관련 링크 : https://arxiv.org/abs/1905.09272v2
Self-Supervised Learning : CPCv2(2019)
Abstract
사람은 유용한 몇몇의 예제만으로 물체가 무엇인지 인식하는 법을 배운다. 이에 근거하여 논문은 Contrastive Predictive Coding을 개량하여 작은 양의 labeled data로 downstream task에 좋은 성능을 보이는 data-efficient recogntion을 제안한다.
1. Introduction
사람과 동물은 적은 예시만으로 물체의 종류를 빠르게 배우는 반면에 딥러닝 모델들은 많은 예시가 필요하다. 하지만 한 연구에서 단 하나의 예시만을 가지고 학습한 모델이 사람을 뛰어넘는 성능을 보일 수 있음을 증명했다. 이 모델은 딥러닝 모델이 아니지만, 잘 구성된 representation이 Data efficiency를 향상시킨다는 가능성을 제시했다. 하지만 실제 visual task에서 그런 representation을 찾기는 어렵다.
그러면 어떻게 Data efficiency를 향상시킬 수 있을까? 여러 연구에서 시공간 변동성을 제대로 인식하는 능력이 visual area의 특징을 설명하는데 효과적이라고 밝혔다. 따라서 논문은 변동성을 인지하는데 사용되는 representation의 predictability가 data-efficiency의 중요한 역할이라 가정하고 이를 위해 unsupervised method인 Contrastive Predictive Coding을 사용한다.
사람은 영상에서 변화를 빠르게 알아차리므로, 시공간의 변화를 알아채는 능력을 키운다면 효과적인 representation이 될 것이라는 가정에서 연구를 시작한 것으로 보인다.
CPC는 관찰이 시간적 또는 공간적 차원과 같이 순서에 따라 이루어지도록 요구하는 기술로, 이 방법의 representation이 downstream linear classification task에 효가가 있음은 증명되었다.
본 논문은 다음과 같은 공헌을 했다.
- 개량한 CPC를 사용하여 Linear classification시 성능을 향상시켰다.
- 아주 적은 labeld images를 사용했을때 pixel supervised method보다 성능이 좋음을 확인했다.
- Linear classification accuracy와 data-efficieny와는 관계가 없을을 확인했다.
- 새로운 task와 dataset에서 뛰어난 일반화 성능을 확인했다.
2. Experimental Setup
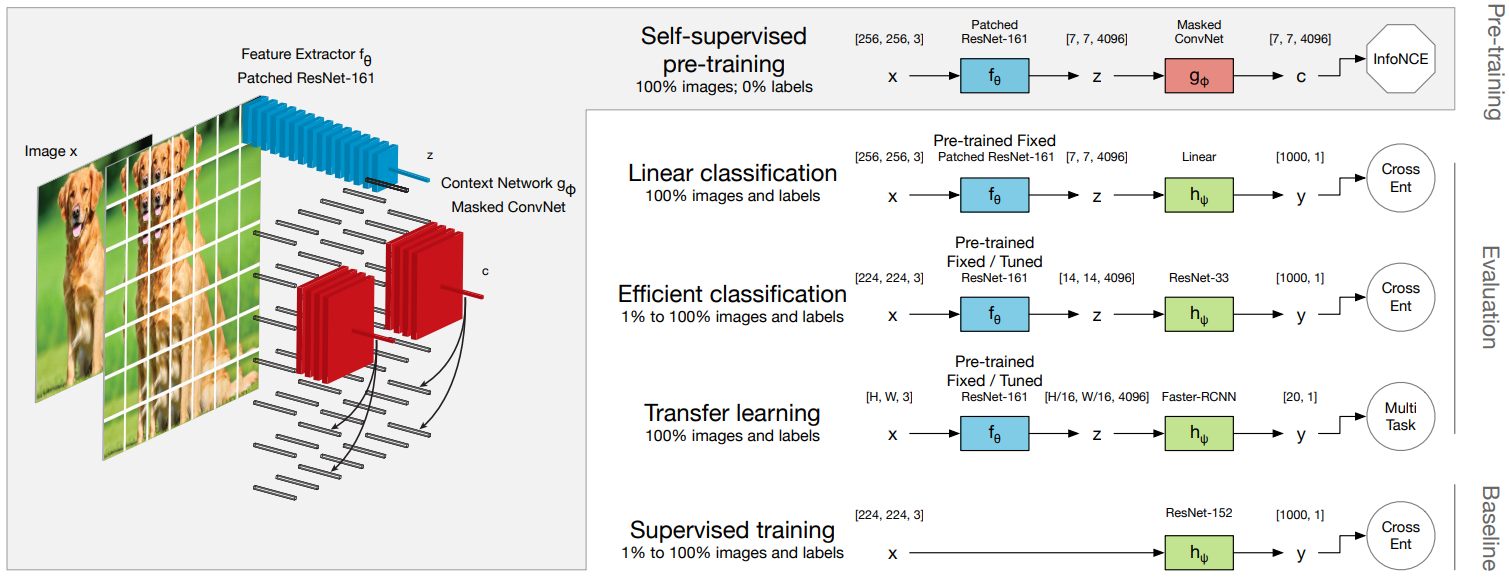
2.1 Contrastive Predictive Coding
-
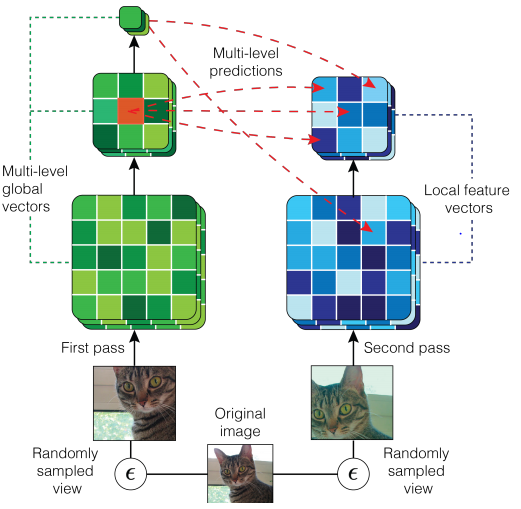
입력 이미지를 중복 패치 $x_{i, j}$로 나눈다.
-
각 패치를 encoder network $f_\theta$에 넣어 single vector $z_{i,j}=f_\theta(x_{i,j})$를 만든다.
-
$z$ 뭉치를 context network $g_\phi$에 넣어 context vector $c_{i,j}$를 만든다. 이때 Mask는 $c_{i,j}$의 receptive field가 $\{z_{u,v}\}_{u\le i,v}$도록 해준다.
- Prediction matrix $W_k$(prediction length $k>0$)를 이용해 $\hat z_{i+k,j}=W_k c_{i,j}$를 예측한다.
논문의 저자가 19년도 NIPS에서 발표한 영상을 보니 음성의 경우 너무 가까운 신호는 예측하기 힘들다고 한다. 따라서 이미지에서도 k가 1보다는 어느정도 큰 값이어야 좋은 성능이 나오지 않을까 싶다.
-
$c_{i,j}$과 $z_{i+k,j}$의 mutual information이 최대가 되도록 $\mathcal L_\mathrm{CPC}$를 이용해 학습한다.
\[\mathcal L_\mathrm{CPC}=-\sum_{i,j,k}\log p(z_{i+k,j}|\hat z_{i+k,j},\{z_l\})=-\sum_{i,j,k}\log \frac {\exp (\hat z^T_{i+k,j}z_{i+k,j})}{\exp (\hat z^T_{i+k,j}z_{i+k,j})+\sum_l\exp (\hat z^T_{i+k,j}z_{l})}\]- negative samples $\{z_l\}$ : 이미지의 다른 위치나 배치안의 다른 이미지에서 무작위로 뽑은 feature vectors
2.2 Evaluation Protocol
-
$f_\theta$, $g_\phi$, $\{W_k\}$를 학습시킨 후, $z=f_\theta(x)$를 representation으로 사용할 것이므로 나머지를 버린다.
-
$z$를 이용해 classifier $h_\psi$를 supervised method로 학습시킨다.
\[\theta ^*=\arg \min _\theta \frac {1}{N}\sum^N_{n=1}\mathcal L_\mathrm{CPC}[f_\theta(x_n)]\qquad \psi^*=\arg\min_\psi\frac {1}{M}\sum^M_{m=1}\mathcal L_\mathrm {Sup}[h_\psi\circ f_{\theta^*}(x_m),y_m]\]- $N$ : number of unlabeled images $\mathbb D_u =\{x_n\}$, ImageNet ILSVRC 2012 training set
- $M$ : : number of unlabeled images $\mathbb D_l =\{x_m,y_m\}$
- $\mathcal L_\mathrm{Sup}$ : classification의 경우 cross-entropy
- Linear classification : $f_\theta$는 fixed하고 $h_\psi$는 $\mathrm{Linear-Mean\;pool}$로 구성해 성능을 평가한다. unsupervised learning phase에서만 data-augmentation을 적용한다.
- Efficient classification : $f_\theta$는 fixed/fine-tuned하고 $h_\psi$는 11-block ResNet을 사용하여 $\mathbb D_l$의 $1\%$, $2\%$, $5\%$, $10\%$, $20\%$, $50\%$, $100\%$를 이용했을때 성능을 평가한다. unsupervised learning phase에만 data-augmentation을 적용한다.
- Trasnfer learning : $f_\theta$는 fixed/fine-tuned하고 Faster-RCNN 구조를 이용해 $\mathbb D_l$이 PASCAL-2007일때의 detection 성능을 평가한다.
3. Related Work
- Representation learning : Generative model, GAN, Self-supervised learning
- Contrastive method : CMC, AMDIM, CPC
- Label-propagation : pseudo labeling, entropy minimization
4. Results
4.1 From CPCv1 to CPCv2
성능을 향상시키기 위해 4가지를 변경했다.
- Model capacity : CPCv1이 encoder로 ResNet-101의 처음 세 블럭만 사용했다면, 논문에서는 세번째 블럭의 깊이와 폭을 늘리고, 이를 ResNet-161이라고 부른다.
-
Layer normalization : CPCv1에서 BN은 패치간 의존성을 높여 trivial solution을 찾도록 유도해 성능을 저하시켰으므로 이를 layer normalization으로 대체한다.
-
Prediction lengths and directions : 큰 모델일 수록 overfitting하기 쉬운데 이를 더 어려운 task를 모델이 풀게하여 이를 해결했다. CPCv1이 $c$로 아래에 있는 $z$를 예측했다면, CPCv2는 상하좌우방향으로 4번 예측하도록한다.
-
Patch-based augmentation : 패치간의 의존성을 줄여 low-level cues를 없애기 위해 CPCv1보다 많은 data-augmentation방식을 사용했다.
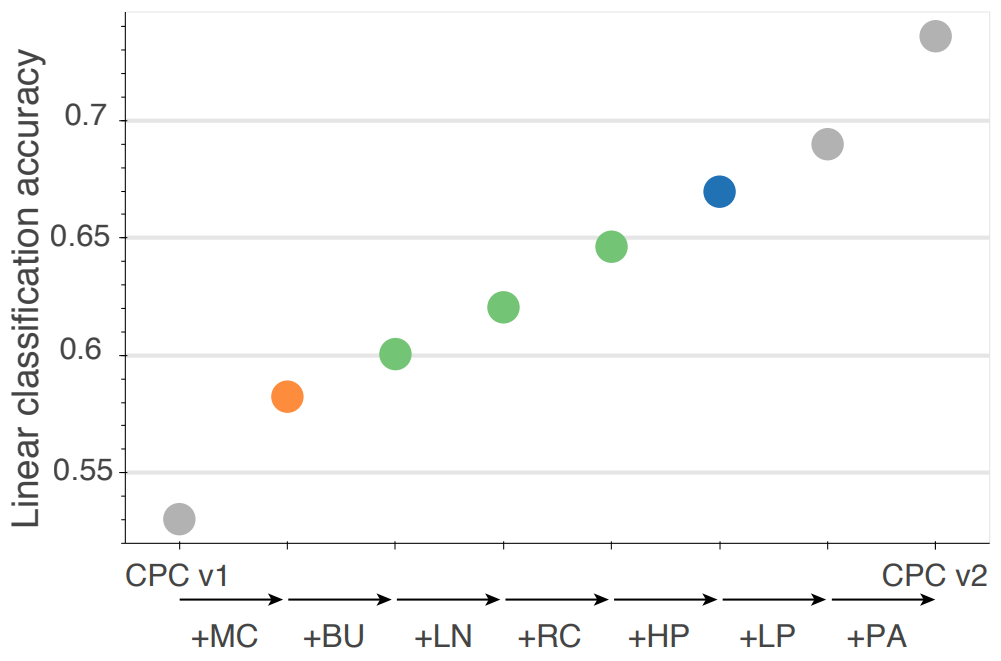
MC : model capacity, BU : bottom-up spatial predictions, LN : layer normalization, RC : random color-dropping, HP : horizontal spatial prediction, LP : larger patches, PA : further patch-based augmentation. 각 색상은 prediction direction의 수가 1, 2, 4 일 때를 뜻한다.
Comparison to previous art
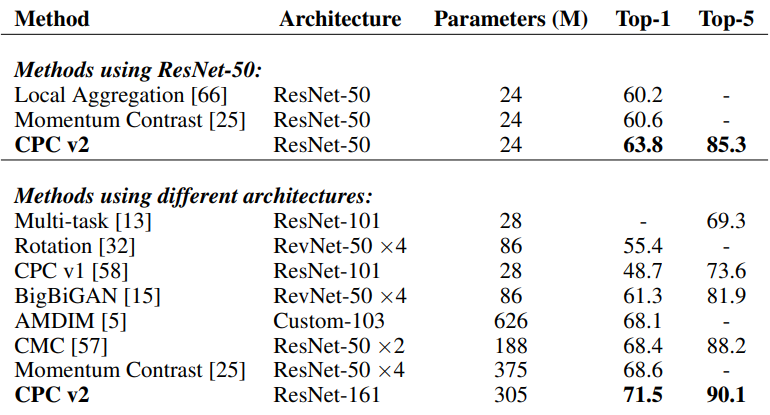
Linear classification accuracy
4.2 Efficient Image Classification
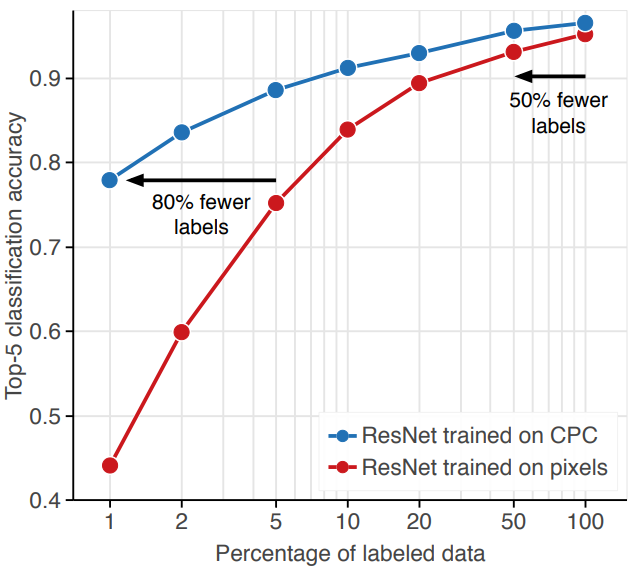
CPC v2(fine-tuned) vs Supervised
-
Supervised metohd보다 data-efficiency가 높고, 심지어 모든 데이터셋을 사용했을때 성능도 더 좋다.
논문에서는 CPC의 학습 방식이 representation의 predictability를 증가시켜 적은 양의 데이터에서 학습하는 능력을 키우기 때문이라고 추측한다. 따라서 prediction task의 복잡도를 늘리면 data-efficiency가 증가할 것으로 예상했고, 실제로 그렇게 동작했다.
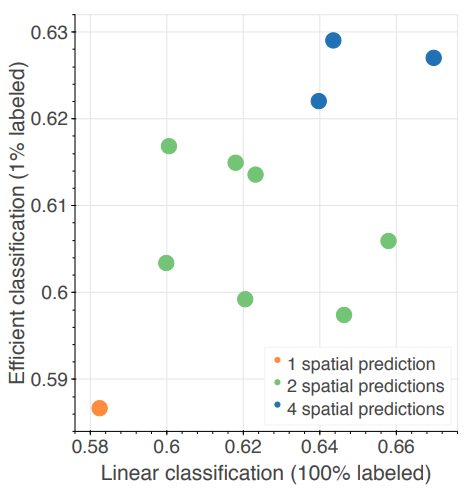
- Prediction task의 복잡도가 data-efficiency의 성능에는 영향을 주지만, 같은 복잡도를 가진 모델끼리 비교했을때 Linear classification의 성능과 data-efficiency와는 관계가 없음을 알 수 있다.
Other unsupervised representations
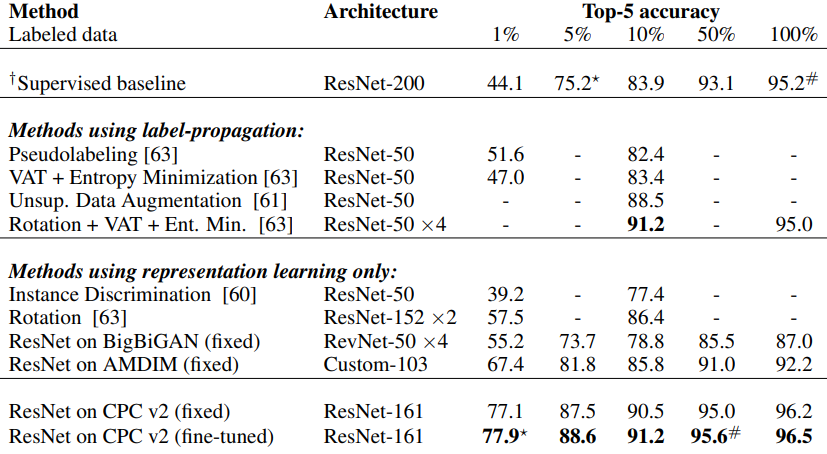
$*, \#$은 supervised와 CPC v2간의 data-efficiency를 보여준다.
- Label-propagation방법의 대부분은 CPC v2보다 현저히 작은 모델을 사용했으므로 공정한 비교는 될 수 없지만, CPC v2가 최고성능보다 뛰어난 성능을 보였다.
4.3 Transfer Learning: Image Detection on PASCAL VOC 2007
Deep Cluster를 제외하고 모두 ImageNet으로 pretrained시켰다. Deep Cluster는 더 큰 데이터 셋으로 학습시켰다.
5. Discussion
- CPC는 data-efficiency를 향상시킨다.
- Augmentation, Optimization, Network Architecture등의 개선의 여지가 많다.
- Linear classification은 data-efficiency를 측정하기에 적합하지 않다.
- CPC는 Image외에도 audio, video, robotic manipulation등에도 적용될 수 있다.
Leave a comment