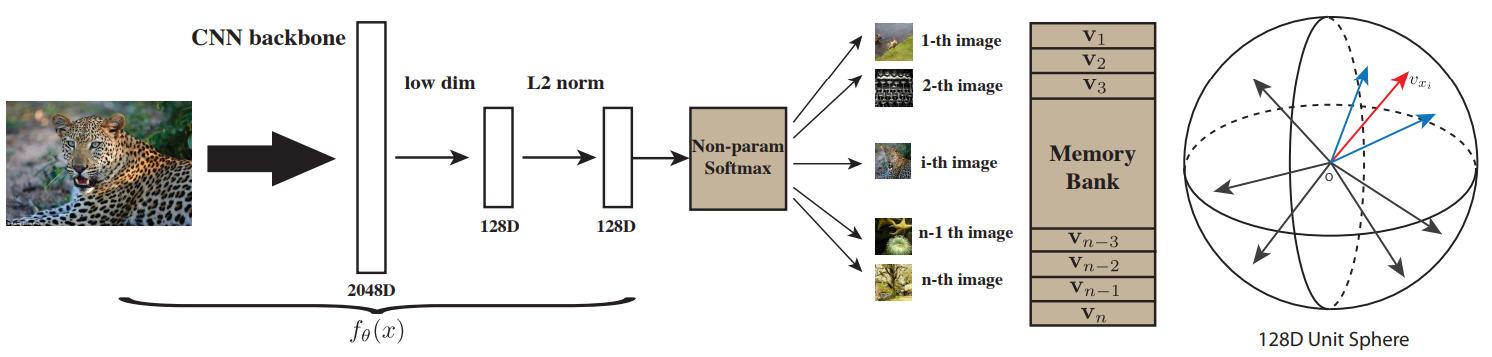
관련 링크 : https://arxiv.org/abs/1603.09246
Self-supervised Learning : Jigsaw puzzle(2016)
Abstract
논문은 라벨링 없는 데이터를 이용한 self-supervised learning을 연구한다. 이를 위해 pretext task로 Jigsaw 퍼즐을 풀도록 학습되는 CNN을 설계하고, 이를 객체 분류 및 검출을 위한 모델로 재구성시켰고 AlexNet보다 더 적은 파라미터를 가지고 유사한 성능을 냈다.
Pretext Task : 네트워크가 해결할 수 있도록 사전 디자인된 문제, 시각적인 특징들이 이를 통해 학습된다.
1.Introduction
Visual task를 supervised learning로 접근하면 성공적으로 해결할 수 있음은 증명되었다. 하지만 이를 위한 라벨된 데이터를 만드는건 비용이 많이 들기 때문에 라벨되지 않은 데이터를 이용한 unsupervised learning이 각광받고 있다.
주요 아이디어는 데이터 내에서 자유롭게 사용할 수 있는 라벨을 활용해 범용 특성을 학습하는 것이다. 세 가지 정도의 예시가 있는데, 다음과 같다.
| 원문 | 원문 | 원문 |
|---|---|---|
 |
 |
 |
왼쪽부터
- 각 patch의 상대적인 위치를 라벨로 사용하는 방법. 두 이미지를 입력으로 받아 학습한다.
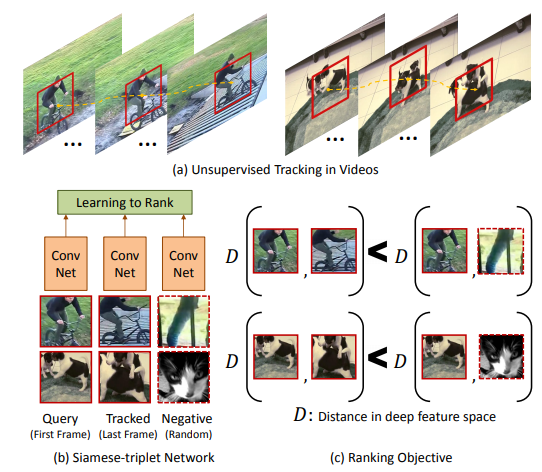
- 비디오 안에서 원래 객체 이미지, 다른 화면의 객체 이미지, 랜덤 이미지를 비교해 랜덤한 이미지와의 distance보다 다른 화면의 이미지와의 distance를 최소화 하도록 학습시키는 방법. 그림처럼 원래 이미지, 다른 화면의 객체 이미지, 랜덤 이미지를 입력으로 받는다.
- 카메라의 움직임에 따라 다른 이미지를 쌍둥이 NN에 넣고, 그 결과를 concat하여 NN에 넣어서 이미지를 보고 카메라의 움직임을 예측하도록 학습시키는 방법. 위의 사진처럼 두 이미지를 입력으로 받는다.
본 논문에서는 Jigsaw puzzle reassembly를 pretext task로 사용한다. 그 과정은 다음과 같다.

(a)로 만든 타일을 이용해서 (b) 같이 섞어 퍼즐을 만들고, 네트워크가 이를 (c)처럼 맞추도록 학습시킨다.
이 방법은 네트워크에게 객체가 어떤 요소들로 이루어졌고, 그 요소들이 무엇인지를 가르친다. 물론 각 퍼즐 타일과 객체의 일부를 연관시키는 것은 얼핏 이상하게 들리지만, 특정 요소의 위치를 예측하려면 객체를 먼저 이해해야고. 전체 타일을 봤을때 타일의 위치는 명확하므로 네트워크가 상대적인 위치를 성공적으로 예측했다면 객체에 대한 이해가 높다고 생각할수 있다.
또한 이 방법은 위의 예시중 첫번째 방법보다 빠르게 학습시킬 수 있고, chromatic aberration을 조정하거나 pixelation에 영향을 받아도 상관이 없다는 장점을 가졌다.
chromatic aberration : 렌즈가 모든 색상을 동일한 지점에 초첨맞추지 못하는 현상으로 각 색상채널에서 올바르게 위치하지 못하고 조금씩 밀려있게 됨
pixelation : 이미지를 확대했을때 이미지가 각각의 픽셀로 보이는 현상
Chromatic aberration pixelation

2. Related work
Unsupervised Learning
일반적으로 Unsupervised learning methods는 probabilistic, direct mapping, manifold learning으로 분류될 수 있다.
- Probabilistic : 실제 현상들이 보여지는 것과는 별개로, 숨겨진 의미가 있고, 실제 현상이 어떤 분포를 이룬다면 이는 숨겨진 의미에 의해 만들어진다는 가정에서 시작한다. 주어진 보여지는 것들에서 숨겨진 의미의 likelihood가 최대가 되도록 학습시킨다. 대표적인 예로를 RBM이 있다.
RBM : 입력데이터의 분포와 은닉층에 의해 재구성된 데이터의 분포가 유사하도록 만드는 가중치 W를 조절하는 방법으로, 이 과정을 거치면 은닉층은 feature가 된다. 다만 구현상에서 지수적인 time complexity를 가지므로 비효율적이다.
- Direct mapping : Probabilistic의 RBM이 효율적으로 feature를 만들지 않기떄문에 이를 개선한 방법으로 Autoencoder가 그 예시다.
Autoencode : 입력에서 feature를 뽑아내는 encoder와 이렇게 뽑아낸 feature로 입력을 복원하는 decoder로 이루어져 있다. 입력과 decoder의 출력을 비교해서 같아지도록 학습시킨다. encoder에서 입력보다 적은 차원을 가지도록 feature를 뽑아서 decoder가 제한적인 정보로 복원해야 하기 때문에 encode는 원래 입력에서 유의미한 feature를 뽑아낼 수 있다.
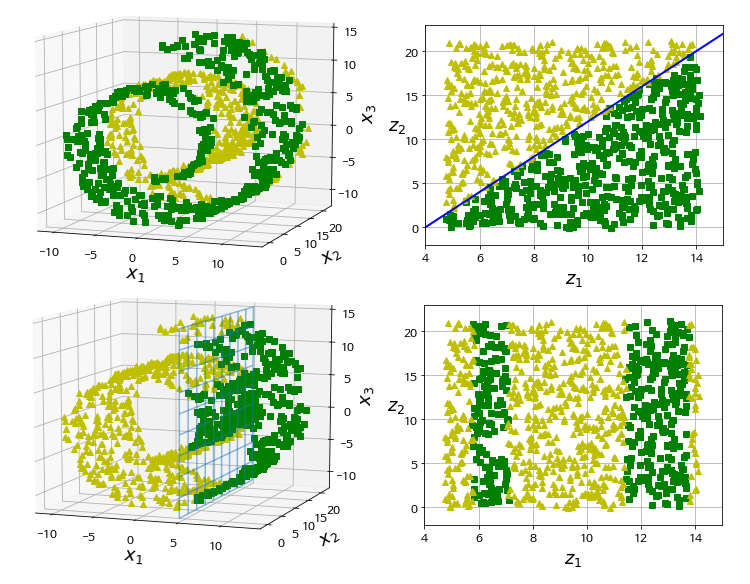
- Manifold Learning : 고차원 공간에 내재한 저차원 공간은 manifold라고 한다. manifold learning은 기존 데이터보다 높거나 낮은 차원에서 manifold를 찾는 것으로, 다음 사진과 같다.
Self-supervised Learning
Unsupervised learning의 한 분야로, 데이터에서 얻어낸 라벨을 가지고 학습시키는 방법을 뜻한다. 대표적인 예시 세가지는 도입부에서 설명했으므로, Jigsaw puzzle problem과의 차이만 설명하겠다.
- 첫번째 방법은 한번에 두 이미지를 비교하므로, 위의 호랑이 그림에서 (c)의 좌측 상단과 중앙 상단의 그림을 명확히 구분하기 힘들지만 jigsaw puzzle은 한번에 모든 타일을 보기때문에 명확히 구분할 수 있다.
- 두번째 방법과 세번째 방법은 한 비디오에서 사진을 뽑아서 쓰기 때문에, 서로 다른 비디오에서의 동일한 물체의 경우 유사하다고 판단하지 않는다. 즉, 이미지의 high-level feature보다 유사도(색상이나 질감)에 관심이 있다. 하지만 jigsaw puzzle은 두 이미지를 비교하지 않으므로 더 좋은 feature를 배울 수 있다.

두번째 방법과 세번째 방법은 위의 두 사진을 다르다고 판단하겠지만, jigsaw는 같다고 판단한다.
Jigsaw Puzzle
Jigsaw Puzzle은 1760년대부터 어린이들의 학습을 위해 이용되었고, 사람의 시각 능력을 측정하는데 사용되었다. 따라서, 본 논문도 객체의 특징을 잡아내는 방법으로 이를 이용했다.
Jigsaw Puzzle을 푸는 방법에 관한 연구들이 타일의 모양이나 경계면에서의 질감에 초점을 맞추었으나 효과가 크지 않았으므로, 논문에서는 solver를 학습할때 이런 부분은 피하도록 했다.
3. Solving Jigsaw Puzzles
네트워크의 인풋으로 9개의 타일을 채널에서 concat한 27채널을 사용 할 수 도 있었지만, 이 경우 고차원적인 특징을 사용하지 않고 타일간의 저차원 특징만 사용하는 문제가 발생했다. 따라서, 처음에는 각 타일의 특징들을 뽑아내고 마지막에 이를 이용해서 Jigsaw puzzle을 해결하는 구조를 사용했다.
저차원 특징은 유사한 구조적인 패턴이나 타일 경계면에서 질감등을 의미하는데, 이는 Jigsaw puzzle을 푸는데는 유용하지만 객체 전체를 이해하는데는 불필요한 정보이다.
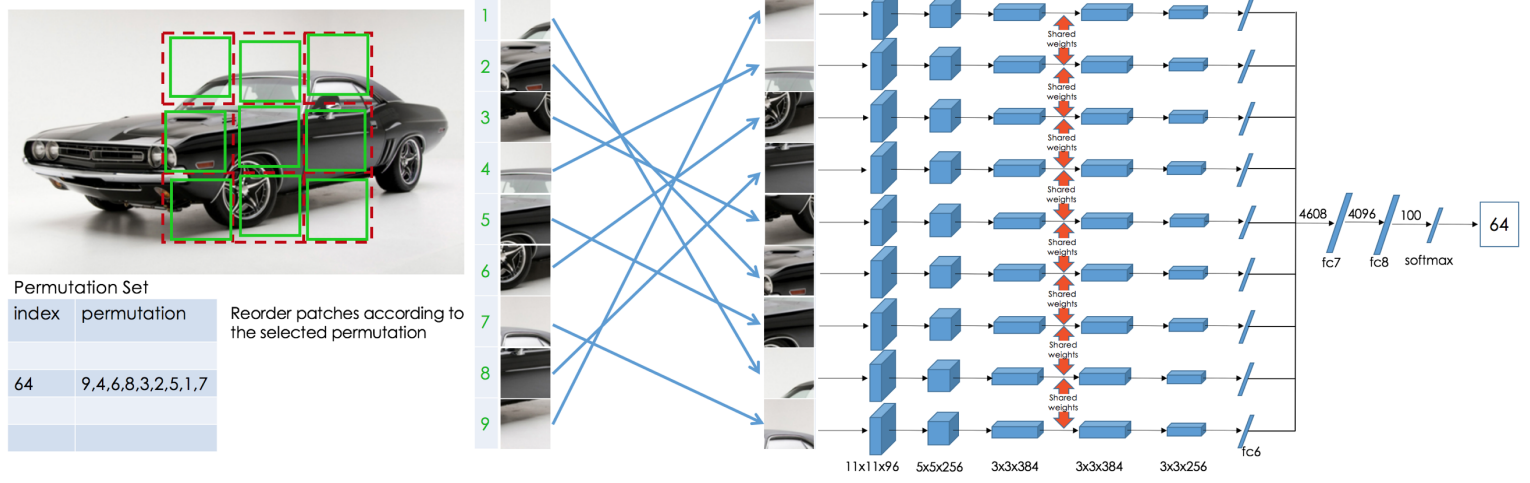
네트워크의 구조는 위와 같다. 학습시 이미지에서 225x225의 이미지를 무작위로 crop하고 이를 3x3 grid로 나눈 후, 각 grid에서 무작위로 64x64로 crop한 것을 하나의 타일로 이용해 총 9개의 타일을 만든다. 그리고 이 타일을 사전 정의된 순서 세트에서 하나에 따라서 재정렬 후 네트워크에 입력으로 넣는다. 네트워크 세부사항은 대부분 Alexnet을 따랐다.
3.1 The Context-Free Architecture
위 그림에서 fc6까지는 모두 shared weights를 사용하고, 정보의 흐름이 명시적으로 나뉘어져 있고 context는 fc7에서야 사용되므로 이 구조를 context-free network라 한다. 테스트시에는 학습할때와 다르게 이미지 전체를 225x225로 resize한 후, 각 grid에서 무작위로 crop하지 않고 전체 75x75를 쓴다.
결과적으로 Alexnet보다 적은 파라미터를 가지고 비슷한 성능을 이끌어냈다.
Alexnet의 fc6 : 37.5M, top-1 : 57.4%
CFN의 fc6 : 2M, top-1 : 57.1% (fc7은 CFN이 2M정도 더 많음)
3.2 The Jigsaw Puzzle Task
CFN을 학습시키기 위해, Jigsaw puzzle permutations를 정의하고 이를 각 타일에 인덱스로 할당했다. 그리고 CFN이 각 인덱스의 확률값을 벡터로 반환하도록 학습시켰다. 하지만 9개의 타일이 가질수 있는 순서의 경우의 수는 $9!=362,880$이므로 모든 경우를 따지기 어렵고, 후속연구로 이것을 적절히 제한하는게 성능에 영향을 준다는 것을 확인했다.
3.3 Training the CFN
CFN의 출력은 객체 일부의 공간적인 배치를 뜻하는 조건부 확률 밀도 함수로 표현할 수 있다.
\[p(S|A_1, A_2,\ldots, A_9) =p(S|F_1,F_2,\ldots,F_9)\prod_{i=1}^9 p(F_i|A_i)\tag 1\]$S$는 타일의 배치, $A_i$는 타일의 $i$번째 외관, $\{ F_i\}_{i=1,\ldots,9}$는 중간층의 특징을 뜻하고, 학습의 목표는 각 타일 사이의 상대적인 위치를 식별할 수 있도록 $F_i$가 의미있는 특징이 되는 것이다. 만약 $S$가 이미지당 하나뿐이라면, CFN은 의미있는 특징을 배울 필요가 없어 위치정보만을 기억한다. 이 경우 $S=(L_1,\ldots,L_9)$라고 할때, 각각의 $F_i$가 위치정보만을 의미하므로 (1)식이 다음과 같이 바뀐다.($L_i$는 $F_i$로만 결정되는 타일의 위치를 뜻함)
\[p(L_1,\ldots,L_9|F_1,F_2,\ldots,F_9)=\prod_{i=1}^9 p(L_i|F_i) \tag 2\]우리가 원하는것은 CFN이 이미지의 고차원적인 특징들을 학습하는 것인데, 이미지당 퍼즐 구성이 하나라면 CFN은 고차원적인 특징을 학습하고 이를 이용해 퍼즐을 풀기보다 각 이미지가 어떤 위치를 뜻했는지만 기억하면 되므로 학습이 제대로 이루어지지 않는다는 이야기같다.
간단히 말하면 pre-text task만을 손쉽게 해결하기 위한 shortcut이 생긴다. 이런 shortcut은 가장자리의 연속성이나 pixelation/색 분포, chromatic aberration등의 저차원 특징들을 이용하는 것 등이 있는데, 이를 해결하기 위해서 여러 방법들을 사용했다.
- 이미지가 절대적인 위치를 학습하는것을 피하기 위해, 이미지당 가능한 1000개의 배치중 평균적으로 69개의 배치를 사용했고, 각 배치들은 평균적으로 충분히 큰Hamming distance를 가지도록 선택했다.
- Pixelation/색 분포, 가장자리 연속성을 피하기 위해, 각 타일당 평균적으로 11 pixel 차이나도록 crop했다.
- chromatic aberration을 피하기 위해, grayscale 이미지를 이용한 color channel jittering을 이용했다.
자세한 사항은 4.2에서 설명한다.
Hamming distance :
- ‘1011101’과 ‘1001001’사이의 해밍 거리는 2이다.
- ‘2143896’과 ‘2233796’사이의 해밍 거리는 3이다.
- “toned”와 “roses”사이의 해밍 거리는 3이다.
3.4 Implementation Details
- BN없이 SGD를 사용했다. learning rate는 0.01로 350k iteration 후 학습이 끝났다.
- 1.3M개의 256x256 color 이미지를 batch size는 256으로 사용했다. 그보다 큰 이미지는 더 짧은쪽을 256으로 resize한 후 나머지는 잘랐다. 학습동안 한 이미지당 69개의 Jigsaw puzzles을 풀었다.
4. Experiments
transfer learning에서 성능을 평가하고, ablation study를 수행하고, 중간층의 뉴런들을 시각화하고, 다른 방법들과 비교했다.
ablation study : 모델이나 알고리즘의 feature들을 제거하면서 그것이 성능에 어떤 영향을 줄지 연구하는 것
4.1 Transfer Learning
self-supervised learning을 이용해 학습한 CFN으로 Alexnet의 conv layer를 초기화하고, 나머지 층은 가우시한 분포를 가지도록 초기화시켜서 다시 학습시켰다. 이 과정에서 CFN은 첫번째 층에서 stride 2를 사용했지만 여기선 다른 방법들과 비교를 위해 첫번째 층의 stride가 4인 표준 AlexNet 구조를 이용했다.
Pascal VOC

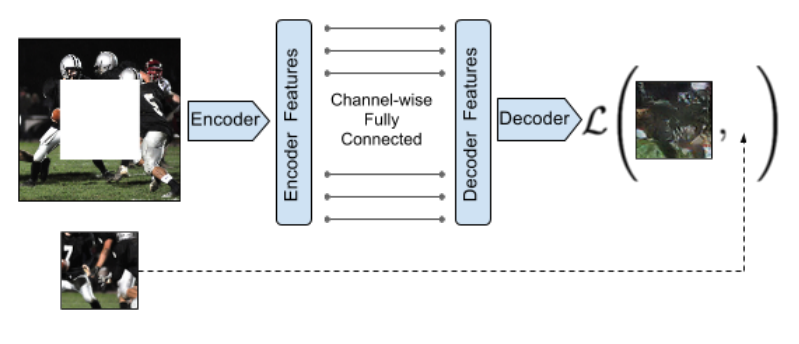
[39]는 도입부에서 언급한 방법중 두번째 방법, [10]은 첫번째 방법, [30]은 context-encoder로 다음 사진으로 설명된다.
| 원문 |
|---|
 |
ImageNet Classification
다른 연구에서 AlexNet의 마지막층은 task와 dataset에 specific하고 첫번째 층은 범용적임을 보였다. 이를 transfer learning의 맥락으로 확장해서 특정 네트워크의 파라미터를 고정시켜 학습해 네트워크에서 특징들을 뽑아내는 곳이 어디인지를 확인해본다. Jigsaw->Classification과 Classification->Jigsaw 모두 확인한다.


위는 Jigsaw->Classification, 아래는 Classification->Jigsaw이다. $j$번째 열은 conv 1부터 conv $j$까지 모두 고정시켰을때의 결과를 뜻한다.
4.2 Ablation Studies
Permutation Set
$S$의 구성이 다양해야함은 위에서 설명했으므로 실험에서 사용한 방법을 소개하겠다. 세가지의 기준을 가지고 $S$를 구성했다.
-
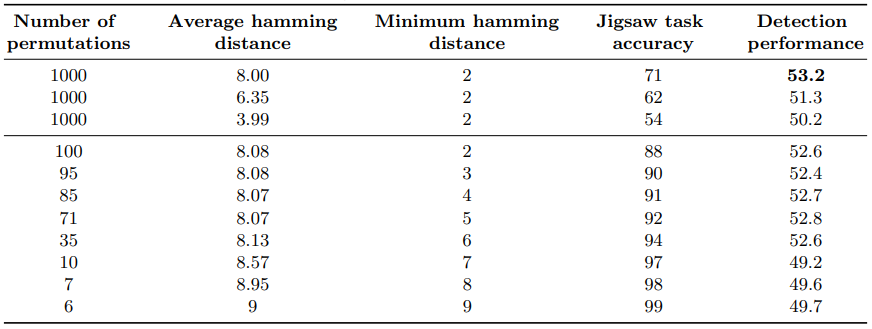
Cardinality : $S$의 수에 따른 영향을 파악하기 위해 다양한 개수로 네트워크를 학습했다. 개수가 많을수록 Jigsaw task의 성능이 내려가고 detection task의 성능이 올라감을 확인했다.
-
Average Hamming distance : 각 순서의 Hamming distance에 따라 1000개를 선택해서 사용했고, Hamming distance의 평균이 높을수록 Jigsaw task와 detection task 성능이 올라감을 확인했다. 1000개를 선택할때는 다음 알고리즘을 이용했다.

- Minimum hamming distance : 서로 유사한 순서는 task를 어렵게 만들기 떄문에 이를 삭제해서 minimum distance를 증가시켰다.
세 기준에 따른 결과는 다음과 같다.
Preventing Shortcuts
위에서 언급한 shortcuts을 예방하기위해 사용한 방법들을 소개하겠다.
- Low Level statistics : 근접 타일끼리는 pixel의 평균과 표준편차가 유사할 것이므로 각 타일마다 normalize 해준다.
- Edge continuity : 85x85 이미지에서 64x64를 crop해서 사용해 타일간 21 pixel 차이가 나도록 한다.
- Chromatic Aberration : 이를 예방하기위해 세가지 방법을 사용했다.
- 원본 이미지의 가운데를 잘라서 255x255로 resize했다.
- RGB와 grayscale 이미지를 3:7로 학습했다.
- 각 타일의 pixel에 무작위로 0, 1, 2를 더하거나 빼는 color jittering을 했다.
위의 방법을 도입한 결과는 다음과 같다.

4.3 CFN filter activations
최근에 CNN의 작동 원리를 이해하기위한 시각화 연구들이 많아졌다. 따라서, 본 논문에서도 각 층의 unit을 object detector로서 생각하고 CFN의 activation을 분석해 본다. 먼저 ImageNet 검증 데이터셋에서 1M개의 patch(무작위로 뽑은 64x64 이미지)를 뽑고 CFN에 넣는다. 그 후 입력에 따른 각 층의 출력을 l1 norm으로 계산해서 순위를 매겨서 가장 높은 16개의 patch를 선택한다. 각 층의 채널은 여러개이므로 6 채널을 선정했고, 그 결과는 다음과 같다.

(a)와 (b)는 다양한 형태의 질감에 전문화 되있고, (c)는 질감 뿐만 아니라 detector로도 동작한다. (d)는 의도적으로 dog part detector만 골랐는데, 부위별로 잘 나뉘어져 있음을 볼 수 있다. (e)도 detector로 동작한다. (f)와 (g)는 필터의 모습을 시각화했다.
4.4 Image Retrieval
이 챕터에서는 이미지 검색에서 CFN의 특징들을 정성적/정량적으로 평가한다.
정성적으로 평가하기 위해 PASCAL VOC 2007 테스트 데이터를 질문으로 사용해서 각 질문이 입력으로 들어갔을때 normalized feature와 내적한 값이 가장 큰 이미지 4개를 각 방법에 따라 나타낸다.

(a)는 질문, (b)는 AlexNet, (c)는 CFN, (d)는 relative location[10], (e)는 video tracking[39], (f)는 AlexNet with random weights이다.
정량적으로 평가하기 위해 precision-recall 그래프를 그렸다. CFN과 [10]이 거의 동일한 성능을 보이는 것 같지만 측정 방법이 달라졌을때 CFN이 더 성능이 좋은것은 4.1의 ImageNet Classification 부분에서 확인했다.
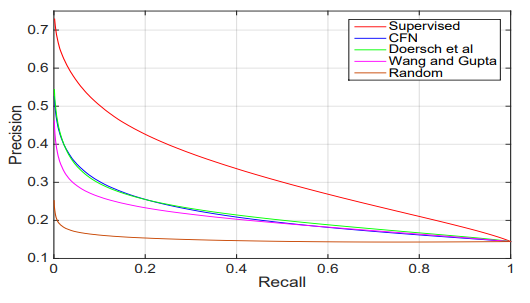
Precision-Recall은 다음과 같다.
5. Conclusions
본 논문은 Jigsaw puzzle reassembly task를 detection/classification task로 쉽게 전환 할 수 있는 CFN을 도입했고, CFN은 unsupervised learning을 통해 학습시켰다. 이렇게 학습된 네트워크는 유의미한 특징들을 이용할 수 있었고, 기존 unsupervised learning 방법들보다 뛰어나며 supervised learning에 근접한 성능을 보였다.
Leave a comment