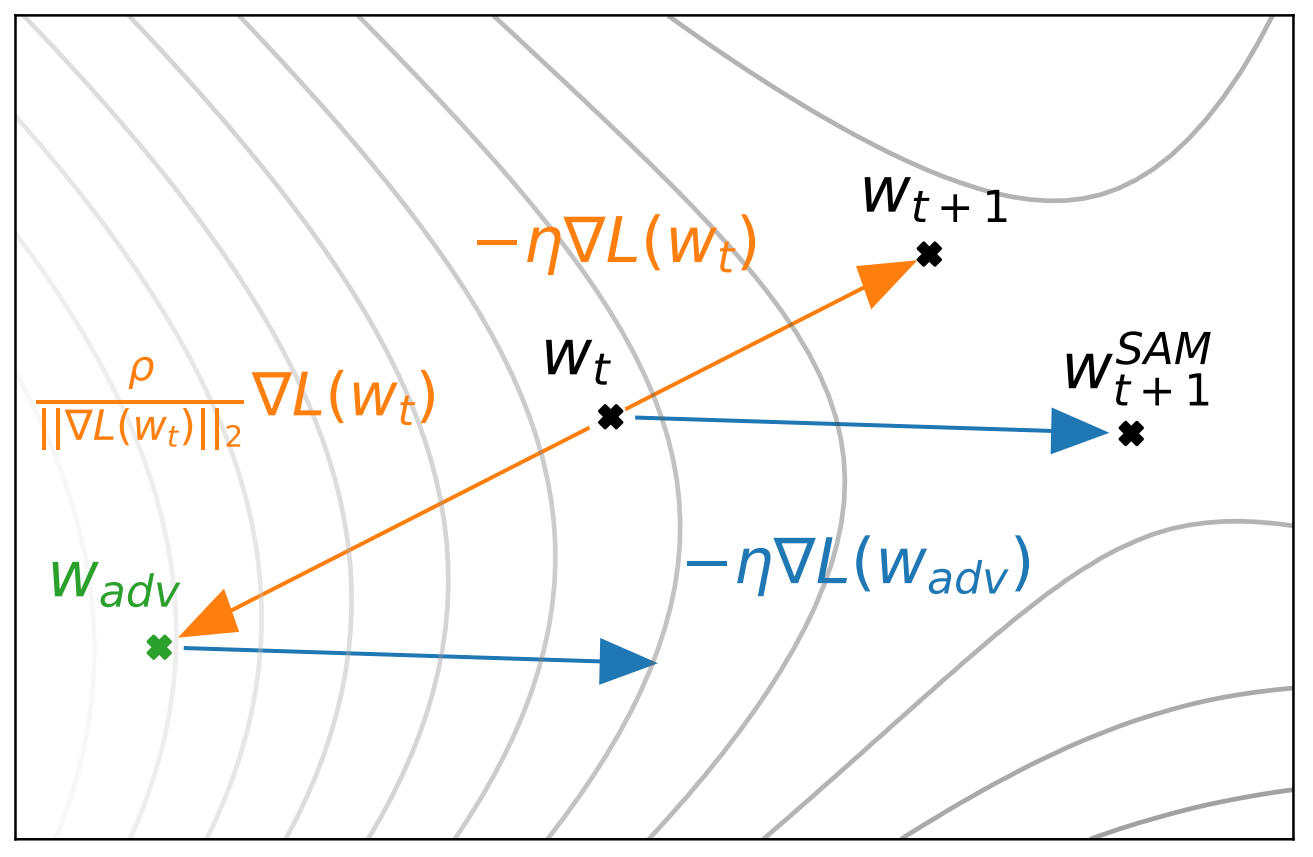
그럼 이를 어떻게 해결 할 수 있을까? 위의 단점들이 모두 Sharp Minima로 수렴했기 때문이므로 이를 좀 더 부드럽게 만들면 될 것이다. SGD와 Adam과 같은 First-order Optimizer들은 Training Error를 0까지 효과적으로 낮추지만, Generalization Error는 오히려 높다. 앞서 본 것 처럼, ViT와 Mixer는 Inductive Bias가 적어 이 경향성이 증폭되어 Training Error를 가장 빠르게 0으로 만드는 Sharp Local Minima로 수렴한다.
SAM은 Second-order Optimizer로 두 번의 Full Forward-Backward 연산을 요구하지만, 파라미터 $\theta$ 근처의 모든 파라미터들이 낮은 Training Loss를 가지도록 해 Local Minima 주변을 Smoothing 하는 효과가 있다. SAM에 관한 논문을 리뷰하는 것은 아니므로, 바로 SAM을 적용한 이 후 Mixer와 ViT에 어떤 변화가 생겼는지 확인해 보자.
Intrinsic changes After SAM
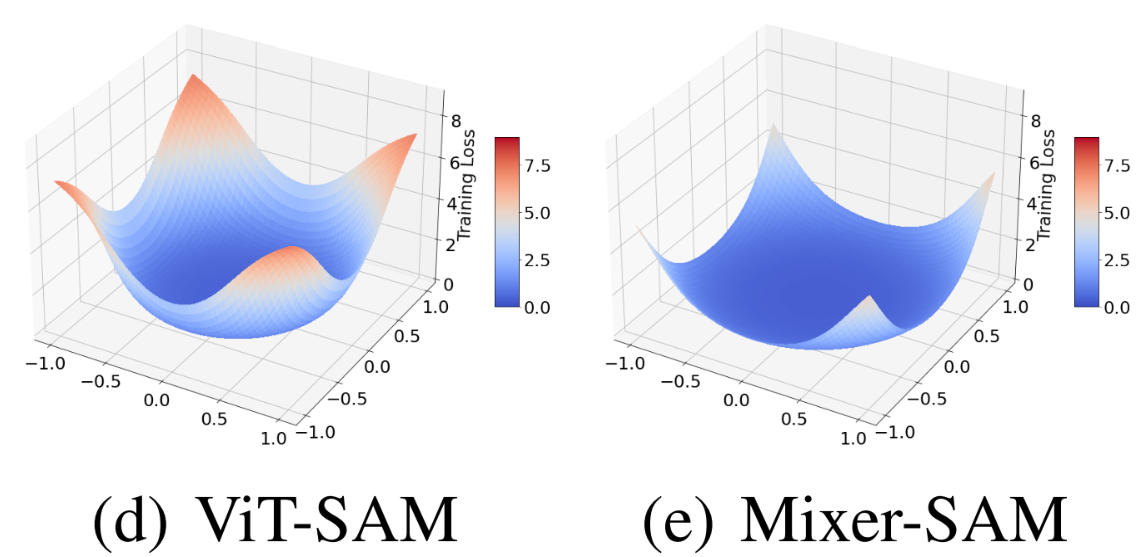
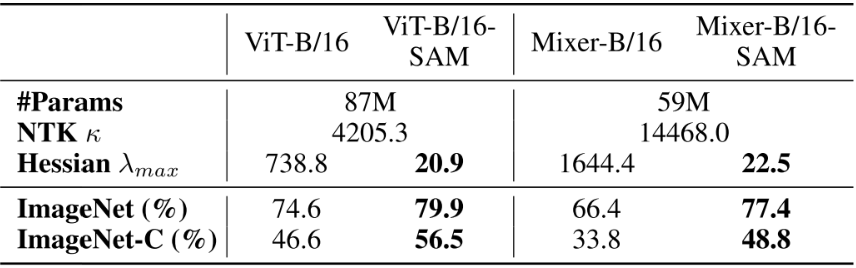
Loss Landscape도 많이 부드러워 졌고, $\lambda_{max}$와 $\kappa$ 역시 확연히 감소했다. 심지어 성능도 상승해서, ResNet의 78.5%를 능가했다. 하지만 SAM으로 인한 변화를 이것들 만으로는 살펴보기에는 아쉬우므로 더 살펴보자.
먼저 각 Block별 Hessian의 $\lambda_{max}$와 출력의 Norm, 그리고 모델 파라미터의 Norm을 보자.

-
초기 층의 $\lambda_{max}$가 깊은 층보다 상대적으로 크다. 이는 초기 층이 Sharp Minima에 많은 영향을 준다는 의미이고, Spiking Gradient의 원인이 초기 Embedding Layer라는 이전 연구와 일치한다.
-
Spatially Interaction을 담당하는 MSA/Token MLP들의 $\lambda_{max}$가 MLP/Channel MLP에 비해 낮다.
Vision Task이므로 Spatially Interaction이 효과적인 Inductive Bias라 Sharpness를 증폭하는데 적은 기여를 한다는 의미로 해석 될 수 있지 않을까?
-
Weight Norm은 오히려 커졌고, 이는 Weight가 커지는 방향이 일반화에 좋을 수 있다는 가능성을 나타내기 때문에 Mixer와 ViT에서 Weight Decay가 효과적이지 않을 수 있다는 가능성을 보여 준다.
-
$\lambda_{max}$가 낮아진다.
다음으로 Mixer의 각 Block별 활성 뉴런의 비율을 살펴보자.
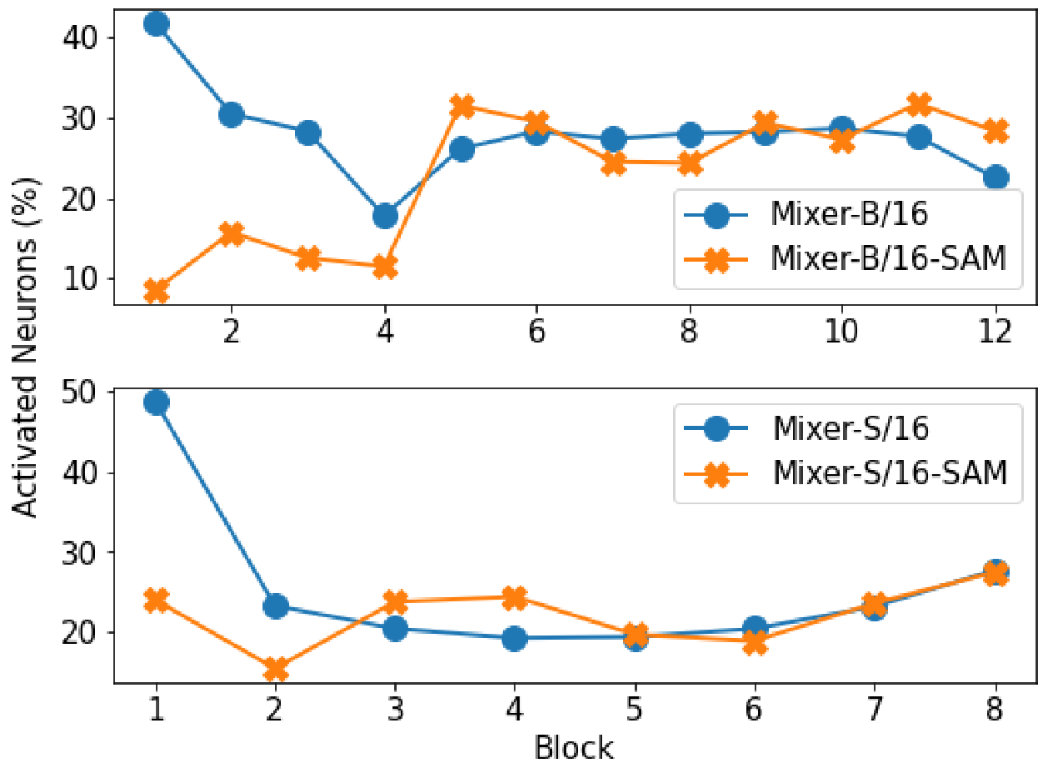
Mixer에서 각 Block의 Hessian을 구할 때, Recursive한 방식으로 구하는데 이 과정에서 각 층의 활성 뉴런 개수(0보다 상당히 큰 파라미터의 수)를 계산한다. 이때, 초기 Block의 활성 뉴런의 개수가 적은 것을 보고 ViT에서도 구한 것으로 보인다.
- Mixer의 초기 활성 뉴런 비율이 낮은 것은 Image Patch들의 Redundancy를 보여준다.
- 그림은 없지만, ViT의 활성 뉴런 비율은 Mixer와 ResNet보다 작다. 이는 ViT가 Pruning될 여지가 많고 Transformer가 Multi-modal에 적합 할 수 있었던 이유를 나타낸다.
다음으로 SAM 적용 유무에 따른 Attention Map을 살펴보자.
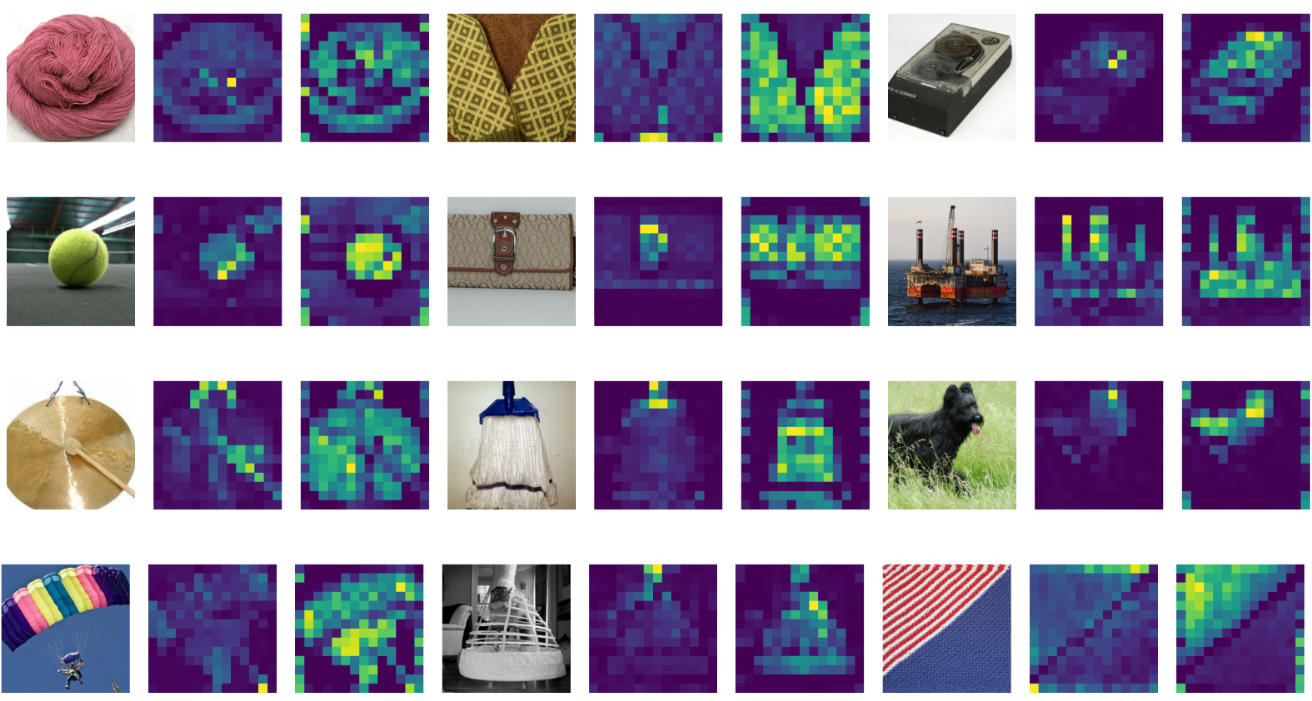
세 이미지를 짝으로 왼쪽부터 입력, 일반적인 ViT, SAM으로 학습한 ViT이다.
- 더 설득력 있는 Attention Map을 제공한다.
다음으로 Training Error와 Validation Acc를 살펴보자.
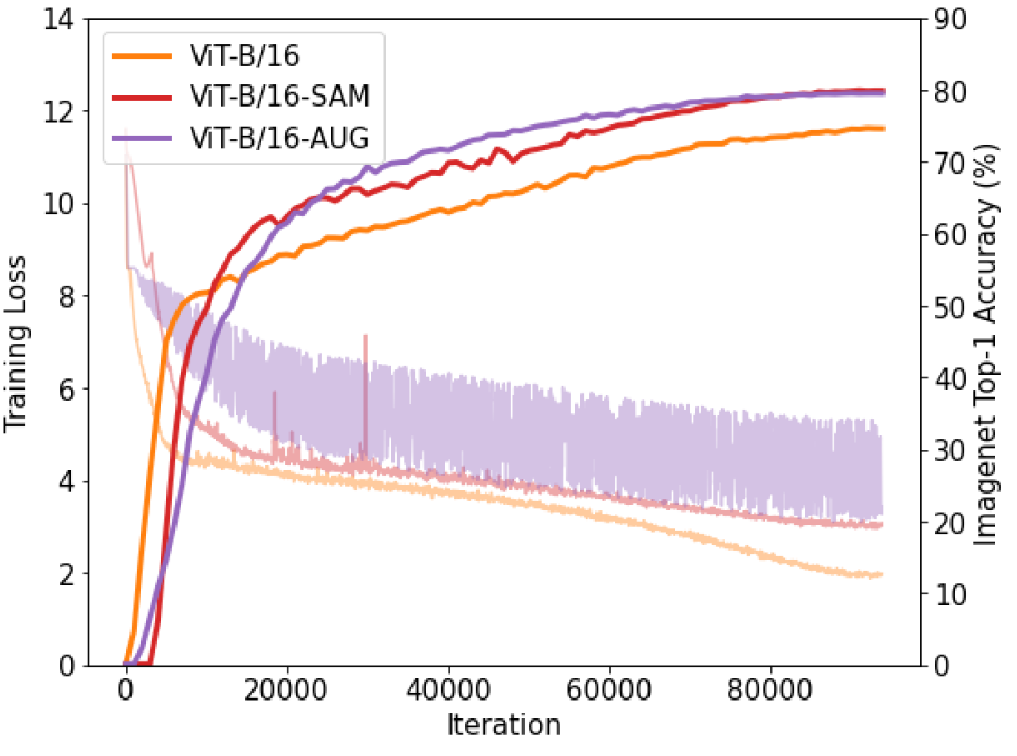
- Training Error가 더 높음에도 Val Acc는 더 높음을 볼 수 있다.
마지막으로, ResNet 역시 SAM을 이용해 성능이 상승 할 수 있으므로 파라미터 개수에 따른 각 모델들의 성능을 비교해보자.
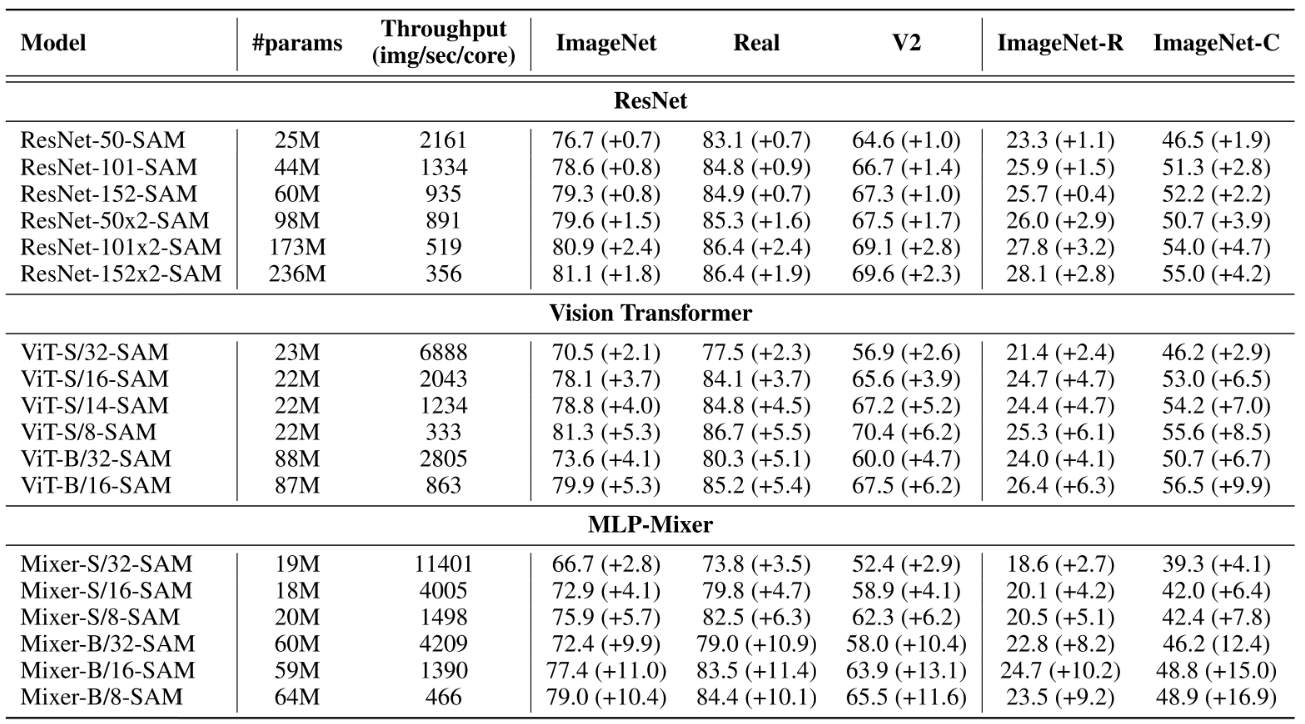
- SAM으로 인한 성능 향상 폭이 ResNet보다 ViT와 Mixer에서 더 크다.
- 비슷한 파라미터 수를 가질 때 더 좋은 성능을 보인다.
결과적으로, 앞의 분석들이 Sharp Minima로의 수렴이 낮은 성능이 원인이라는 가정이 타당함을 보여 준다. 그리고 Inductive Bias의 부족으로 Sharpness의 정도가 심했던 Mixer가 SAM으로 인한 성능 향상이 더 큰 점도 가정의 또 다른 증거가 된다.
Conclusion
위의 실험들 외에도 논문에 다양한 Ablation이 있지만, Sharp Minima를 SAM으로 개선했고 충분히 유효했다는 논문의 핵심을 보여 주기엔 위의 결과들로 충분해 더 정리하진 않았다. Ablation으로 Training Set Size에 따른 실험, Robustness의 향상이 있었으므로 Adversarial Training과 결합했을 때 어떤 지에 대한 실험, Contrastive Learning에 대한 실험 등이 있으니 관심 있으면 원래 논문을 살펴보자.
Remarks
Convolutional-Free 모델에 관심을 가지다가 알게 되어 읽은 논문이다. SAM 같은 Second-order Optimizer도 몰랐고, Loss Landscape Visualization이며 NTK 등등 잘 모르는 부분이 많아서 읽는데 정말 오래 걸렸다. SAM을 알게 되면서 실험에도 써봤는데, 데이터 셋이 워낙 작아 시간에 비해 큰 효과는 못 봤는데 논문을 안보고 막 써서 그런 것 같으니 이것도 리뷰 해야 할 듯 싶다.

Leave a comment