관련 링크 : https://arxiv.org/abs/1803.07728
Self-supervised Learning : Rotation(2018)
Abstract
성공적으로 feature를 학습하기위해 많은양의 labeled data가 요구되지만 이는 비용이 많이 든다. 따라서 label이 필요없는 unsupervised learning이 주목받고 있다. 본 논문에서는 네트워크에게 이미지에 적용된 2d 회전을 맞추도록 학습시켜 feature를 배우는 방법을 제안한다. 여러 다른 방법과 비교해본 결과, 본 논문의 방법이 가장 좋은 결과를 보였다.
1. Introduction
Supervised learning은 feature를 학습하는데 효과적이지만, 많은 labeled data를 요구하고 이는 현실에 있는 실제 data에 비하면 턱없이 작을 뿐만아니라 제작 비용도 높다. 이 때문에 흑백 이미지를 컬러 이미지로 바꾸거나, 이미지를 조각내 각 조각의 상대적인 위치를 에측하거나, 비디오에서 두 프레임 사이의 카메라 이동을 예측하는 등의 pretext task를 이용해 feature를 학습하는 self-supervised learning이 주목받았다. 이 방법들은 supervised learning보다는 못하지만 object recognition, detection 등의 task에서도 괜찮은 성능을 보이는 유의미한 feature를 학습했다.
본 논문은 이런 방법의 일환으로 이미지에 적용된 기하학적 번형을 인식하는 pretext task를 이용한다. 여기서 사용된 기하학적 변형은 0, 90, 180, 270도의 이미지 회전이고 따라서 네트워크는 4종류의 이미지 분류 모델이 된다. 또한 기존 방법들이 하나의 이미지를 조각내고 각 조각들을 모델이 한번에 보도록 하기위해 여러개의 siamese 네트워크를 이용했지만, 논문의 방법은 그럴 필요가 없어 간단하게 수행할 수 있다.

이는 사람이 사물을 인식할때 그 사물을 제대로 이해하지 못한다면 회전 여부도 알 수 없을것이라는 직관에서 나온 것이다.
2. Methodology
2.1 Overview
학습의 목적은 $F$가 입력으로 주어진 이미지에 적용된 $G$를 추정하는 것이다.
- $F(.)$ : ConvNet 모델
- $G=\{g(.|y)\}^{K}_{y=1}$ : $K$개의 기하학적 변형
- $g(.|y)$ : 변환된 이미지 $X^y=g(X|y)$를 생성하는 연산자.
구체적으로 $F$는 이미지 ${X^y}^*$가 입력으로 들어왔을때 모든 가능한 변형의 확률분포를 출력으로 내보낸다.
\[F(X^{y*}|\theta)=\{F^y(X^{y*}|\theta)\}^K_{y=1} \tag 1\]- $F^y(X^{y*}|\theta)$ : 입력이미지가 라벨 $y$를 가지게 하는 변형의 확률 분포($\theta$는 $F$의 파라미터, $y^*$는 $F$가 모르는 입력이미지의 라벨)
따라서, $N$개의 이미지가 주어졌을때 학습 목표는
\[\underset{\theta} {\mathrm {min}} \displaystyle \frac 1 N \sum ^N _{i=1} loss(X_i,\theta) \tag 2\]이고, $loss(.)$는
\[loss(X_i, \theta) = \displaystyle -\frac 1 N \sum ^K _{y=1} log(F^y(g(X_i|y)|\theta)) \tag 3\]이다.
2.2 Choosing Geometric Transformations: Image Rotations
위의 수식에서 $G$는 모델이 visual task에 유용한 semantic feature를 학습해야 하므로 classification task여야 한다. 논문에서는 이를 90도의 rotation으로 정의했다. 따라서 $K=4$이고, $G ={\{g(X|y)\}}^{4}_{y=1}$가 된다. 이때, $g(X|y)=Rot(X, (y-1)90)$이다.
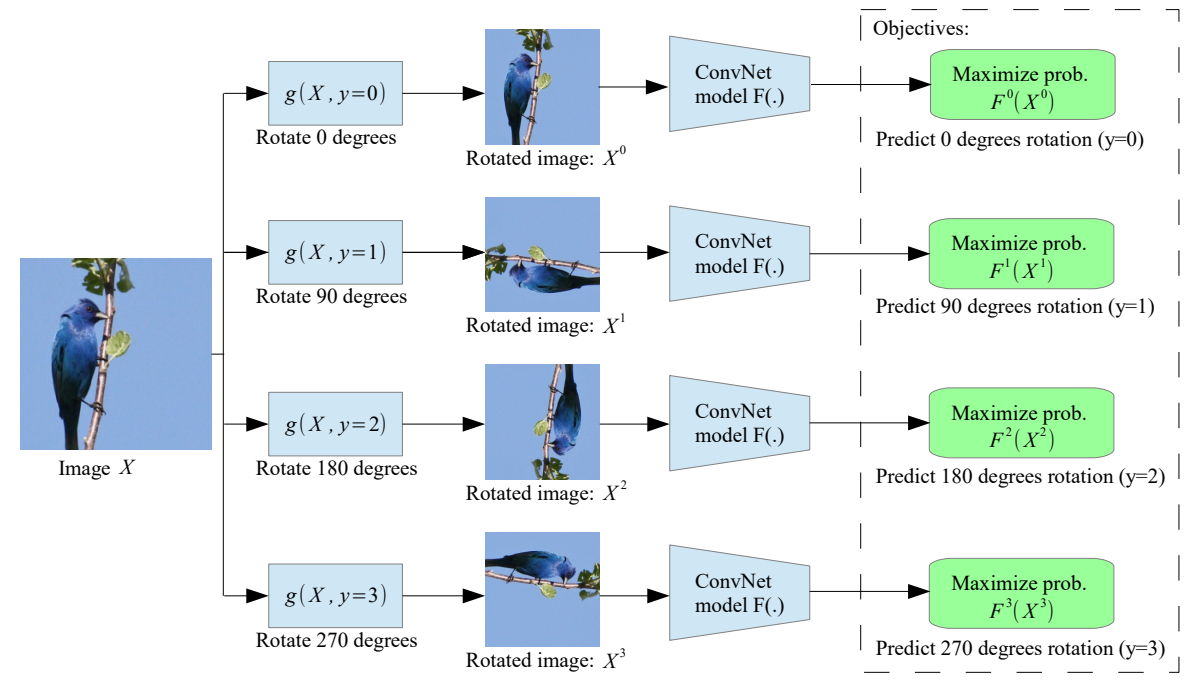
그런데 왜 rotation일까? 이는 이미지의 회전을 예측하기 위해서는 먼저 이미지에서 의미적인 부분뿐만 아니라 물체의 종류를 인식하고 감지해야하기 때문이다. 구체적으로 이미지에서 중요한 물체의 위치를 파악하고, 그 물체의 유형을 파악해 물체가 이미지에 나타나는 일반적인 방향과 현재 이미지에서의 방향을 비교하는 법을 배워야하기 때문이다.
위의 그림에서 일반적으로 나무의 방향은 세로이고, 새의 머리의 위치는 위쪽이라는 정보를 모른다면 방향을 예측할 수 없다. 따라서 먼저 객체의 정보를 학습해야 회전을 예측할 수 있다.
이는 모델이 rotation을 예측하기위해 이미지의 어느부분에 집중하는지 보여주는 attention map을 보면 알 수 있다. 아래 그림을 보면 실제로 눈, 코, 꼬리, 머리등의 high-level feature를 본다는 것을 알 수 있고 이는 supervised learning한 모델의 attention map과도 유사하다.

게다가, 첫번째 층의 filter를 시각화해보면 다양한 크기와 방향을 가진 edge가 관찰되고, 심지어 supervised learning 모델보다 더 다양하다.

이 외에도 Rotation에는 여러 장점이 있다.
-
transpose와 flip으로 구현하므로 resize할 필요가 없다. 예를들어 90도 회전의 경우 transpose후 수평으로 flip하면 된다.
resize와 같은 scale, aspect ratio 변형은 모델이 classification task에는 영향을 주지 않는 low level feature를 학습하도록 한다. (이미지가 rescale되었음을 쉽게 파악하고 이를 feature로 생각하는데, 이는 실제로 classification에 쓸모없으므로 학습에 좋지않다는 이야기로 추측된다.)
-
기본적으로 사진은 “up-standing”하게 찍으므로 사진의 회전 기준을 정하기가 쉽다.
만약 사진이 무작위 방향으로 찍힌다면, 사람도 지금 보는 사진이 원본에서 얼마나 회전되었는지 구분할 수 없을 것이다. 하지만 사진은 기본적으로 “up-standing”하기 때문에 구분할 수 있다.
2.3 Discussion
본 논문의 간단한 방법은 여러 장점을 가진다.
- supervised learning과 동일한 computational cost를 요구한다.
- supervised learning과 유사한 학습 속도를 가진다.(이는 reconstruction method보다 훨씬 빠르다.)
-
다른 self-supervised learning에서 사용한 pre-processing이 필요없다.
crop하거나 이미지 색상에 변화를 주는 것을 말하는 듯
3. Experimental Results
3.1 CIFAR Experiments
Rotation recognition task로 학습된 feature를 이용해 CIFAR-10 데이터셋의 object recognition task를 수행하고 결과를 평가한다. self-supervised task에 사용된 모델을 RotNet이라고 명명한다.
Implementation details
- RotNet 모델은 Network-In-Network 구조를 이용한다.
- Optimizer는 SGD를 사용한다.
- batch size : $128$, momentum : $0.9$, weight decay : $5\times 10^{-4}$, lr : $0.1$, total epoch : $100$
- lr은 30, 60, 80 epoch마다 1/5로 줄인다.
- 실험결과 모델이 한번에 네 방향의 이미지를 모두 보는게 성능이 좋았으므로, 각 training batch마다 batch size의 4배를 학습한다.
| Network-In-Network 구조 |
|---|
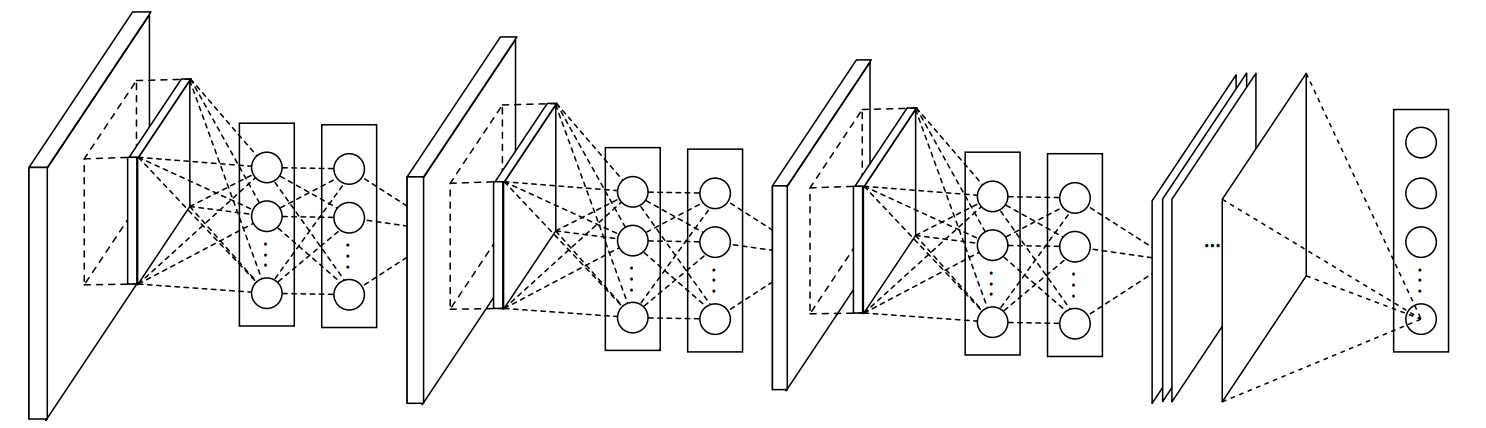 |
Evaluation of the learned feature hierarchies
깊이에 따라 학습된 feature의 quality와 $RotNet$의 총 깊이가 성능에 미치는 영향을 조사한다. NIN 구조의 conv 블럭을 이용해서 3, 4, 5개의 블럭을 가지는 모델을 만들어 rotation task를 학습한 후, 각 블럭에 CIFAR-10 recognition task를 위한 classifier를 붙여 성능을 확인한다.
Conv 블럭은 conv-conv(1x1)-conv(1x1)를 의미함

ConvB1의 feature map size는 $96\times 16\times 16$이고, 나머지는 $192\times8\times8$이다. Classifier는 3-FC(with BN and ReLU)를 이용했다.
세 모델 전부 ConvB2에서 성능이 좋다. 이는 깊은 층은 pretext task에 관해 specific 해지기 때문이다. 동일한 이유로 모델이 깊을수록 성능이 향상되는 것은 모델이 깊어질수록 초기층이 pretext task에 관해 덜 specific 해도 되기 때문이다.
Exploring the quality of the learned features w.r.t. the number of recognized rotations
가능한 rotation의 수가 성능에 미치는 영향을 조사한다.
- (a) : 45도로 8번 회전시킨 것($K=8$)
- (b) : 0도와 180도($K=2$)
- (c) : 90도와 270도($K=2$)

각 실험은 4 블럭 RotNet의 ConvB2에 classifier를 붙여 진행했다.
4 rotation가 성능이 가장 좋다. 이는 (a)의 경우는 각 rotation이 명확히 구분하기 어렵고, (b),(c)는 recognition하기에 너무 작은 class를 가지고 있기 때문으로 보인다. 또 (c)가 가장 정확도가 낮은데, 이는 classification task에서 사용되는 0도 image로 학습시키지 않았기 때문으로 보인다.
Comparison against supervised and other unsupervised methods
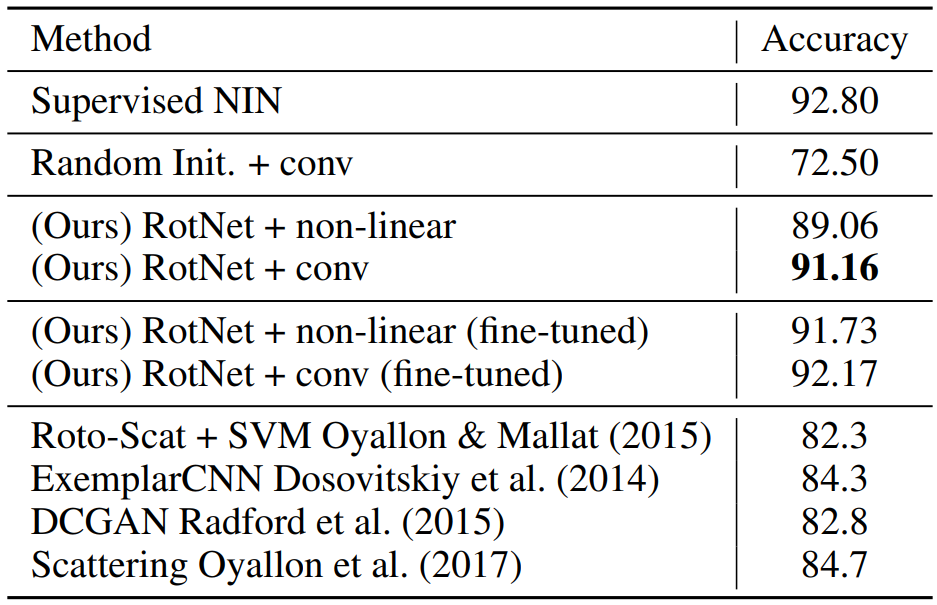
위 실험에서 사용된 모든 RotNet은 4 블럭의 ConvB2의 feature map을 이용했다.
- RotNet + non-linear : RotNet의 블럭 2개+ 3-FC(with BN and ReLU)
- RotNet + conv : RotNet의 블럭 2개+ 무작위로 초기화된 블럭 1개(3 블럭 NIN 구조와 동일)
여기서 Random Init은 feature extractor의 모든 parameter를 random initialization하고 fix시킨 후 classificer만 추가한 것이므로, classifier만의 성능을 나타낸다고 볼 수 있다.
Correlation between object classification task and rotation prediction task

Rotation을 학습시킬때 20 epoch마다 freeze시키고 classification task를 수행한다. 이때 매번 classifier는 새로 학습시킨다.
rotation accuracy가 향상됨에 따라 recognition accuracy도 향상되고 classification task가 rotation task보다 더 빨리 학습된다.
Semi-supervised setting

위에서 사용한 RotNet+conv를 semi-supervised 모델로 사용한다.
카테고리당 이미지가 1000장 이하일때 supervised learning보다 효과적이고 이는 카테고리당 이미지수가 적어저질수록 커짐을 알 수 있다.
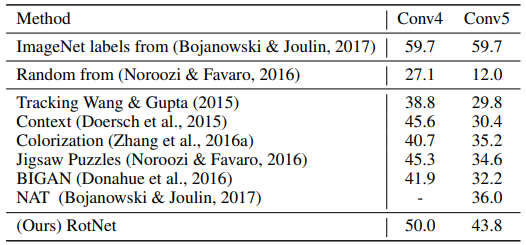
3.2 Evaluation of Self-Supervised Features Trained In ImageNet
Rotation recognition task로 학습된 feature를 이용해 ImageNet/Places/PASCAL VOC 데이터셋의 image classification/object detection/object segmentation task를 수행하고 결과를 평가한다.
Implementation details
- RotNet 모델은 AlexNet 구조를 이용한다.
- Local Response Normalization/Dropout은 제외한다.
- 대신에 BN을 사용한다.
- Optimizer는 SGD를 사용한다.
- batch size : $192$, momentum : $0.9$, weight decay : $5\times 10^{-4}$, lr : $0.01$, total epoch : $30$
- lr은 10, 20 epoch마다 1/10로 줄인다.
- CIFAR과 동일하게, 각 training batch마다 batch size의 4배(모든방향)를 학습한다.
ImageNet classification task
| non-linear classifier(3-FC with BN) | linear classifier(1-Linear) |
|---|---|
 |
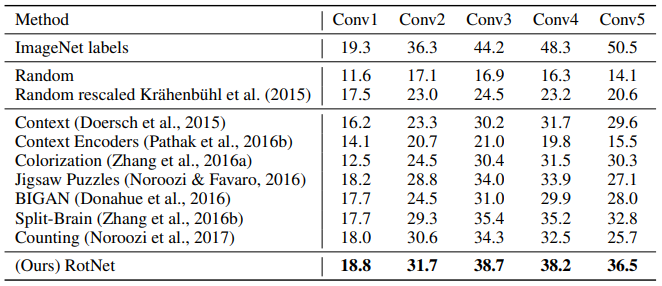 |
Random과 ImageNet labels를 제외하고 모두 ImageNet으로 pre-trained했다. 오른쪽은 classifier가 Linear layer 하나로 단순하므로, feature extractor의 성능을 보여준다고 볼 수 있다.
Transfer learning evaluation on PASCAL VOC

Places classification task

Linear classifier를 사용했다.
학습과정에서 전혀 보지못한 이미지의 classification task에서 기존의 다른 방법과 유사하거나 더 뛰어난 성능을 보여준다.
4. Conclusions
본 논문에서는 입력 이미지에 적용된 회전을 인식하는 pretext task를 이용해 모델을 학습하는 방법을 제안하고, 다양한 visual task에 유용한 semantic feature를 학습 할 수 있음을 증명했다. 이 방법은 기존의 다른 unsupervised method보다 뛰어나고 supervised method보다 약간 떨어지는 성능을 보였다.
Leave a comment