관련 링크 : https://arxiv.org/abs/1905.08233
Style Transfer : Talking Head Model using Few-shot Adversarial Learning(2019)
Abstract
매우 현실적인 사람의 사진은 CNN을 학습시켜 얻을 수 있다. 하지만 특정 사람의 얼굴로 특정 행동을 하는 영상을 만들어내는 데는 많은 데이터셋이 필요하다.
예를들어 사람의 얼굴 landmark와 특정 유명인의 사진을 입력해 그 유명인이 말하는 영상을 만드는 일
하지만 실용적인 응용을 위해서는 몇 장의 사진, 극단적으로 한장만으로 그 사람의 얼굴을 만들 수 있어야 한다. 따라서 본 논문은 대량의 데이터로 메타학습(meta-learning)을 수행해 학습한 후, 이때 사용되지 않은 소량의 데이터로 few-shot learning을 수행하는 모델을 제안한다.
간단히, 모델에게 사람의 말하는 사진을 만드는 방법을 가르치고, 만들고자 하는 사람의 얼굴 정보를 가르쳐 주어 소량의 데이터로 성공적인 결과물을 만들어 낼 수 있다.
1. Introduction

논문의 목적은 Target의 Landmarks를 이용해 Source Style의 Result를 만드는것. 사람 사진의 Source는 8장, 예술 작품들은 1장만 가지고 학습시켰다.
본 논문에서는 face landmark가 주어졌을때 진짜 사진같은 특정 인물의 사진을 만드는 문제를 다룬다. 이 사진은 다음의 조건을 만족해야 하는데, 이는 매우 까다롭다.
- 얼굴을 모델링하면서 구강구조, 헤어스타일, 착용한 옷을 모델링 해야함
- 위 요소들을 명확히 구현하면서 인지의 골짜기에 빠지지 않아야 함
기존 방식 중 하나인 warping-based synthesis은 각 요소의 이미지들을 뒤틀어 합치는 방식이였는데, 하나의 이미지로도 만들어 낼 수 있지만 움직임의 정도나 머리의 회전을 위 조건을 만족하면서 조절하려면 많은 데이터가 필요했다.
이에 gan을 이용한 방식인 Direct(warping-free) synthesis가 부상했다. 하지만 이는 매우 큰 모델을 학습할 필요가 있었고 몇분길이의 영상이나 많은 이미지 데이터를 요구하면서도 학습하는데 오랜 시간을 소요했다. 이 방식은 정교한 물리/광학 시스템을 이용해 이미지를 만드는 것 보다는 실용적이지만 여전히 실제 응용에는 부족했다.
따라서 본 논문은 적은 학습시간과 적은 데이터로도 이를 실현하는 모델을 제안한다. 순서는 다음과 같다.
- 다양한 외관의 사람들이 나타나는 대량의 talking head video로 메타학습하여 few-shot learning ability를 얻는다. 구체적으로, 비디오에서 가져온 동일한 인물의 사진 여러장과 face landmark를 이용해 face landmark와 동일하면서 현실적인 이미지를 만드는 작업을 학습한다.
Face landmark로 사람의 이미지를 만드는 방법을 학습하므로 메타학습이다.
- 소량의 새로운 사람 사진을 이용해 adversarial learning을 수행하여 적은 학습으로도 입력한 사람의 특징을 가진 현실적인 이미지를 만든다.
Landmark로 이미지를 만드는 법을 배웠으므로, 내가 원하는 인물 사진을 만들도록 fine-tuning한다.
2. Related work
-
Face modeling : talking head modeling과 깊은 연관이 있으나, talking head가 더 복잡함
-
Adaptive Instance Normalization(AdaIN) : 주로 조건 생성 모델에 이용되고 논문에서는 메타학습을 위해 사용되었다.
- Batch Normalization : $\mathrm{BN}(x)=\gamma\left(\frac{x-\mu(x)}{\sigma(x)}\right)+\beta$
- \[\mu_c(x)=\frac{1}{NHW}\sum^N_{n=1}\sum^H_{h=1}\sum^W_{w=1}x_{nchw}\]
- \[\sigma_c(x)=\sqrt {\frac{1}{NHW}\sum^N_{n=1}\sum^H_{h=1}\sum^W_{w=1}(x_{nchw}-\mu_c(x))^2+\epsilon}\]
- Instance Normalization : $\mathrm{IN}(x)=\gamma\left(\frac{x-\mu(x)}{\sigma(x)}\right)+\beta$
- \[\mu_{nc}(x)=\frac{1}{HW}\sum^H_{h=1}\sum^W_{w=1}x_{nchw}\]
- \[\sigma_{nc}(x)=\sqrt {\frac{1}{HW}\sum^H_{h=1}\sum^W_{w=1}(x_{nchw}-\mu_{nc}(x))^2+\epsilon}\]
- Adaptive instance Normalization : $\mathrm{AdaIN}(x, y)=\sigma(y)\left(\frac{x-\mu(x)}{\sigma(x)}\right)+\mu(y)$
- $\mu$와 $\sigma$의 식은 $\mathrm{IN}$과 같지만, $\gamma$와 $\beta$가 상수가 아닌 입력 style $y$의 mean과 variance로 바뀌었다.
- Style transfer에서 사용된 Conditional Instance Normalization의 변형이다.
- 이 영상에 잘 설명되어 있다.
- Batch Normalization : $\mathrm{BN}(x)=\gamma\left(\frac{x-\mu(x)}{\sigma(x)}\right)+\beta$
-
Model-Agnostic Meta-Learner(MAML) : 이미지 분류를 위한 분류기의 초기 상태를 얻기 위해 메타학습을 이용하는데, 학습에서 보지 못한 몇몇 데이터만 가지고 빠르게 학습시키는 방법을 제안했다. 본 논문에서 몇몇 아이디어를 이용했다.
3. Methods
3.1 Architecture and notation

메타학습 단계에서 Embedder에 동일 비디오의 여러 사진들을 넣고, 결과를 평균내 embedding vector를 만들고, AdaIN으로 Generator의 파라미터를 조정한다. Generator에는 Embedder에서 사용하지 않은 이미지의 Landmarks를 가지고 Synthesized를 만들고 Ground truth와 비교한다. Discriminator는 Synthesized의 Realism score는 낮게, Ground truth는 높게 만들도록 학습시킨다.
- 공통사항
- $\mathbf x_i(t)$ : $i$번째 비디오의 $t$번째 프레임
- $\mathbf y_i(t)$ : $\mathbf x_i(t)$의 landmark image
-
Embedder :
\[E(\mathbf x_i(s), \mathbf y_i(s);\phi)=\hat{\mathbf e}_i(s)\]- $\hat{\mathbf e}_i(s)$는 $N$-dimensional embedding vector로, 네트워크 파라미터 $\phi$는 $\hat{\mathbf e}_i(s)$가 특정 프레임 $s$에서의 자세, 표정등과 무관한 그 사람의 특징같은 person-specific한 정보가 되도록 한다.
-
Generator :
\[G(\mathbf y_i(t), \hat{\mathbf e}_i;\psi, \mathbf P)=\mathbf{\hat x}_i(t)\]- $\hat{\mathbf x}_i(t)$ : $\mathbf y_i(t)$를 이용해 만들어낸 합성 이미지
- Generator의 파라미터는 person-generic $\psi$와 person-specific $\hat\psi$로 이루어진다. $\psi$는 직접 학습되지만 $\hat\psi$는 $\hat\psi=\mathbf P \hat{\mathbf e}_i$로 구한다.
-
Discriminator :
\[D(\mathbf x_i(t), \mathbf y_i(t), i;\theta, \mathbf W, \mathbf w_0, b)=r\]- 출력으로 $N\text{-dimensional vector}$를 만드는 ConvNet $V(\mathbf x_i(t), \mathbf y_i(t); \theta)$와 이를 Projection하는 부분으로 구성되고, 입력된 이미지 $\mathbf x_i(t)$가 $i$번째 비디오에 실제로 있는지, $\mathbf y_i(t)$와는 일치하는지를 나타내는 realism score $r$를 출력한다.
- $\mathbf W$ : $i$번째 비디오와 관련되어 person-specific한 정보와 관련된다.
- $\mathbf w_0$, $b$ : person-generic한 정보와 관련된다.
3.2 Meta-learning stage
메타학습 단계에서 세 가지 네트워크를 모두 학습시키는데, 이때 $K$-shot learning을 이용한다. 실험에서는 $K=8$을 이용했다. 즉, 동일한 $i$번째 비디오에서 $K$개의 프레임($s_1$, $s_2$, $\ldots$, $s_K$)을 가져와 사용했다. $\hat{\mathbf e}_i$는 하나여야 하므로
\[\hat{\mathbf e}_i(s)=\frac {1}{N}\sum^K_{k=1}E(\mathbf x_i(s_k), \mathbf y_i(s_k);\phi) \tag 1\]를 이용해 구하고, Embedder와 Generator는 다음 loss function을 최적화하여 학습시켰다.
\[\mathcal L(\phi,\psi,\mathbf P,\theta, \mathbf W, \mathbf w_0, b) = \mathcal L_{\mathrm {CNT}}(\phi,\psi,\mathbf P) + \mathcal L_{\mathrm{ADV}}(\phi,\psi, \mathbf P,\theta, \mathbf W,\mathbf w_0, b)+\mathcal L_{\mathrm {MCH}}(\phi,\mathbf W) \tag 3\]- $\phi$ : Embedder의 파라미터
- $\psi, \mathbf P$ : Generator의 파라미터
- $\theta, \mathbf W, \mathbf w_0, b$ : Discrimminator의 파라미터
- $\mathcal L_\mathrm{CNT}$ : ground truth $\mathbf x_i(t)$와 $\hat{\mathbf x}_i(t)$의 유사하게 만들기 위해 사용한 perceptual loss로, VGG19와 VGGFace를 이용해 두 개를 구한 후 가중합해 사용했다.
- Per-pixel loss function : 두 이미지간에 픽셀 값으로 $\ell_1$ 혹은 $\ell_2$ distance를 계산하여 구성됨
- Perceptual loss function : pretrained된 모델을 통해 얻은 high-level representation의 값으로 distance를 계산하여 구성됨. 논문에서 언급한 Perceptual Losses for Real-Time Style Transfer and Super-Resolution의 그림으로, 생성된 이미지와 타겟 이미지의 representation을 비교함.

- $\mathcal L_\mathrm{MCH}$ : $\hat{\mathbf e}_i$와 $\mathbf W_i$간의 $L_1$-difference에 페널티를 부과해 두 종류의 embedding의 유사도를 증가시키기 위해 사용했다.
-
$\mathcal L_\mathrm{ADV}$ : Discriminator의 출력 realism score $r$를 최대화 하고, 학습 안정성을 위해 Discriminator를 이용한 perceptual loss로 이루어져 있다.
\[\mathcal L_\mathrm {ADV}(\phi, \psi, \mathbf P, \theta, \mathbf W, \mathbf w_0, b)=-D(\hat{\mathbf x}_i(t),\mathbf y_i(t),i;\theta,\mathbf W, \mathbf w_0, b)+\mathcal L_\mathrm{FM}\tag 4\]-
Realism score $r(=D)$ :
\[D(\hat{\mathbf x}_i(t),\mathbf y_i(t),i;\theta,\mathbf W, \mathbf w_0, b)=V(\hat{\mathbf x}_i(t), \mathbf y_i(t);\theta)^T(\mathbf W_i+\mathbf w_0)+b \tag 5\]- $V$는 앞서 언급했듯 Discriminator의 일부인 ConvNet이다.
- $\mathbf W$의 $i$번째 열은 $i$번째 비디오(혹은 스타일)와 관련되있고, $\mathbf w_0$와 $b$는 landmark 및 $\hat{\mathbf x}_i$의 일반적인 특성과 관련되어 있다.
-
$\mathcal L_\mathrm {FM}$ : $\mathcal L_\mathrm{CNT}$와 유사하지만, 사용된 네트워크가 Discriminator의 $V$이다.
-
언급된 논문의 식에 따르면 다음과 같다.
\[\mathcal L_\mathrm{FM}(G, D_k) =\mathbb E_{(\mathbf s, \mathbf x)}\sum ^T_{i=1}\frac{1}{N_i}[\|D^{(i)}_k(\mathbf s,\mathbf x)-D^{(i)}_k(\mathbf s,\mathbf G(s))\|_1]\]
-
-
앞의 방법으로 Embedder의 $\phi$와 Generator의 $\psi$를 학습 시키고, Discriminator의 $\theta, \mathbf W, \mathbf w_0, b$를 학습시켰다.
\[\mathcal L_\mathrm {DSC}(\phi, \psi, \mathbf P, \theta, \mathbf W, \mathbf w_0, b)=\\\max(0,1+D(\hat{\mathbf x}_i(t),\mathbf y_i(t),i;\phi,\psi,\theta,\mathbf W, \mathbf w_0, b))+\\\max(0, 1-D(\mathbf x_i(t),\mathbf y_i(t),i;\theta,\mathbf W, \mathbf w_0, b)) \tag 6\]- 만들어진 이미지 $\hat{\mathbf x}_i(t)$의 $r$은 작게(첫 번째 $\max$), 실제 이미지 $\mathbf x_i(t)$의 $r$은 크게(두 번째 $\max$) 만들도록 학습시킨다.
위 과정을 메타학습이 완료될때 까지 반복한다.
3.3 Few-shot learning by fine-tuning
메타학습이 끝나면 메타학습에서 사용하지 않은 데이터와 landmark를 이용해 특정 스타일(사람)의 사진을 만든다. 이때 메타학습과 유사하게 $T$개의 이미지로 스타일을 학습한다. 이 이미지들 역시 landmark가 있어야하고, $T$의 값이 $K$와 같을 필요는 없다. 메타학습에서 이용하지 않은 새로운 스타일(사람)의 이미지를 원하므로 $i$는 필요없고, 따라서 Embedder의 출력은
\[\hat{\mathbf e}_\mathbf {NEW}=\frac {1}{N}\sum^T_{t=1}E(\mathbf x(t), \mathbf y(t);\phi) \tag 7\]이다. 이것만 이용해도 어느정도 괜찮은 이미지를 만들 수 있으나 더 나은 이미지를 위해 fine-tuning한다. 이 과정은 메타학습 단계와 유사하지만 약간의 차이가 있다.
-
Generator : $G(\mathbf y(t),\hat{\mathbf e}_\mathbf{NEW};\psi,\mathbf P)\rightarrow G’(\mathbf y(t);\psi,\psi’)$
- $\hat e_i(t)$와 $\mathbf P$를 이용해 계산해서 사용한 person-specific 파라미터 $\psi’$도 $\psi$와 함께 학습하고, $\psi’=\mathbf P\hat{\mathbf e}_\mathbf{NEW}$로 파라미터의 초기값을 설정한다.
-
Discriminator : $D(\mathbf x_i(t), \mathbf y_i(t), i;\theta, \mathbf W, \mathbf w_0, b)$
\[\rightarrow D'(\mathbf x(t),\mathbf y(t);\theta,\mathbf w', b)=V(\hat{\mathbf x}(t),\mathbf y(t);\theta)^T\mathbf w'+b \tag 8\]- 메타학습에서 사용한 데이터를 사용하지 않으므로 $i$가 없고, 따라서 $\mathbf W_i$도 사용할 수 없다. 그 대신, $\mathcal L_\mathrm{MCH}$를 이용해 $\hat e_i$와 $\mathbf W_i$간의 유사도를 증가시도록 학습시켰으므로, $\mathbf w’=\mathbf w_0+\hat e_\mathrm{NEW}$로 초기화시킨다.
위 과정을 통해 각 모델의 파라미터를 새롭게 초기화 시킨 후, 메타학습과 유사하게 Generator부터 학습시킨다.
\[\mathcal L'(\psi,\psi',\theta,\mathbf w', b)=\mathcal L'_\mathrm {CNT}(\psi,\psi')+\mathcal L'_\mathrm{ADV}(\psi,\psi',\theta,\mathbf w', b) \tag 9\]이후 Discriminator를 학습시킨다.
\[\mathcal L'_\mathrm{DSC}(\psi,\psi',\theta,\mathbf w',b)=\\\max(0, 1+D(\hat{\mathbf x}(t), \mathbf y(t);\psi,\psi',\theta,\mathbf w', b))+\\\max(0,1-D(\mathbf x(t),\mathbf y(t);\theta,\mathbf w', b)) \tag {10}\]위 과정을 fine-tuning이 완료될때 까지 반복한다. Embedder의 파라미터 $\phi$는 학습시키지 않음을 주의해야 한다.
3.4 Implementation details
- Generator : 위에서 소개한 Perceptual loss 논문의 구조를 가져와 down/upsampling을 residual block으로 대체하고, BN을 AdaIN이나 IN으로 바꿨다.
- Embedder : Generator에 사용된 것과 같지만 normalization layer는 다른 residual downsampling block으로 구성했다. 벡터 출력을 얻기위해 마지막에 해상도에 관해 global sum pooling와 ReLU를 추가했다.
- Discriminator : Embedder와 동일하지만 마지막 pooling전에 $4\times 4$의 residual block을 추가해주었다.
- 모든 모델에 공통적으로 spectral normalization을 적용했고 Generatord의 upsampling part와 모든 네트워크의 downsampling part에 self-attention block을 사용했다.
Spectral normalization : 이 논문에서 처음 제시했으며, 간단한 구현과 적은 계산량으로 효율적인 하이퍼 파라미터 튜닝을 가능하게 해주는 방법으로 weight normalization의 일종이다.
- 학습동안 Generator와 Embedder를 학습할때마다 Discriminator는 두 번씩 학습시켰다.
- 그 외 자세한 수치들은 원문을 찾아보기 바란다.
4. Experiments
-
Datasets : VoxCeleb1(256p, 1fps 비디오)와 VoxCeleb2(224p, 25fps 비디오)를 사용했다. 전자는 baseline 비교와 ablation studies에, 후자는 최고성능을 보이는데 사용했다.
- Metrics
- Frechet-inception distance (FID) : 실제 데이터와 생선된 데이터에서 얻은 feature의 평균과 공분산을 비교하여 구함. 이때 사용하는 네트워크는 Inception 네트워크라 inception distance라고 부른다.
- Structured Similarity (SSIM) : ground truth와의 low-level similarity를 측정
- Cosine Similarity (CSIM) : SOTA face recognition 네트워크와 본 모델의 embedding vector간 CSIM
- USER : 사람응답자에게 원본 두 장, 생성된 이미지 한장을 보여주었을때 생성된 이미지를 선택한 비율
- Methods
- X2Face : Warping-based method의 baseline으로, 원저자가 제공한 pretrained model을 이용했다. 이미지를 생성할때 direct method와 달리 landmark보다 많은 정보를 포함한 입력(ground truth를 계산하여 얻고, 불공정한 이점이 된다)을 사용했다.
- Pix2pixHD : Direct synthesis method의 baseline으로, 원저자가 제안한 방법으로 모델을 구성하고 본 논문의 모델과 동일한 데이터로 처음부터 학습시켰다. Direct method라 본 논문의 방법과 마찬가지로 fine-tuning할때 X2Face에 비해 40 에폭 더 필요했다.
- Comparison results
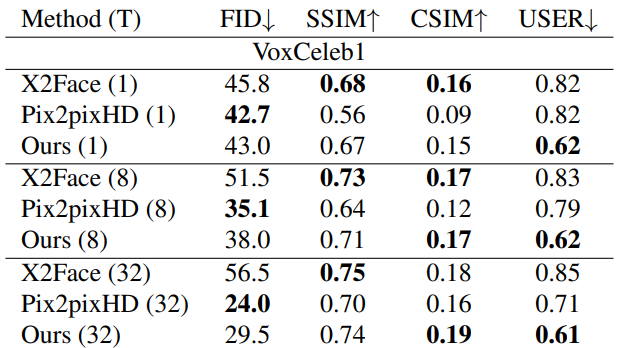
$T$는 fine-tuning에서 모델이 본 이미지의 수이다.
- X2Face는 학습과정에서 $L_2$ loss를 사용하므로 SSIM이 높다.
- Pix2pixHD는 perceptual loss만을 이용해 학습하므로 FID는 낮지만 identity perservation을 고려하지 않아 CSIM이 낮다.
CSIM은 최종 이미지의 품질과 관련이 높지만, 이미지의 현실성이나 blurry등은 고려하지 못한다.
- 사실상 USER를 제외하면 Uncanny Valley를 고려하지 않으므로 의미 없을 수 있다.
- 아래는 VoxCeleb1로 학습된 모델을 이용해 생성한 이미지들이다.

- Large-scale results

FF는 $\mathcal L_\mathrm{MCH}$ 없이 메타학습을 진행하고, fine-tuning없이 사용한 모델이고, FT는 논문에서 언급한 방식대로 학습한 모델이다.
- 학습에 사용된 이미지의 수가 적을수록 fine-tuning이 없어 바로 사용 가능한 FF의 성능이 좋지만, 많아지면 FT가 더 좋아진다.
- 32장의 이미지로 학습한 FT는 USER의 최고점 0.33을 달성했다.
- 아래는 VoxCeleb2로 학습된 모델을 이용해 생성한 이미지들이다.

- Puppeteering results

One-shot Model을 이용해 생성한 이미지들이다.
5. Conclusion
- 메타학습과 GAN을 이용해 성능이 좋은 구조를 제안했다.
- Landmark들은 어느 방향을 쳐다보는지를 표현하지 않아 시선처리등에 한계점이 있다.
- 스타일의 사람과 다른 사람의 landmark를 사용하면 성능이 악화되므로, landmark adaption이 필요하다.
Leave a comment