관련 링크 : https://arxiv.org/abs/2002.05709
Self-Supervised Learning : simCLR(2020)
Abstract
본 논문은 제목(A Simple framework for contrastive learning of visual representations)처럼 기존의 연구와 다르게 특별한 구조와 메모리 뱅크가 없는 간단한 contrastive self-supervised learning을 제안한다. 총 세가지가 기존 연구와 다르다.
- Data augmentation이 중요한 역할을 한다.
- Representation과 Contrastive loss사이에 Nonlinear Transformation를 도입한다.
- Supervised보다 훨씬 큰 batch size와 더욱 많은 epochs동안 학습시킨다.
1. Introduction
Unsupervised method에서 effective visual representation을 위한 방법은 일반적으로 두개로 나뉜다. 그 중 하나는 Generative approach로 이미지를 만들어내거나 입력 이미지의 분포를 학습하는데 representation learning에는 불필요한 많은 연산을 요구한다. 다른 하나는 Discriminative approach로 pretext task를 이용해 supervised learning과 유사하게 학습하는 방식이다.
본 논문은 후자의 방식 중에서 latent space에서의 contrastive learning을 이용한 simCLR을 제안한다. SimCLR은 기존의 방식보다 간단한 방법으로 좋은 성능을 보이며, 다음 요소들을 확인했다.
- Contrastive prediction task를 정의할때 Data augmentation의 구성이 중요하고, Unsupervised contrastive learning은 Supervised보다 많은 Data augmentation을 이용해야 한다.
- Representation과 Contrastive Loss 사이에 Nonlinear transformation을 도입하면 성능이 좋아진다.
- Normalized embedding과 Temperature parameter를 사용한 Contrastive cross entropy loss를 이용한다.
- Supervised와 비교해서 더 큰 batch size와 더 긴 training epoch을 사용해야 한다.
- Supervised처럼 네트워크가 깊고 넓을수록 성능이 좋다.
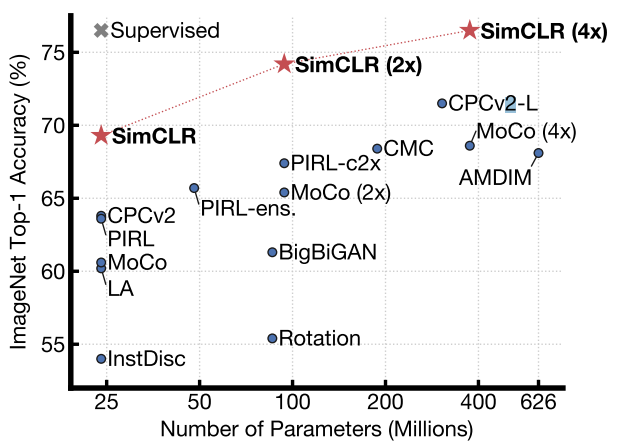
2. Method
2.1 The Contrastive Learning Framework
SimCLR은 다르게 augmented된 같은 이미지들을 contrastive learning을 통해 latent space에서 유사하게 만드는 방법으로, 아래 그림과 같다.
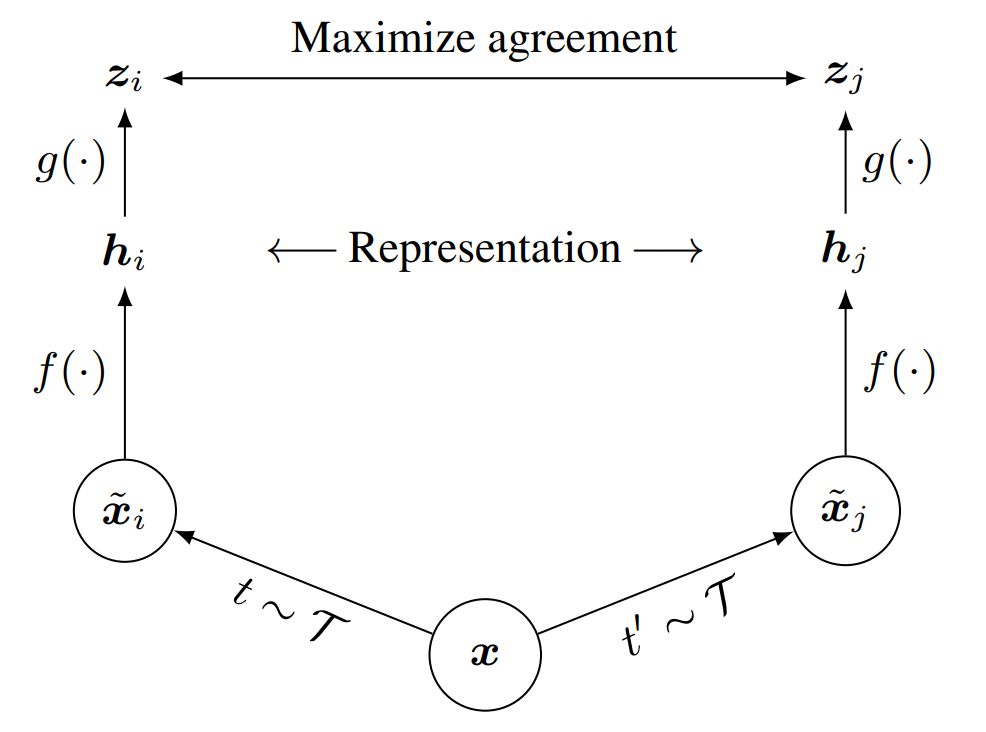
- 논문에서 사용한 $\mathcal T$는 random cropping and resize to original, random color distortion, random Gaussian blur이다. 이것의 영향은 3장에서 다룬다.
- base encoder $f(\cdot)$은 ResNet이고, $h_i$는 $\mathsf{Avg Pool}$이후의 출력이다.
- projection head $g(\cdot)$으로 $\mathsf {MLP}$를 사용한다. $z_i=g(h_i)=W\cdot\mathsf{ReLU}(Wh_i)$이다. $\mathsf {MLP}$ 사용의 영향은 4장에서 다룬다.
- Contrastive Prediction task의 목적은 $\tilde x_i$가 주어졌을때, $\{\tilde x_k\}_{k \not = i}$ 중에서 positive pair인 $\tilde x_j$를 식별하는 것이다.
Loss function
\[\ell _{i, j} = -\log \frac {\exp(\mathrm {sim}(z_i, z_j)/\tau)}{\sum^{2N}_{k=1}\mathbb I_{[k\not=i]}\exp(\mathrm{sim}(z_i,z_k)/\tau)} \tag 1\]- Batch size가 $N$인 batch에 data augmentation을 사용하며 $2N$으로 늘리고, positive pair를 제외한 $2(N-1)$개의 negative sample을 이용해 학습
- $\mathbb{I}_{[k\not=i]}\in \{0,1\}$ : Indicator function, $1$ if $k\not=i$
- $\tau$ : Temperature parameter
- $\mathrm{sim}$ : cosine similarity($\mathrm{sim}(u, v)=u^{\mathrm T}v/\|u\|\|v\|$)
Positive sample $(i, j)$를 이용해서 계산한 $\ell(i,j)$와 $\ell(j, i)$는 다르다. 따라서 최종적인 $\mathcal L$은 다음과 같다.
\[\mathcal {L} = \frac {1} {2N} \sum ^N_{k=1}[\ell(2k-1, 2k)+\ell(2k,2k-1)]\]- $k \in \{1,\ldots,N\}$
2.2 Training with Large Batch Size
Memory bank를 사용하지 않는 대신에 $N$을 $256$에서 $8192$까지 다양하게 사용한다. 너무 큰 batch size는 기존 방식으로 학습시킬 수 없으므로, LARS optimizer를 이용한다. 다수의 TPU로 학습할때 모델이 local information leakage를 shortcut으로 이용할 수 있으므로, Global BN을 이용한다.
2.3 Evaluation Protocol
- Dataset and Metrics
- Dataset: ILSVRC-2012
- Metrics
- Transfer/Semi-supervised learning 성능을 평가한다.
- Learned representation 성능을 평가하기위해 표준적인 linear evaluation protocol을 사용한다.
base net은 고정시키고 linear classifier만 추가해서 평가하는 방식
- Default setting
- Data augmentation : random crop and resize, color distortion, Gaussian blur
- Base encoder : ResNet-50
- Projection head : 2-layer MLP
- Optimizer
- LARS with linear lr scaling : $\text{LearningRate}=0.3\times \text{BatchSize}/256$
- Linear Warmup for first 10 epochs/Cosine decay scheduler without restart
- Weight decay : $10^{-6}$, Batch size : $4096$, Training epochs : $100$
3. Data Augmentation for Contrastive Representation Learning
Data augmentation defines predictive tasks
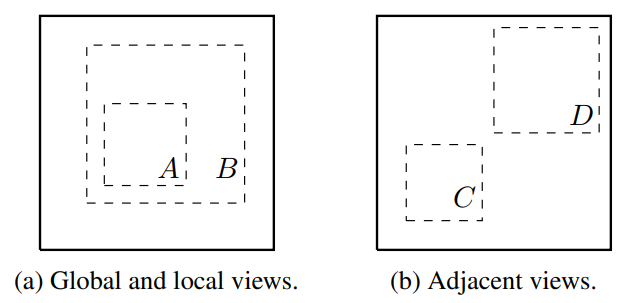
기존 연구가 global-to-local prediction과 neighboring view prediction을 위해 네트워크 구조를 바꾼것에 비해, SimCLR은 단순히 random crop이란 data augmentation을 사용해서 유사한 효과를 얻었다.
3.1 Composition of data augmentation operations is crucial for learning good representations

Augmentation의 성능 비교를 위해 사용된 방법들
위의 방법들 중 가장 좋은 성능을 내는 augmentation이 무엇인지 비교하기위해 실험을 진행했다.
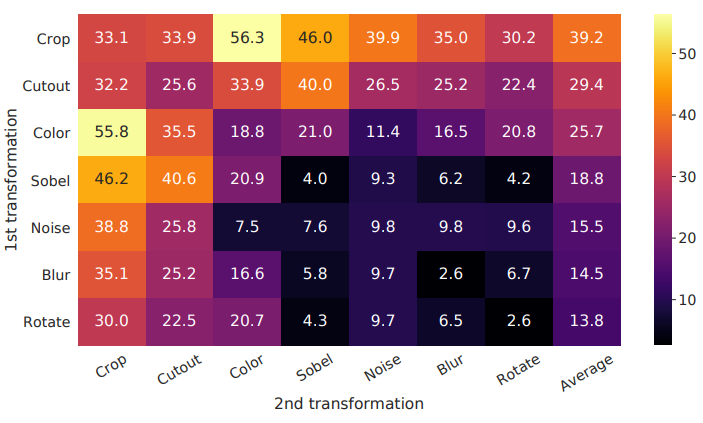
대각 성분은 하나의 augmentation만 적용한 것으로, 이를 위해서 두개의 입력중 하나는 augmentation을 사용하지 않았을때의 성능을 평가했다. 나머지는 두개의 augmentation을 조합했을때의 성능이다.
- 모델이 Contrastive task를 완벽히 수행했을때도 단일 augmentation의 성능은 좋지 않았다.
- Augmentation을 조합하면 contrastive task의 난이도가 높아져 representation의 질도 향상되었다.
-
Crop과 Color distortion의 조합이 가장 성능이 뛰어났는데, 이는 random crop한 이미지들은 색 분포가 유사해서 모델이 이를 shortcut으로 이용할 수 있었지만, color distortion을 적용하면 색 분포가 달라져 task의 난이도가 높아지기 때문이다.
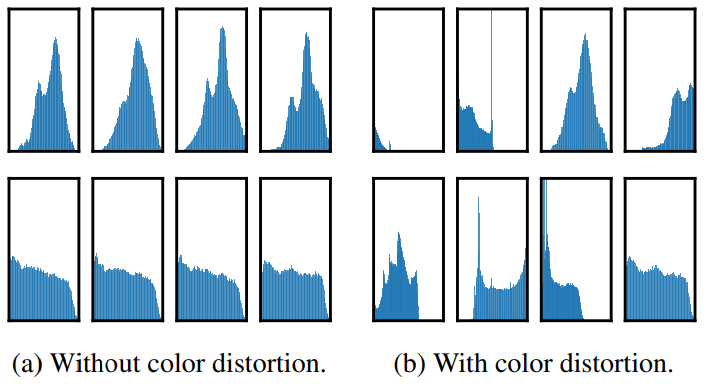
- 각 행은 같은 이미지다.
3.2 Contrastive learning needs stronger data augmentation than supervised learning
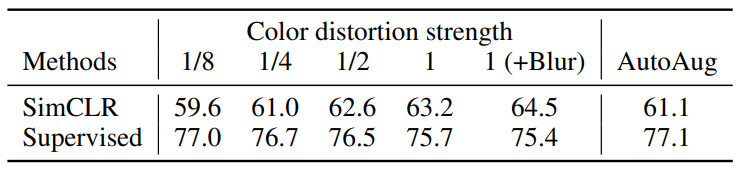
- SimCLR은 distortion이 강해질수록 성능이 증가하는데 비해 Supervised model은 오히려 줄어든다. 또 Supervised model에서 성능이 좋았던 AutoAug는 SimCLR에서는 오히려 좋지않다.
4. Architectures for Encoder and Head
4.1 Unsupervised contrastive learning benefits (more) from bigger model
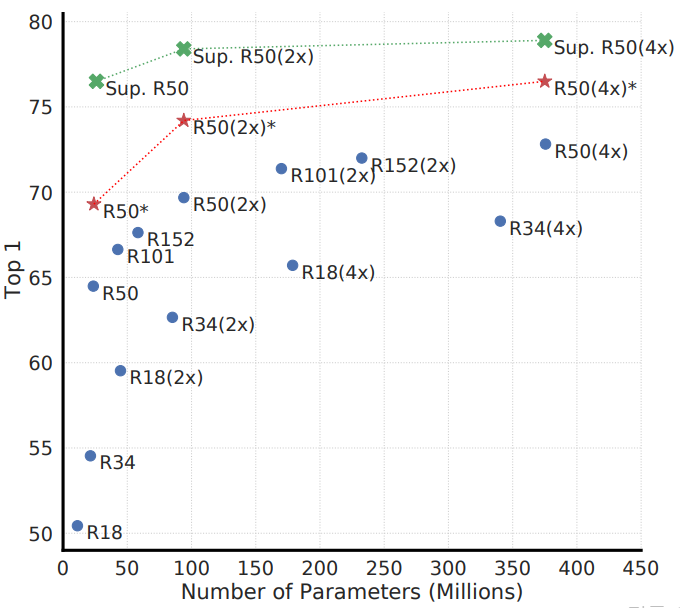
Supervised model은 90 epochs, SimCLR은 1000 epochs 동안 학습시켰다.
- Unsupervised model이 Supervised model보다 네트워크 크기에 따른 이득을 더 많이 본다.
4.2 A nonlinear projection head improves the representation quality of the layer before it
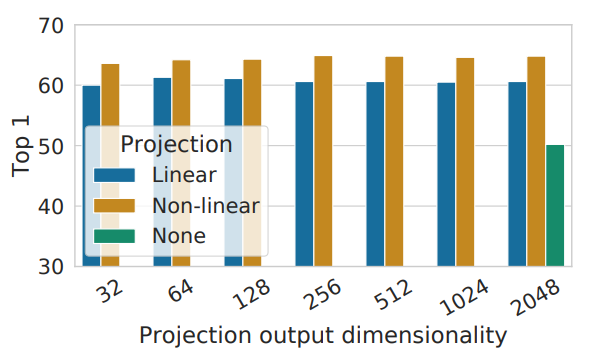
$h$는 2048-dimensional이다.
- MLP를 사용하는게 Linear를 사용하는것 보다 성능이 좋다.
-
MLP를 사용했을때 projection 다음 층을 downstream task에 사용하는것 보다 이전 층을 사용하는게 10%이상의 성능 향상이 있었다. 이는 $g(\cdot)$이 contrastive task를 위해 물체의 색과 방향과 같은 정보를 버리기 때문이다.

- $g(\cdot)$의 representation 성능이 더 좋지않다.

- 위 사진은 t-SNE visualization으로, $h$가 $z$보다 각 class를 명확히 나타낸다.
5. Loss Functions and Batch Size
5.1 Normalized cross entropy loss with adjustable temperature works better than alternatives

모든 벡터는 $\ell_2$ normalized 되었다.
- $\ell_2$ normalization with $\tau$는 다양한 예시에 효과적로 가중치를 부여하고 적절한 $\tau$는 어려운 negative sample의 학습을 도울 수 있다.
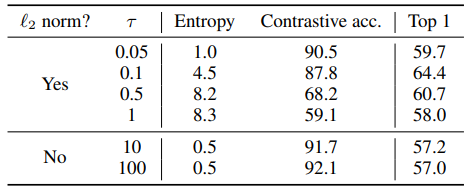
$\ell_2$ normalization이 없을때 contrastive acc는 높지만 representation의 성능은 형편없다.
- Cross-entropy와 다르게, 다른 함수들은 난이도에 따라 negative sample에 가중치를 부여하지 않는다.

하지만 semi-hard negative mining(sh)으로 가중치를 부여해 줬을때도 NT-Xent의 성능이 가장 좋다.
5.2 Contrastive learning benefits (more) from larger batch sizes and longer training
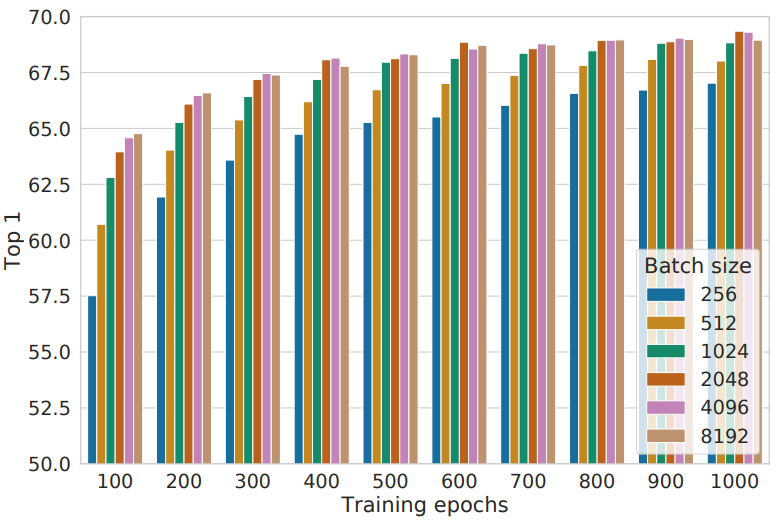
- Training epochs이 커질수록 Batch size에 의한 영향은 줄어든다.
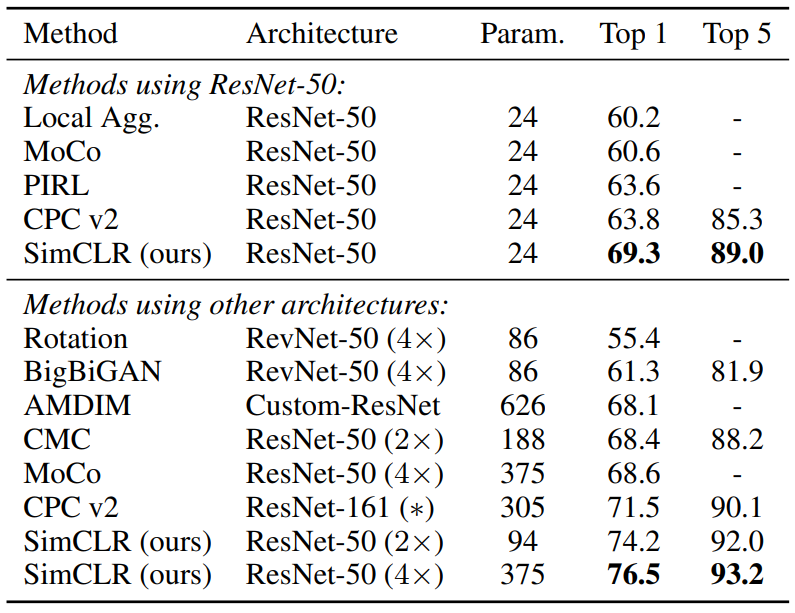
6. Comparison with State-of-the-art
- ResNet-50을 채널수를 $1\times$, $2\times$, $4\times$로 늘리고 1000 epochs동안 학습시킨 후 다른 모델들과 비교한다.
Linear evaluation
Semi-supervised learning
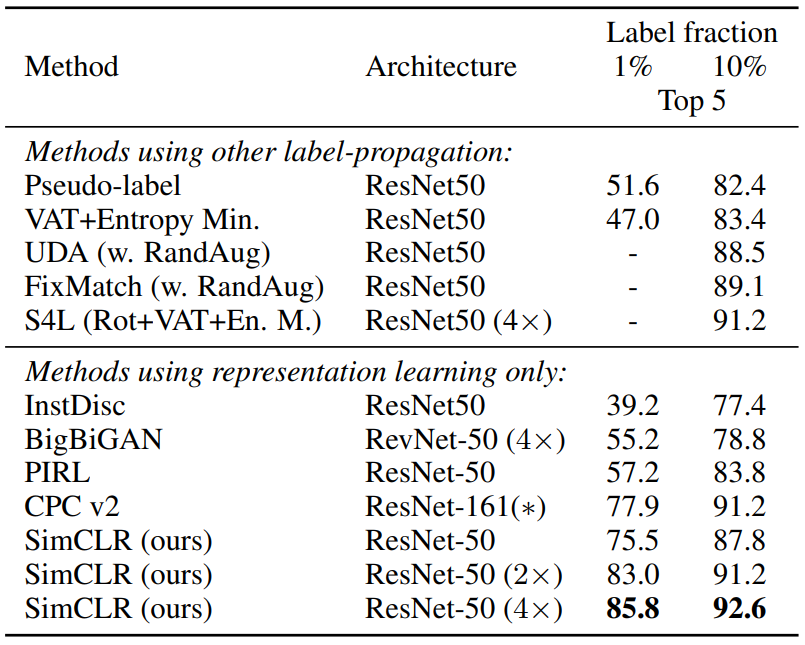
Fine-tuning하여 평가했다.
Transfer learning
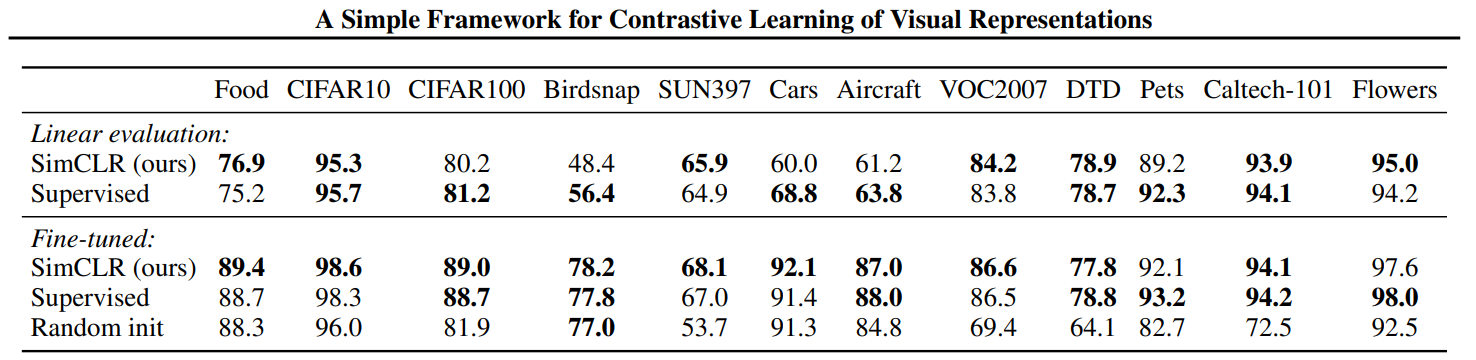
SimCLR은 ResNet-50$(4\times)$를 ImageNet으로 pretrain한 모델을 사용했다.
7. Related Work
- Handcrafted pretext tasks : Relative patch/Jigsaw/Colorization/Rotation
-
Contrastive visual representation learning : Exempler/CPC/MoCo/AMDIM/PIRL
Contrastive learning의 성능이 mutual information에 의한 것인지, contrastive loss에 의한 것인지는 아직 명확히 밝혀지지 않았다.
8. Conclusion
- 이전 방법들의 복잡한 방식은 좋은 성능을 달성하는데 필요하지 않다.
- Nonlinear projection head, data augumentation, loss function등이 SimCLR의 주요 차이점이다.
Leave a comment