관련 링크 : https://arxiv.org/abs/1901.09005
Self-Supervised Learning : Revisiting SSL(2019)
Abstract
최근 각광받고있는 Self-supervised learning paper들은 pretext를 제안하는데 초점이 맞춰져있고, 연구에 사용되는 CNN 모델의 영향에 대해서는 별다른 관심을 가지지 않는다. 따라서 본 논문에서는 기존의 많은 self-supervised method에 CNN 모델을 바꾸는 등의 다양한 실험을 진행한다.
1. Introduction
Self-supervised learning은 pretext task를 이용해 모델을 학습시킨다. 이는 pretext task를 풀기 위해서는 이미지에 대한 고차원적인 이해가 필요하고, 이를 해결하기 위해 학습된 representation이 실제로 풀려고하는 downstream task에도 유용할 것이라는 생각에서 시작되었다. 따라서 대부분의 연구는 더 나은 pretext task를 찾는데 초점을 맞췄다.
하지만 본 연구에서는 학습에 사용되는 CNN 모델에 관해 연구를 진행하고, 다음과 같은 중요한 통찰을 얻었다.
- Supervised와 Self-supervised에서 CNN 모델이 미치는 영향이 다르다.
- AlexNet과 달리 ResNet에서는 출력에 가까운 층의 feature를 이용할때 성능이 저하되지 않는다.
- 모델의 크기를 키우면 representation의 질도 좋아진다.
- Representation을 fixed하고 학습한 linear classifier는 lr에 민감하고 학습이 오래걸린다.
2. Related Work
-
Self-supervised method in image : Context predict/Jigsaw puzzle/Rotation/Deep Clustering/Counting
-
CNN model : ResNet v1, v2/RevNet/VGG
ResNet v1/ResNet v2 RevNet Foward/Backward Computation 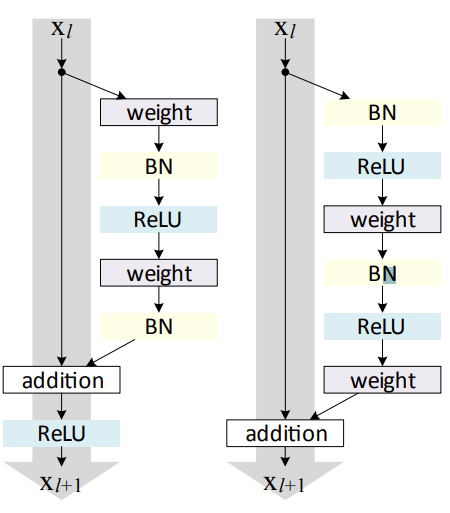
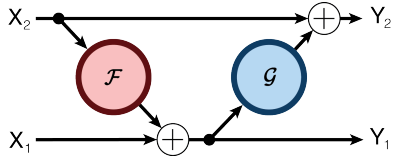
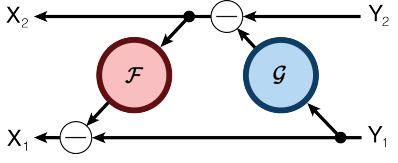
3. Self-supervised study setup
3.1 Architectures of CNN models
실험에는 6개의 CNN 모델이 사용되었다. 예비실험에서 ResNet은 네트워크의 마지막단에서 self-supervised 성능이 저하되지 않았고, 이는 skip-connection이 residual unit을 invertible하게 만들기 때문이라고 추측했다. 따라서, invertiblility를 증가시킨 모델을 사용한다.
Invertible하다는 것은 각 층의 출력을 저장하지 않고 다음 층의 출력에서 계산해서 이용할 수 있다는 것을 의미한다. 일반적인 CNN이라면 입력과 출력의 resolution이나 channel이 다르지만 ResNet의 경우 skip-connection을 구현하기위해 둘 다 같아야하고, 따라서 invertible 하다.
ResNet
$\mathrm {Conv-Conv-Conv} \;\text {with shorcut}$을 residual unit이라 할 때, 각 $3$, $4$, $6$, $3$개의 unit을 가지는 $4$개의 블럭으로 구성된 ResNet-50을 사용한다. 첫번째 layer는 $7\times7 \;\mathrm {Conv}$로 $16\times k$의 출력 채널을 가진다. 이때 $k$는 widening factor라 부르고, 별다른 언급이 없으면 4로 사용한다. 마지막 layer는 $\mathrm {GlobalAvgPool}$로 $512\times k$의 벡터를 만든다. 마지막 layer는 task-specific한 classifier 바로 직전이므로 출력을 pre-logits이라고 부른다.
-
각 $\mathrm {Conv}$는 $\mathrm {BN-ReLU}$를 포함한다.
- $k \in \{4, 8,12,16\}$을 사용하므로 pre-logits이 만드는 출력의 크기는 $2048, 4096, 6144, 8192$이다.
- 위 unit의 순서를 반대로 적용한 모델을 $ResNet\;v2$, 원래 모델을 $ResNet\;v1$으로 사용한다.
- $\mathrm {GAP}$전에 $\mathrm {ReLU}$를 뺀 모델은 (-)로 표시했다.
RevNet
RevNet은 입력의 채널을 두개로 분리시켜 Relative Work의 그림처럼 적용하는 모델이다. 그림과 같이 Forward/Backward를 정의해서 각 layer의 activation을 다음 layer의 activation으로 구해 중간 layer의 activation을 저장할 필요가 없어 메모리를 효율적으로 사용한다. 논문에서는 $\mathcal G$는 사용하지 않은 모델을 이용한다.
- $RevNet$의 깊이와 너비는 $ResNet$과 동일하게 사용한다.
- Supervised에서 $ResNet$보다 약간 떨어지거나 비슷한 성능을 보인다.
VGG
각 $2$, $2$, $4$, $4$, $4$개의 $\mathrm {Conv}$를 가지는 5개의 블럭과 3개의 FCL로 구성된 VGG19를 사용한다. 두번째부터 다섯번째 블럭의 출력을 block1부터 block4로 부른다. ResNet처럼 마지막 FCL의 입력을 pre-logits이라고 부르고, widening factor $k=8$을 기본으로 사용한다.(첫번째 $\mathrm{Conv}$의 출력은 $8\times k$, 따라서 FCL의 채널수는 $512 \times k$)
- 각 $\mathrm {Conv}$는 $\mathrm {BN-ReLU}$를 포함한다.
- 각 블럭 사이에서 $\mathrm {maxpool}$해준다.
3.2 Self-supervised techniques
- Rotation : 이미지를 $\{0^\circ, 90^\circ, 180^\circ, 270^\circ\}$ 회전시키고 이미지에 적용된 회전의 종류를 예측하는 방법.
- Exempler : 하나의 이미지에 많은 data augmentation을 이용해 많은 이미지를 만들고, 그렇게 만든 이미지를 같은 라벨로 생각하고 학습시키는 방법. 같은 라벨의 이미지는 같게, 다른 라벨의 이미지는 다르도록 triplet loss를 사용한다.
- Jigsaw : 이미지를 9개의 패치로 나누고 무작위로 섞은후 정확한 순서를 예측하는 방법. 모델이 예측해야하는 순서의 종류는 100으로 제한한다.
- Relative Patch Location : 이미지를 9개의 패치로 나누고, 중앙 패치와 나머지 8개 패치 사이의 위치 관계를 예측하는 방법.
3.3 Evaluation of Learned Visual Representations
-
Pretext Optimizer는 SGD를 사용한다.
-
momentum : $0.9$, lr : $0.1$ , total epoch : $35$
-
lr은 15, 25 epoch마다 1/10로 줄인다. 초기 5 epoch동안은 lr를 linear하게 증가시킨다.
초기 iteration동안 lr을 linear하게 증가시키는 것을 learning rate warm-up이라함.
-
Batch size는 pretext task마다 다르게 사용하고, 사용된 Batch size $B$에 따라 lr에 $B \over {256}$을 곱해준다.
-
-
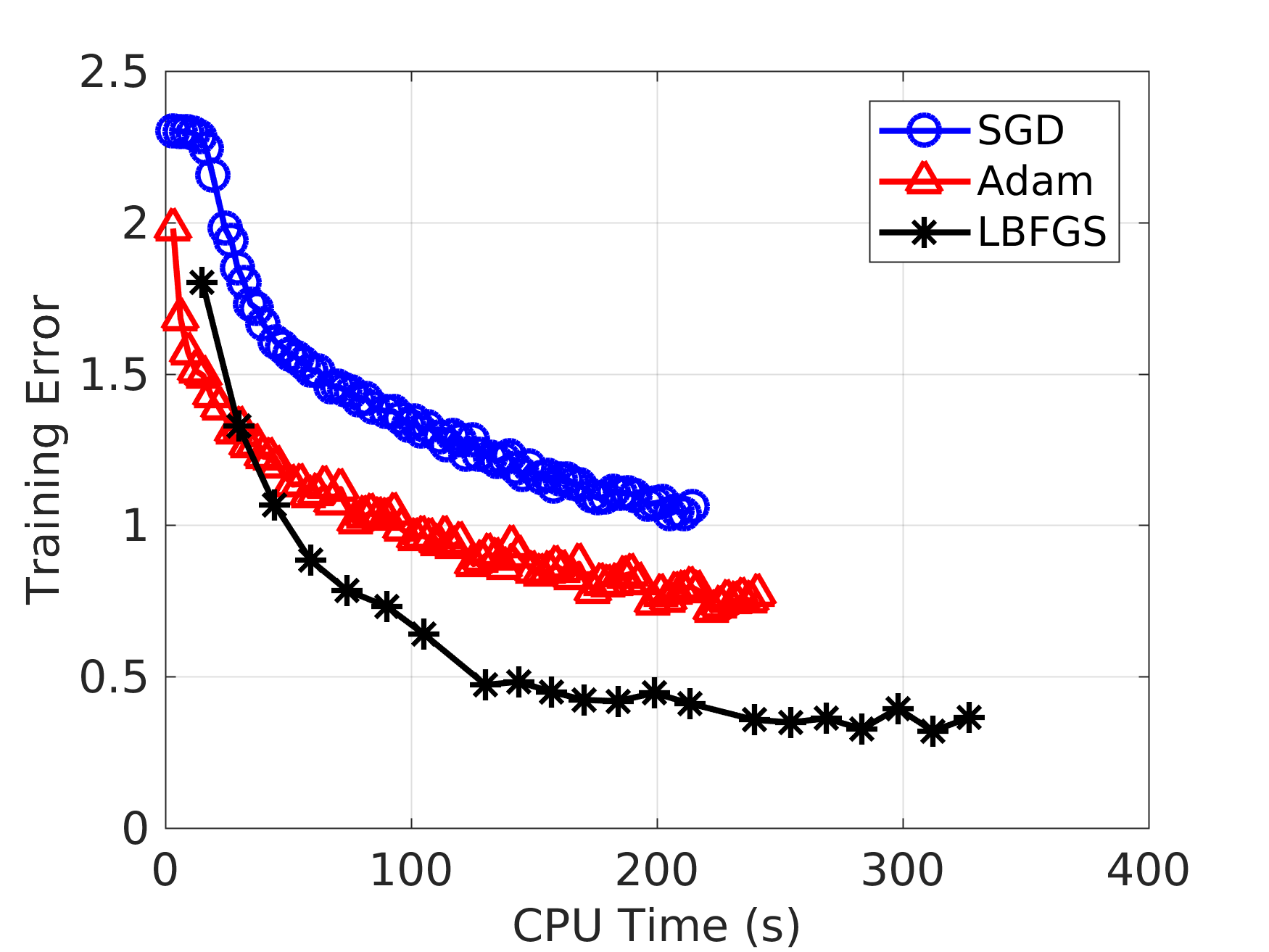
Downstream task를 학습시킬때는 L-BFGS를 사용한다.
Full Batch Mini Batch
3.4 Datasets
-
ImageNet
-
1.3M with 1000 class for training
-
50000 for validation and test
Official test set은 비공개이므로 validation을 test로, training set에서 뽑은 이미지 셋을 validation으로 사용한다.
-
-
Places205
-
2.5M with 205 class for training
-
50000 for validation and test
ImageNet과 동일하게 사용
-
4. Experiments and Results
ImageNet으로 pretext task를 수행하고, Places205와 ImageNet의 downstream task 성능을 평가한다.
4.1 Evaluation on ImageNet and Places205
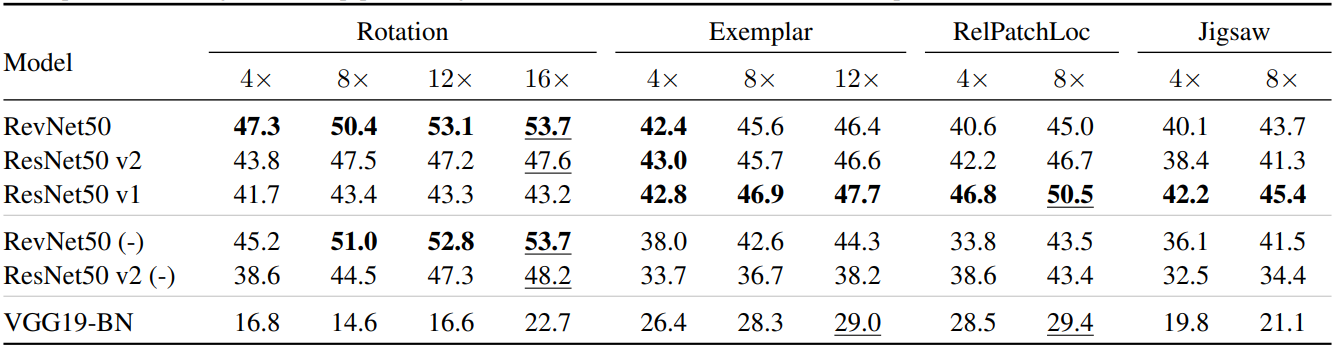
Downstream task for ImageNet, 각 열에서 굵은 글씨와 각 행에서 밑줄은 최고성능을 뜻한다.
-
Supervised learning에서처럼 모델의 채널을 증가시키면 성능이 증가한다.(가장 큰 $k$에서 최고 성능)
-
여러 방법에서 모델의 순위가 일정하지 않고, 여러 모델에서 방법의 순위도 일정하지 않다.
-
ImageNet과 Places205에서 성능 변화 양상이 비슷한 것으로 보아 일반화 성능이 좋다.
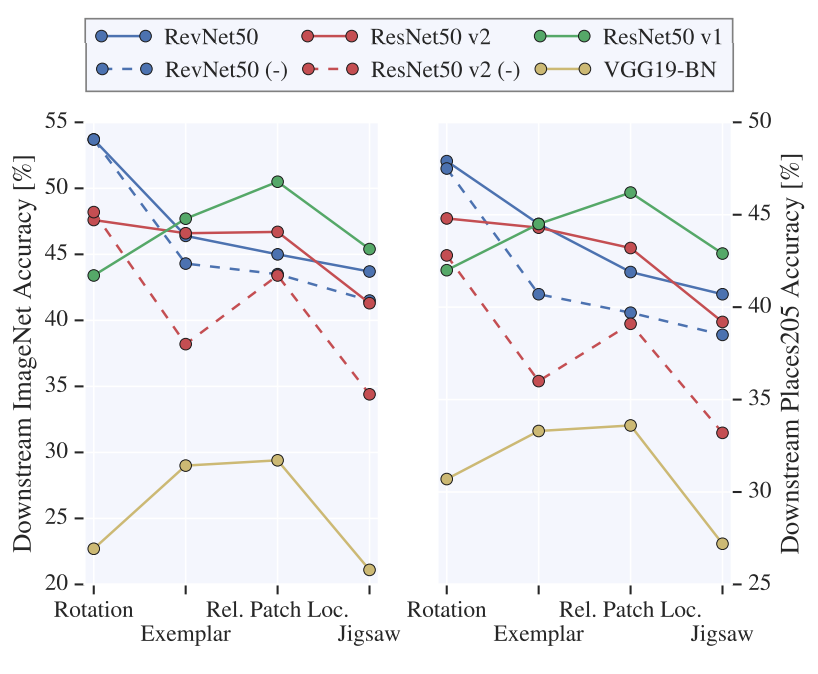
왼쪽은 ImageNet, 오른쪽은 Places205에서 가장 큰 $k$를 사용했을때의 결과이다.
4.2 Comparison to prior work
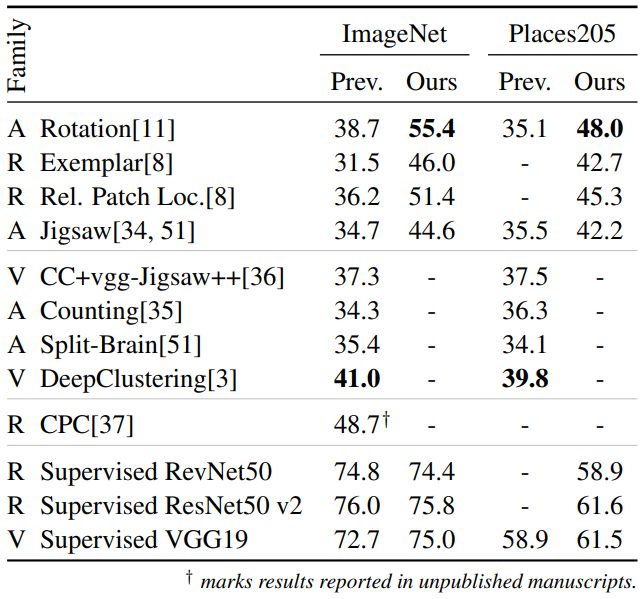
기존 방법들과 정확한 비교를 위해, downstream task에서 L-BFGS를 사용하지 않고 SGD를 이용했다.
- 사용된 모델의 선택이 중요함을 시사한다.
4.3 A linear model is adequate for evaluation
Classifier로 linear model를 사용하면 representation space에서 pretext task에 관한 것과 data 자체에 관한 것으로 나뉜다는 전제조건이 필요한데, 이는 Self-supervised의 목적인 유용한 representation과는 관련이 없다. 따라서, Classifier를 MLP로 교체해서 실험을 진행했다.
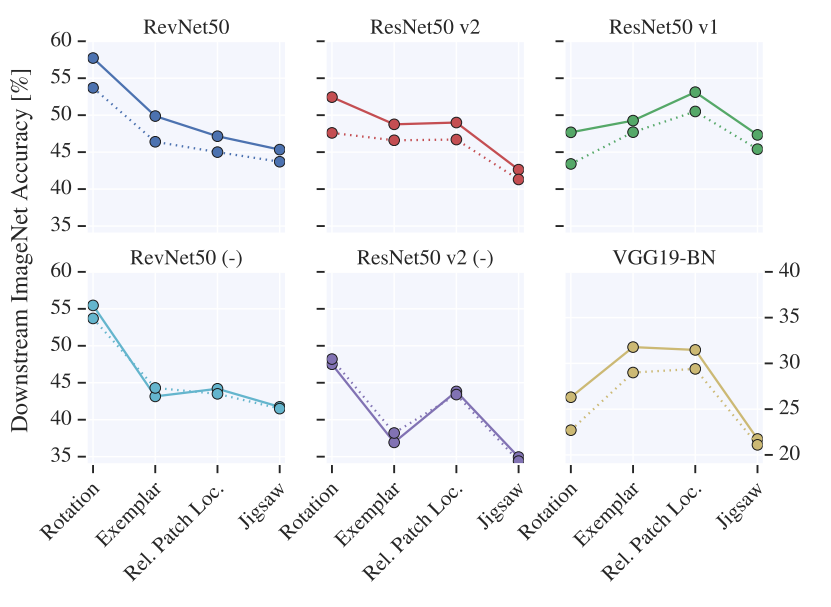
점선이 Linear, 실선이 MLP이다.
- Linear를 이용한 결과의 양상이 MLP와 어느정도 유사하고 약간의 성능 차이밖에 나지 않으므로 Linear model을 사용해도 무관하다.
4.4 Better performance on the pretext task does not always translate to better representations
원의 크기는 $k$를 뜻한다.
- 모델에 따라 pretext 성능과 downstream 성능이 어느정도는 비례하지만, pretext 성능만으로 모델을 선택하기에는 무리가 있다.
4.5 Skip-connections prevent degradation of representation quality towards the end of CNNs
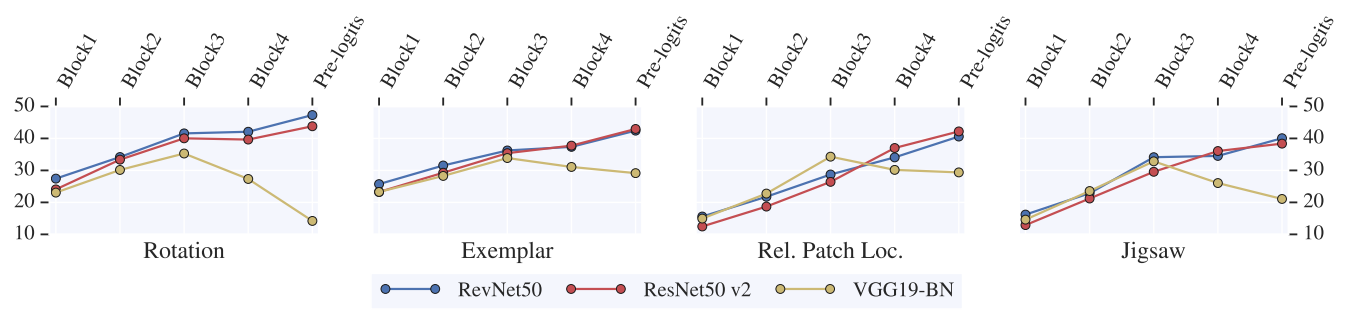
- VGG19-BN의 경우 모델이 pre-logis과 가까울수록 pretext에 특화되므로 성능이 저하된다.
- ResNet과 RevNet의 경우 Skip-connection이 모든 정보를 보존하므로 성능이 저하되지 않는다.
- RevNet의 invertibility 때문에 ResNet보다 성능이 좋을것으로 예상했지만, Rotation을 제외하면 별 다른 차이가 없음이 확인되었다.
4.6 Model width and representation size strongly influence the representation quality
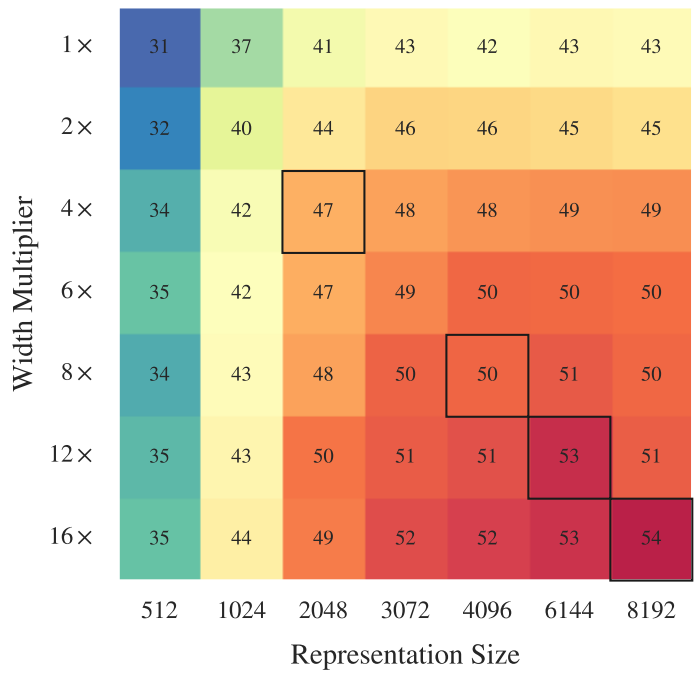
각 숫자는 정확도를 의미한다. 검은 상자는 4.1 실험 결과이다. $k$와 관계없이 pre-logits의 크기를 키우기 위해 linear layer를 하나 추가해 실험했다.
-
모델의 크기와 representation의 크기 모두 클수록 좋다.
-
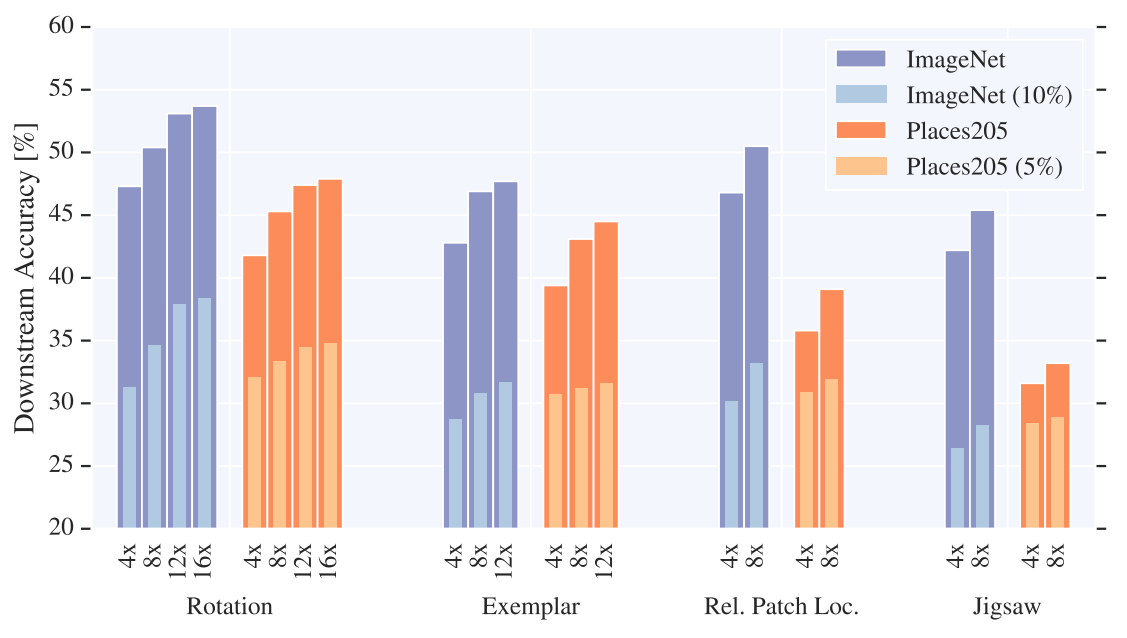
Downstream task의 데이터가 많지 않을 경우에도 위의 통찰이 통하는지 확인하기 위해 semi-supervised setting으로 실험을 진행했고, 여전히 효과가 있음을 확인했다.
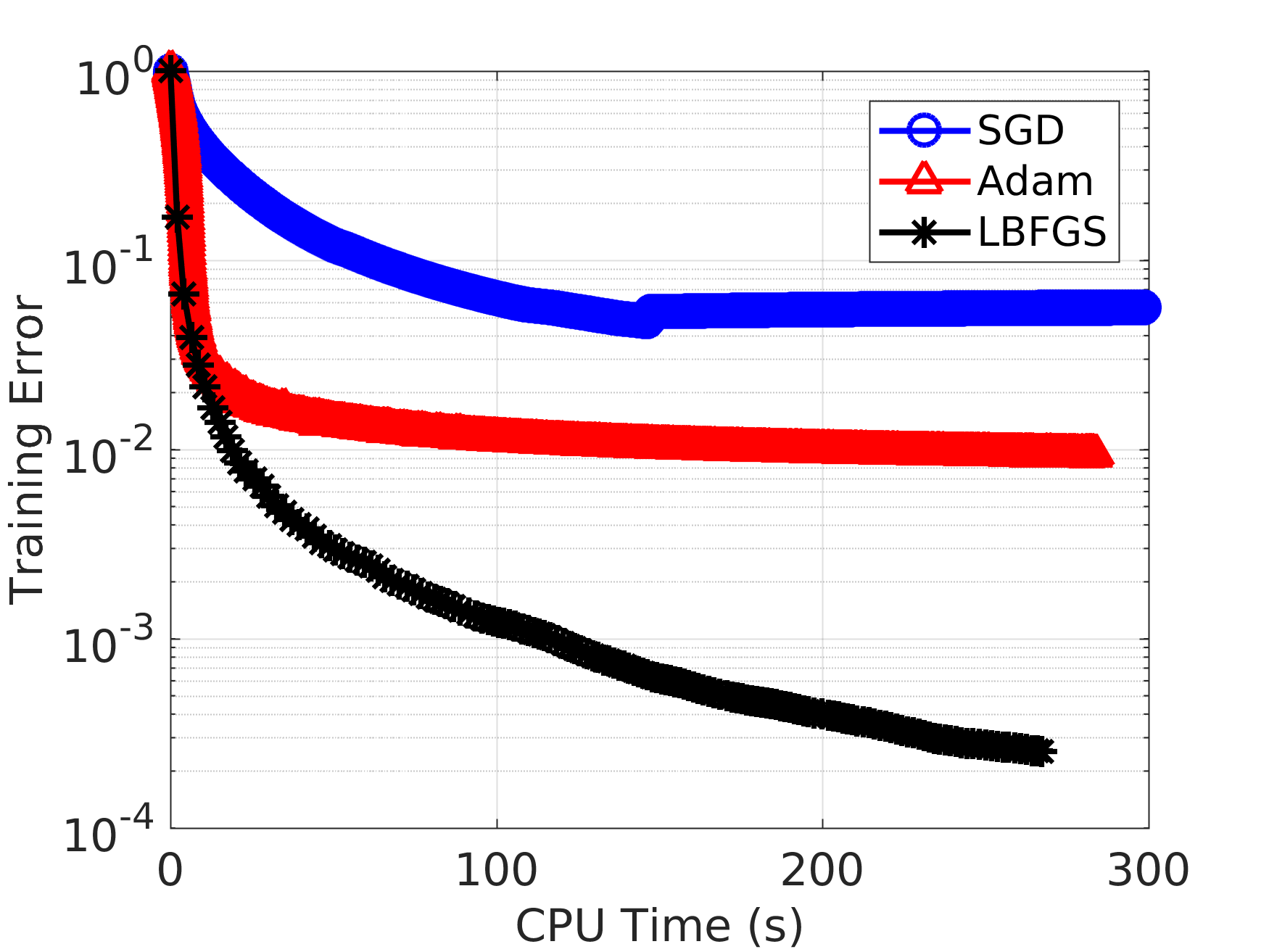
4.7 SGD for training linear model takes long time to converge
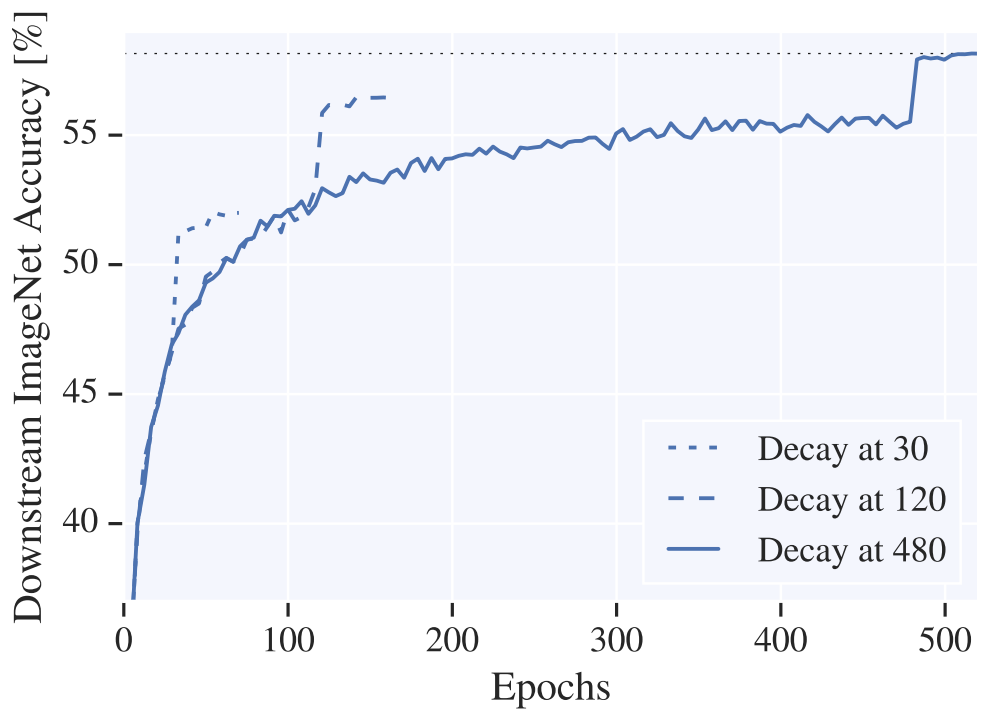
첫번째 learning rate decay후 20 epoch 후 두번째 decay를 실시하고, 그 후 20 epoch 추가로 학습시켰다.
- learning rate scheduling이 학습에 크게 영향을 미친다.
5. Conclusion
- Supervised setting에서 모델 구조에 관한 통찰들이 Self-supervised setting에서 항상 통하지 않는다.
- 이전 연구들의 AlexNet과 달리 ResNet계열은 pre-logits에서 성능이 좋다.
- Widening factor $k$는 성능에 크게 영향을 준다.
- SGD는 최고성능을 내기위해서는 많은 epoch을 요구한다.
- Self-supervised method는 적합한 model을 함께 고려해야한다.
Leave a comment