관련 링크 : https://arxiv.org/abs/1409.4842
Architecture : GoogleNet(2014)
Abstract
본 논문은 Inception이라 명명한 CNN 구조를 제안한다. 이 구조의 주요 특징은 네트워크의 계산 자원을 효율적으로 이용하는 것이다. 이를 위해, Hebbian principle과 multi-scale processing의 직관에 근거하여 구조를 설계했다.
Hebbian principle은 “Neurons That Fire Together Wire Together”로, 하나의 뉴런이 활성화될때는 다른 관련된 뉴런도 활성화됨을 의미한다. 여기서 얻은 직관으로 모든 뉴런을 densly하게 연결할게 아니라, highly correlated된 뉴런들을 sparsely하게 연결하는 구조를 생각해냈다.
실제 시각 세포가 한 이미지를 다양한 스케일로 분석하는것에서도 영감을 얻었다.
1. Introduction
Convolutional networks 덕분에 이미지 인식과 객체 검사의 성능이 좋아지고 있다. 좋은 소식은 이런 발전은 하드웨어가 아닌 새로운 아이디어와 알고리즘, 향상된 네트워크 구조 덕분이란 것이다.
또 다른 주안점은 정확도 보다 효율성에 중점을 둔 알고리즘의 개발이다. 본 논문에서도 합리적인 비용으로 실제 세계에도 적용할 수 있도록 inference time에서 계산 능력에 제한을 두고 모델을 설계했다.
논문에서는 “We need to go deeper”라는 아이디어를 접목시킨 Inception이란 모델을 소개할 것이다. 여기서 deep은 두가지 의미를 가지는데, 첫번째는 Inception Module 도입이고, 두번째는 말 그대로 층의 깊어짐이다.
2. Related Work
CNN은 convolutional layers를 쌓는 전형적인 구조를 가지고, 최근 트렌드는 overfitting을 방지하기 위해 dropout을 이용하면서 층의 깊이와 size를 키우는 것이다. 이 과정은 max-pooling layers를 동반하고, 이는 spatial information을 줄인다. 본 논문은 이를 고려하여, 다양한 size의 학습되는 filter를 사용한다.
Abstract의 intuition of multi-scale processing
Network-in-Network는 NN의 표현력을 증가시키기위한 접근법으로, 1x1 convolutional layers를 추가함으로서 구현할 수 있다. 여기서 1x1 convolutions은 두가지 목적으로 사용된다. 첫번째는 표현력을 증가시키기 위해서, 두번째는 dimension reduction으로 computational bottlenecks을 제거해 층의 깊이와 너비를 증가시키게 해준다.
Network-in-Network에서 conv의 곱$\cdot$합 연산은 선형적이므로 선형적인 특징은 잘 추출해내지만 비선형적인 특징들에는 한계를 가지므로, MLP를 추가해서 비선형적인 특징도 추출할 수 있도록 만들자고 주장한다. 여기서 MLP는 1x1 convolutuional layer로 볼 수 있다. 따라서, 본 논문에서는 1x1 convolutional의 첫번째 목적이 표현력의 증가라고 말했다.
3. Motivation and High Level Considerations
Deep NN의 성능을 향상시키는 가장 직접적인 방법은 크기를 키우는 것이다. 하지만, 이는 두가지 문제점을 가진다. 하나는 큰 사이즈는 네트워크가 overfitting하기 쉽게 만드는 것으로 overfitting을 막기위한 거대한 데이터셋을 만드는건 힘들다. 다른 하나는 네트워크의 크기가 증가하면 연산량은 더 크게 증가한다. conv layer의 경우는 제곱으로 증가한다.
위의 두가지 문제를 모두 해결하기 위한 근본적인 방법은 convolutional layer내부의 fully connected를 sparsely connected 구조로 바꾸는 것이다. 따라서 가장 이상적인 네트워크 구조는 출력의 상관관계를 분석하고 highly correlated된 출력끼리 모은다음 층별로 설계하는 것이다.
이는 Provable bounds for learning some deep representations의 내용으로, 이 논문은 원래 일반적인 NN은 NP-hard인 문제인데, deep NN의 경우에 layer by layer로 correlation statistics를 분석해 large sparse optimal network를 찾으면 문제를 Polynomial Time안에 풀수 있음을 증명했다.
위 방법은 모든 노드를 연결하는게 아니라, 상관관계가 높은 노드들끼리만 연결하는 것. Weight Matrix에서 값이 0에 가까운 것들은 사실 연결할 필요가 없으므로 이런 연결을 없애는 것을 의미하는것 같다.
하지만 컴퓨터는 사각이 아닌 sparse matrix계산을 효율적으로 수행하지 못한다. vision 분야의 머신러닝 시스템들은 convolutuion을 이용해서 spatial domain에서는 sparsity를 이용하는듯 하지만, convolution자체가 dense connections의 모음으로 구현된다.
convolution은 실제 시신경에서 특정 패턴에 특정뉴런이 반응하는 것을 본따서 만들었다. 즉 필터는 특정 뉴런이고, 입력 이미지의 패턴에 일부 필터만 반응하므로(값이 크므로) sparsity를 이용한다고 말 했거나, convolution자체가 patch의 한 픽셀당 각 필터 전체가 아닌 한 픽셀과만 곱해지므로 sparsity하다고 말한 것 같다.
dense connection 부분은 실제구현에서 conv layer의 입력은 3차원이나 4차원이라 계산이 비효율적이다. 따라서, 효율성을 위해 이를 2차원으로 변환후 행렬 내적으로 구현하는데, 행렬 내적은 dense connection이므로 convolutuion은 dens connection으로 구현된다고 말한 것으로 보인다.
ConvNet은 LeNet이후로 symmetry를 깨고 학습을 향상시키기 위해서 feature 차원에서의 random 혹은 sparse connection table을 사용 했다. 하지만, 병렬 계산을 더 최적화하기 위해 AlexNet의 full connection으로 바뀌었다.
Inception 구조는 어떻게 filter-level과 같은 단계에서 sparsely connected 구조를 만들까에서 시작되었다.
4. Architectural Details
Inception 구조의 주요 아이디어는 CNN에서 optimal local sparse 구조가 어떻게 근사화 되고, 이를 쉽게 쓸수있는 dense componenets로 구성할 수 있는가이다.
optimal local sparse 구조를 근사화하기 위해 layer by layer로 highly correlated된 units끼리 clustering하고, 이 cluster들이 다음 layer의 units이 된다. 이를 CNN의 관점에서 보면, 이전 층에서 온 unit은 이미지의 특정 영역이고, 이 unit은 filter bank로 그룹화된다.
filter bank는 입력을 여러 구성 요소로 분리하는 filter 배열을 의미한다. 여기선 correlated된 unit들이 퍼진 정도에 따라 cluster의 크기가 달라 각각 다른 conv로 나타내는 구조를 뜻하는 것 같다.
낮은 층에서는 이미지를 units으로 받고, 이미지는 가까운 픽셀끼리 high correlated하므로 correlated units들이 한 지역에 모여있게 된다. 따라서 이 cluster는 1x1 convolution으로 나타낼 수 있다. 하지만 highly correlated한 units들이 한 지역말고 조금 더 퍼져있을 수 있으므로, 이 cluster는 더 큰 convolution으로 나타낼 수 있다.
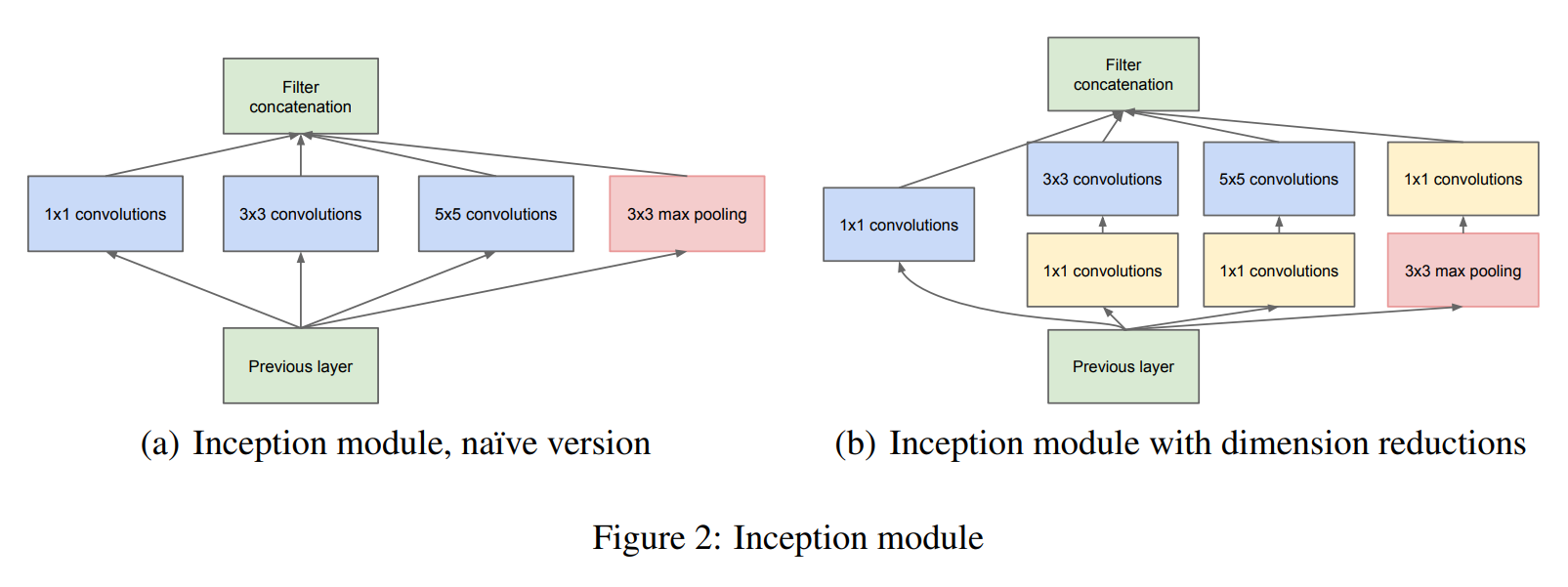
Patch-alignment issues를 피하기 위해, Inception 구조는 1x1, 3x3, 5x5의 필터만 사용한다. 또 최신 모델들이 pooling layer를 사용했으므로, 추가적인 효과를 보기위해 병렬로 추가했다.(Figure 2(a))
2x2 필터를 사용할 경우, 입력과 출력의 resolution을 맞추려면 한쪽만 패딩해야하므로, 편의성을 위해 홀수만 사용하는 것으로 보인다.
Inception modules은 계속 쌓이고, 층이 깊어질수록 이미지가 가지는 correlation statistics는 변하므로 1x1 convolution보다 3x3과 5x5 convolution이 더 많아져야한다.
위에서 언급한대로 모델을 구성하면 Inception module을 지나면 출력의 채널이 급증해 연산량이 과도하게 커질 수 있다. 따라서 1x1 convolutions를 추가해 연산비용이 큰 3x3과 5x5 convolutions이전에 채널수를 줄여주고, ReLU를 동반해서 non-linearity도 올려준다.(Figure 2(b))
추가적으로 단순히 1x1 conv를 사용해서 채널을 줄이면 아무 문제가 없냐고 물을수 있는데, 모델의 초기 filter들을 보면 상당히 유사하게 생겼고 이는 highly correlated하다고 볼 수 있다. 따라서 몇개의 채널이 없어진다고 해도 higly-correlated한 채널이 남아 있으므로 충분히 data를 표현할 수 있다.
일반적으로 Inception network는 위의 module을 쌓는 것으로 이루어져 있지만, 메모리의 효율적 사용을 위해 해상도를 반으로 줄이기도 한다.
결과적으로, 이러한 구조의 장점은 dimension reduction으로 큰 patch size를 효율적으로 사용하고, 시각정보는 다양한 스케일로 처리되어야 한다는 직관을 이용한 것이다. 또 저자는 이 구조가 Inception 구조를 사용하지 않은 유사한 성능의 네트워크보다 2-3$\times$ 빠르게 동작할 수 있음을 확인했다.
5. GoogLeNet
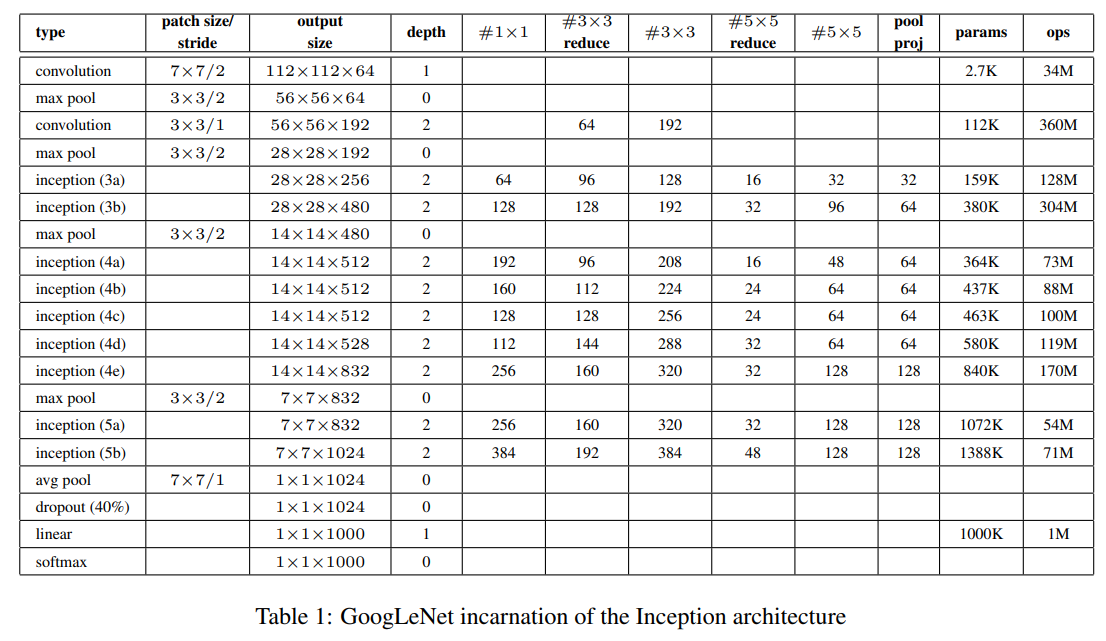
-
입력은 평균을 뺀 RGB 값을 가진 224x224 이미지다.
-
“#3x3 reduce”와 “#5x5 reduce”는 각각 3x3, 5x5 convolution 전에 사용 된 reduction layer의 1x1 filter 개수를 나타낸다.
-
“pool proj” 는 max-pooling 뒤에 따라오는 projection layer의 1x1 filter 개수를 나타낸다.
-
모듈 내부의 모든 convolutions과 reduction/projection layers는 ReLU를 포함한다.
-
Classifier로서 FCL대신에 average pooling을 사용했지만, 범용성을 위해 FCL하나를 더 했고, 이 때문에 Dropout이 필요했다.
average pooling은 Network-in-Network 논문에서 사용한 것으로, 본 논문에서는 top-1 accuracy를 0.6%가 향상되었다.
-
중간층에 보조 분류기를 (4a), (4d)의 출력에 추가해 training시에만 이를 고려하도록 했다. 측면의 네트워크들의 세부사항은 다음과 같다.
이는 상대적으로 얕은 층은 gradient가 잘 전파되는것이 중간층의 특징들이 discriminative하기 때문이라 가정하고, 이를 토대로 깊은 층을 가진 모델 중간에 보조 분류기를 달아서 하위층에 gradient가 잘 전파되도록 의도한 것이다. 보조 분류기에서 계산한 loss는 total loss를 구할때 0.3을 곱해서 더한다.
- Filter size가 5x5이고 strides가 3인 average pooling layer. 출력의 shape은 (4a)와 (4d)에서 각각 4x4x512와 4x4x528이다
- Dimension reduction을 위한 1x1 conv layer(128 filters) 및 ReLU
- FC layer(1024 nodes) 및 ReLU
- Dropout layer (0.7)
- Linear layer에 softmax를 사용한 1000-class classifier.
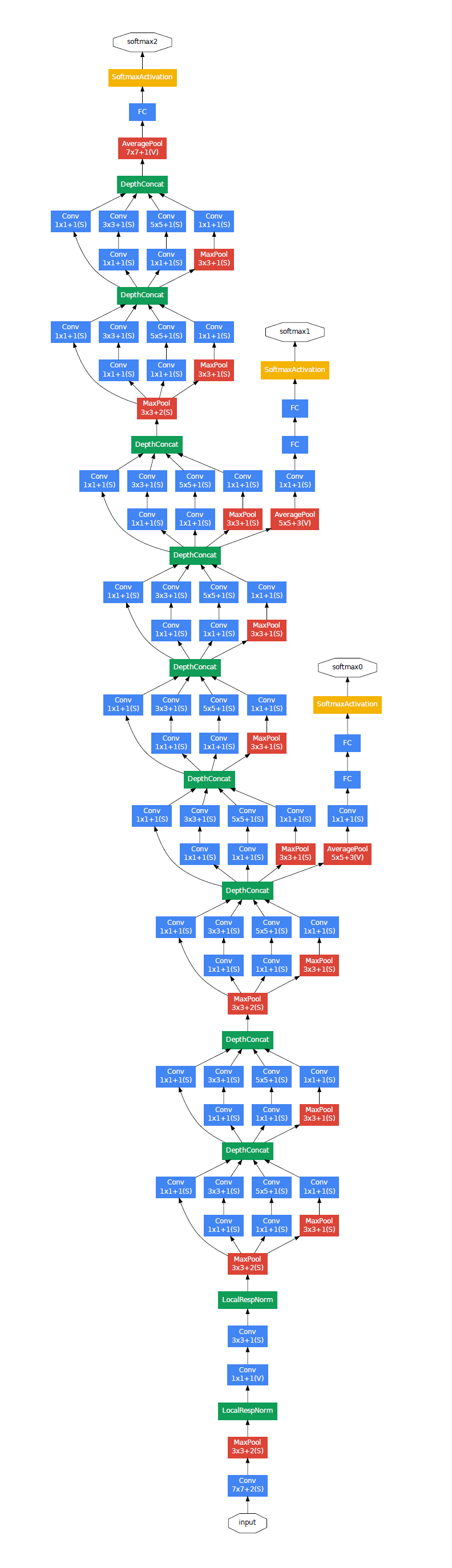
6. Training Methodology
-
학습에선 momentum을 0.9로 한 asynchronous SGD를 사용했고, learning rate schedule은 8 epoch마다 4% 감소하도록 적용했다.
synchronous parameter averaging은 분할된 데이터셋으로 각자 학습한 weight를 모아서 평균을 낸 후, 이를 공식적인 weight로 공표하고 각 worker device 에게 보내 학습을 반복을 하는 방식이다.
이와 대조적으로 asynchronous SGD는 분할된 데이터셋으로 각자 학습한 것을 asynch(비동기적)으로 update하는 방식이다.
-
최종 모델에는 Polyak averaging을 사용했다.
Gradient Descent에서 계곡의 바닥에 도달하지 못하고 진동할때, 각 지점의 평균을 기억해 놓고 평균을 내어 그 값을 사용하는것.
-
종횡비를 [3/4, 4/3]로 제한하여 8% ~ 100%의 크기에서 균등 분포로 patch sampling하했을때 성능이 좋았다.
-
‘photometric distortion’이 overfitting 방지에 유용하다는 것을 발견했다.
빛과 색의 변화에 의해 변하지 않는 특징을 찾기위해 augumentation하는 것을 photometric distortion이라 한다.
7. ILSVRC 2014 Classification Challenge Setup and Results
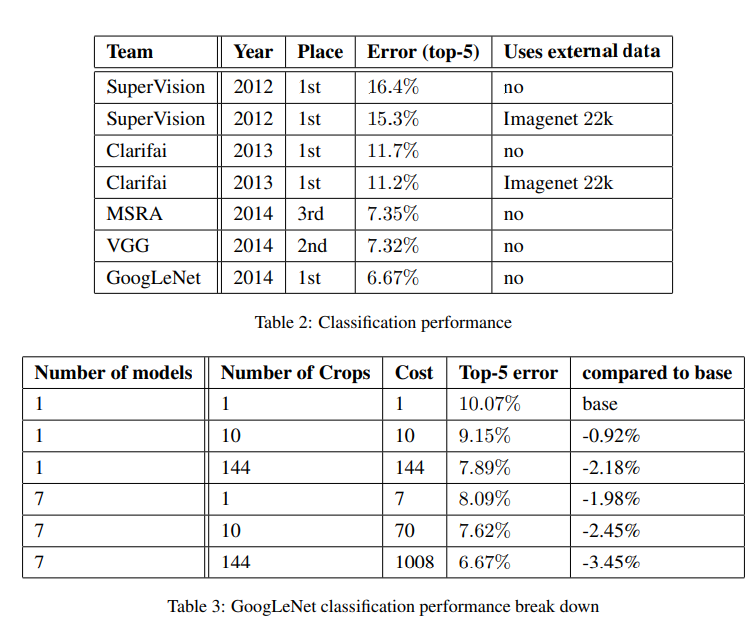
120만장의 testing 이미지, 5만장의 validation 이미지, 10만장의 testing이미지로 이루어진 데이터셋을 이용했고, 외부 데이터는 사용하지 않았다. 과정은 아래와 같다.
- 동일하게 초기화시키고 데이터의 sampling 방법과 input image의 순서만 다른 7개의 모델을 학습시켰다.
- 학습시 이미지를 더 짧은 변을 기준으로 256. 288. 320. 352로 resize하고, 가로로 넓은 이미지의 경우는 정사각형 형태로 왼쪽, 가운데, 오른쪽을 취하고 세로로 긴 경우는 위, 가운데, 아래를 취했다. 각 정사각형마다 각 코너와 가운데를 224x224로 crop한 것과 224x224로 resize한 6개의 이미지를 얻고, 모두 반사시킨 이미지를 얻어 이미지당 $4\times3\times6\times2=144$개의 이미지를 얻었다.
- 최종적 softmax probabilities는 144개의 probabilites를 평균내서 사용했다.
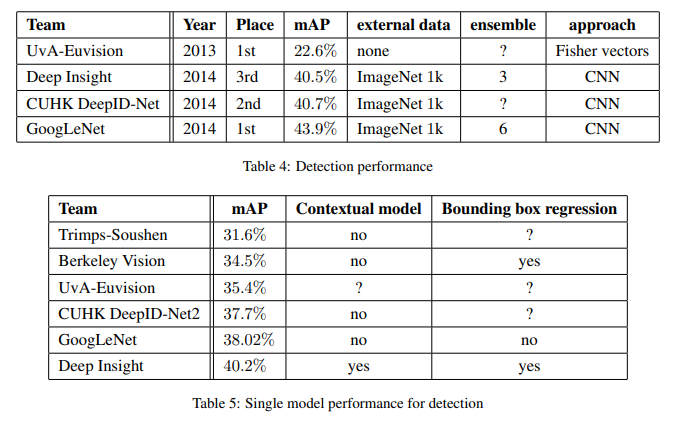
8. ILSVRC 2014 Detection Challenge Setup and Results
ILSVRC detection task는 200개의 class를 가질 수 있는 이미지에서 객체 주변의 bounding boxes를 만드는 것으로, detected된 객채는 정답과 class가 같고 정답 bounding box와 50% 이상 겹쳐져 있어야 한다.
overlap 평가 방식은 Jaccard index로 두 이미지간의 합집합 분에 교집합과 같다.
\[J(A,B)={|A\cap B| \over |A\cup B|}={|A\cap B| \over |A|+|B|-|A\cap B|}\]
region proposal step은 multi-box prediciotns을 사용한 selective search를 이용했고, region classifier는 Inception module로 보강했다. Superpixel의 크기를 두배로 늘리고, mult-box predictions에서 나온 region proposal까지 더해 기존 R-CNN보다 적은 수의 proposal로 coverage는 1% 올렸다.
- Selective search는 색감, 질가의 차이, 다른 물체로 둘러쌓여 있는지 여부를 파악해서 bounding box들을 만들어 주는 알고리즘이다.
- Superpixel은 pixel들을 색 등의 저레벨 정보를 바탕으로 비슷한 것끼리 묶어서 ‘커다란 pixel’을 만드는 작업이다. 이 ‘커다란 pixel’들은 추후의 이미지 처리 과정에서 마치 하나의 pixel처럼 다루어지게 된다
9. Conclusion
논문은 쉽게 쓸수 있는 dense building blocks으로 optimal sparse structure를 근사하는것이 computer vision 분야의 NN의 성능을 향상시키는 방법임을 증명했다. 이 방법은 더 얕거나 좁은 층의 네트워크와 비교했을때 약간의 연산량 증가만으로 많은 성능향상을 얻었다. 결과적으로, 기존 구조에서 sparser 구조로 바꾸는게 일반적으로 실현 가능하고 유용함을 알 수 있다.

Leave a comment