관련 링크 : https://arxiv.org/abs/1711.10925
본 논문은 이미지 복원, SR, Denoising 등에 모두 활용 될 수 있는 방법 Deep Image Prior를 제안한다. DeepClustering의 아이디어와 유사하게, 네트워크 구조 자체가 별다른 학습 없이도 low-level feature들을 잘 인식할 수 있음을 이용한다. 과정은 아래 그림과 같다.
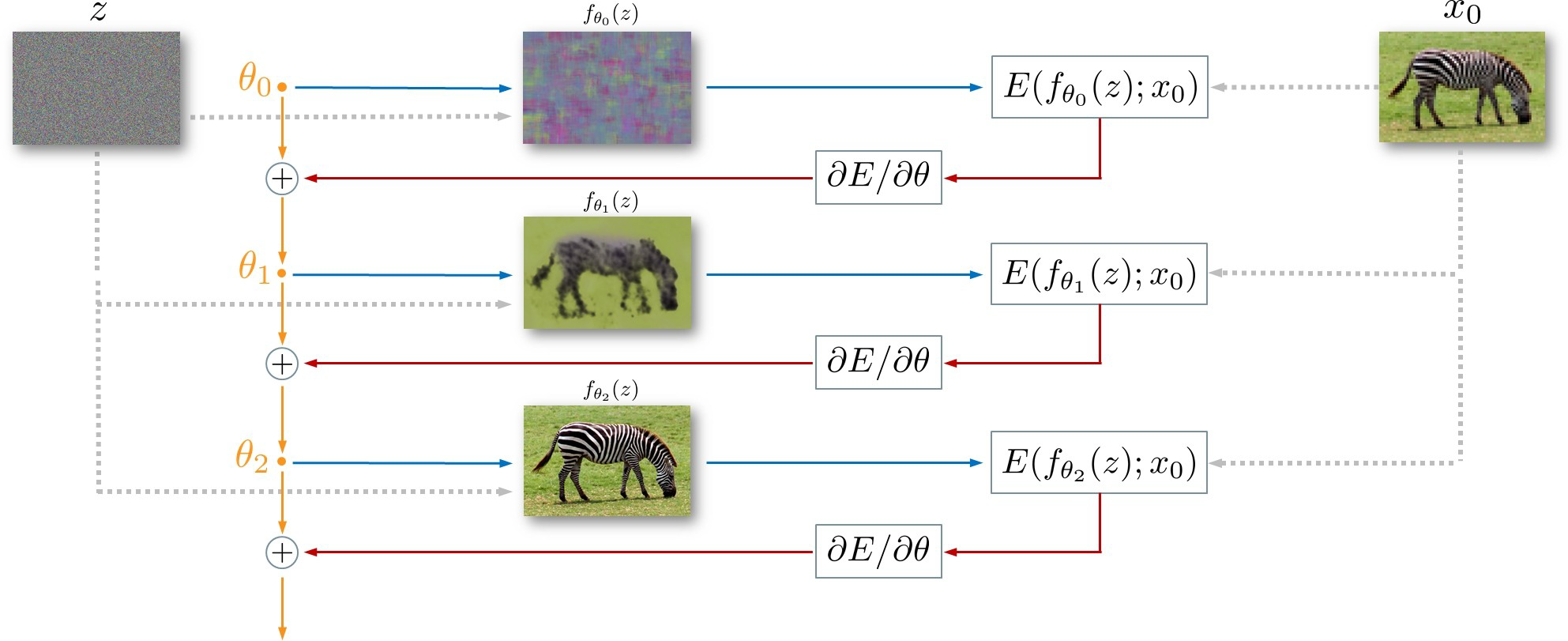
- $x_0$는 $x_{gt}$에 해상도를 줄이거나, 노이즈를 추가하는 등의 degradation process를 적용한 이미지다.
- $z$는 GAN과 유사한 생성모델에서 사용되는 벡터로, 고정된 값을 사용한다. $f_\theta(z)$는 생성된 이미지이다.
- $f_\theta$의 네트워크 구조는 무엇이든 사용할 수 있는데, 논문에서는 hourglass란 Unet과 유사하지만 skip connection이 더 적은 구조를 이용했다.
- $E$는 loss function으로 볼 수 있고, 하고자 하는 task에 따라 $\ell_2$ distance가 될 수도 있고, $\cos similarity$가 될 수도 있다.
- 기존의 생성 모델들이 $z$를 $x$에 맵핑했다면, 이 모델은 특정 이미지 하나에만 적용 가능해 $\theta$를 $x$에 맵핑하는 방법이다.
그럼 어떻게 이게 가능할까? 논문은 $x_0$를 supervision으로 이용해 모델을 학습시킬때, 각 iteration별로 만들어진 이미지 $f_{\theta_t}(z)$와 $x_0$의 $E(f_{\theta_t}(z),x_0)$를 아래 그림으로 보인다. 왼쪽은 Super Resolution, 오른쪽은 Denoising에서의 plot으로 SR같은 경우는 $E(x_{gt}, x_0)$나 $E(x_0, x_0)$가 모두 0인 반면에, Denoising의 경우는 $E$로 $\ell_2$ distance를 사용했을때 $E(x_{gt},x_0)$와 $E(x_0, x_0)$가 다르므로 아래와 같이 표현했다.
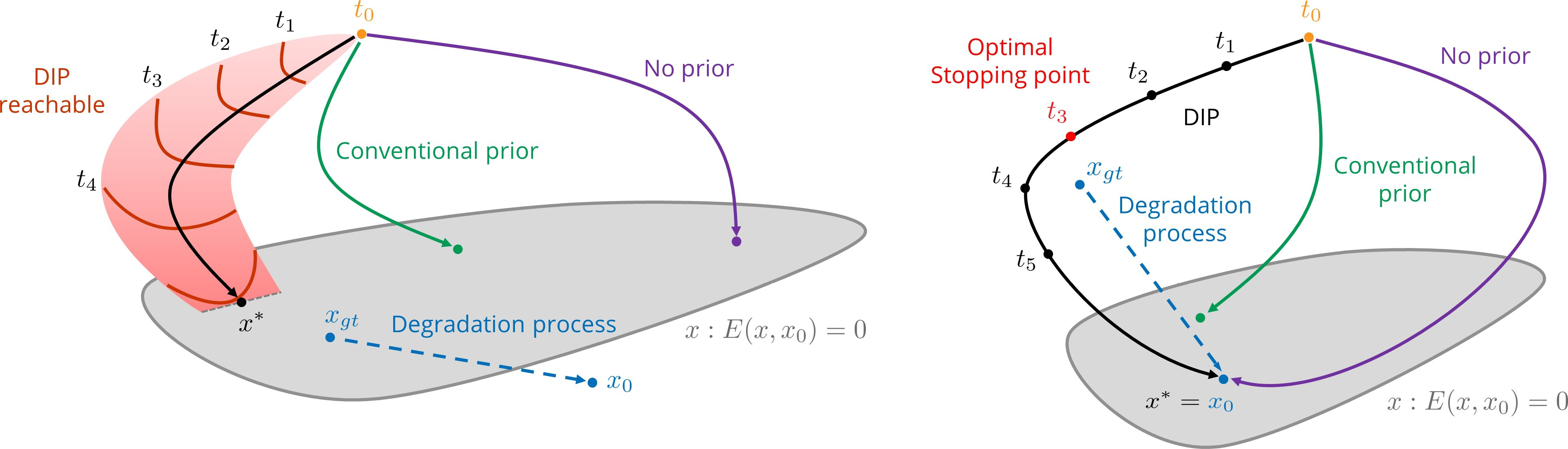
- $E(x, x_0)=0$의 범위가 넓은 이유는 어떤 네트워크 $f$를 이용했느냐에 따라, $E$의 종류에 따라 다르기 떄문으로 보인다.
- Degradation process는 왼쪽의 경우 고해상도 이미지 $x_{gt}$를 저해상도인 $x_0$로 바꾸는 것이고, 오른쪽의 경우는 노이즈가 없는 이미지 $x_{gt}$를 노이즈가 낀 이미지 $x_0$로 바뀌는 것이다.
- 왼쪽의 경우 $E=0$일때 가장 좋은 이미지를 만들지만, 오른쪽의 경우 $E=0$일때가 아니라 $E$가 적당한 값을 가질때 가장 좋은 이미지를 만든다.
그런데 여전히 납득하기 어려운 부분들이 있으므로, 논문에서는 여러 종류의 $x_0$에서 수렴 속도를 보임으로서 이를 뒷받침한다.

$x_0$가 자연스러운 이미지일때 빨리 수렴하고, 노이즈인 경우는 느리다. 노이즈가 섞인 이미지 $x_0$를 노이즈와 이미지로 분리해서 생각해보면, 학습이 완전히 진행됬을 때, 즉 $E=0$일 때보다 중간쯤에 자연스러운 이미지가 만들어 진 것이라고 예상할 수 있다.
두 번째 Figure의 Denoising task의 경우를 생각해 보면 어느정도 납득이 간다.
그럼 실제로 성능이 좋을까? 논문에선 여러 실험을 진행했지만, 몇가지만 소개하겠다. 여기서 Not trained는 딱 하나의 이미지만 보고 학습했다는 뜻이다.
-
8x Super Resolution

-
Inpainting

그럼 이렇게 좋은데 문제가 없을까? 가장 큰 한계는 이런 복원 과정이 단 하나의 이미지에만 가능하다는 점이다. 그렇다고 시간이 짧게 걸리는 것도 아닌게 30분정도 걸린다고 한다. 메타학습 기법을 응용하면 발전 할 수 있지 않을까?

Leave a comment