관련 링크 : https://arxiv.org/abs/1812.10025
Visualization : ABN(2018)
Abstract
Visual explanation은 사람이 CNN의 의사 결정 과정을 이해하는 것을 가능하게 해준다. 하지만 CNN의 성능을 개선하는데 사용되지 않았다. 본 논문에서는 Visual explanation을 위한 attention map을 이용해 Attention mechanism을 도입해 성능을 상당히 증가시킨다.
Attention map은 모델이 어떤 문제에 대한 답을 도출할 때 집중적으로 보는 attention location에 높은 response value를 표현한 Feature map이다.
논문이 제시하는 방법은 Attention Branch Network로 reponse-based visual explanation model인 CAM을 확장시켜 attention mechanism을 도입한 branch structure를 사용한다. ABN은 이미지 인식과 visual explanation을 동시에 end-to-end로 학습 할 수 있다는 장점을 가진다.
마지막으로, 본 논문은 ABN을 image classification, fine-grained recognition, multiple facial attribute recognition의 task에서 성능을 평가하고, attention map을 사용하는것이 효과가 있음을 밝힌다.
1. Introduction
CNN이 다양한 visual task에서 좋은 성능을 보였지만, 여전히 CNN이 어떤 방식으로 결과를 도출하는지 설명하기는 어렵다. Visual explanation은 inference process에서 top-down 방식으로 attention location을 강조하면서 CNN을 설명하기 위해 사용된다. 이는 크게 두 종류로 나뉘는데, 하나는 Gradient-based이고, 다른 하나는 Response-based이다.
Gradient-based는 gradient를 이용해 이미지의 특정 부분이 최종 출력에 끼치는 영향을 계산하는 방식으로, 모델을 재학습하거나 수정하는것 없이 CNN을 설명할 수 있지만, gradient를 계산하기 위해 back propagation이 필요하다. 대조적으로 Response-based는 backprop이 없는 inference process에서 CNN의 visual explanation을 할 수 있지만 사용하기 위해 모델 구조를 바꿔야한다. 대표적으로 CAM이 있다.
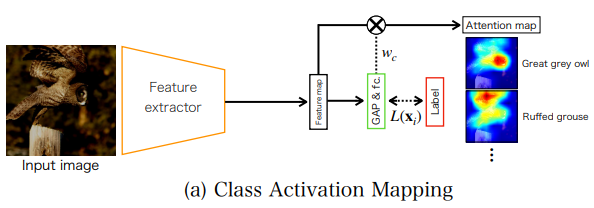
하지만 CAM은 FCL를 conv와 GAP로 대체하므로 CNN의 성능을 감소시킨다. 이 때문에 visual explanation을 위해서는 gradient-based가 종종 사용되었다. 하지만 본 논문은 attention mechanism을 도입하기 위해 forward pass에서 visual explanation을 사용해야 하므로 response-based method인 CAM을 사용한다.
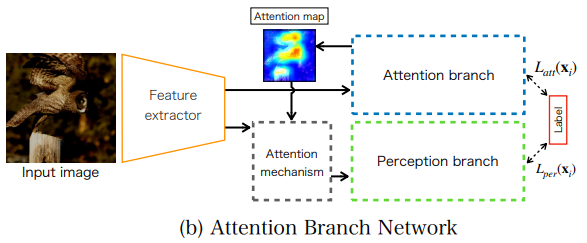
최종적인 Attention Branch Network는 위 그림과 같이 세 부분으로 나뉘고, 각각 feature extractor, attention branch, perception branch이다. Feature extractor는 다수의 Conv layer로 feature map을 만든다. Attention branch는 visual explanation과 attention mechanism을 위한 attention map을 만들고, 가장 중요하다. Perception branch는 feature map과 attention map을 이용해 class probability를 예측한다.
ABN은 다음과 같은 장점을 가진다.
- Visual explanation을 도입하면서 성능을 향상시킨 최초의 연구이다.
- 다양한 Backbone 모델에 사용 가능하다.
- Forward propagation동안 성능 향상과 시각화를 모두 수행한다.
2. Related work
- Interpreting CNN
- Gradient-based visual explanation : Guided backpropagation/Grad-CAM
- Forward/Backward pass가 모두 필요
- 모델을 수정하거나 재학습 시킬 필요 없이 바로 visual explanation 가능
- Response-based visual explanation : CAM
- Forward pass만으로 가능해 논문의 Attention mechanism 적용 가능
- 특정 모델을 재학습하거나 수정해야함
- Gradient-based visual explanation : Guided backpropagation/Grad-CAM
- Attention mechanism : 주로 sequential model에 사용되었으나, 최근에 이미지에도 사용됨
3. Attention Branch Network
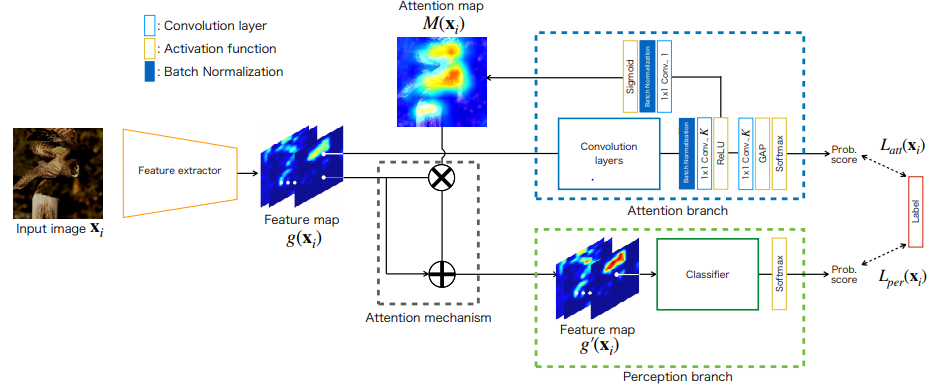
위에서 언급했듯 ABN은 세 부분으로 나뉜다. 그 중 feature extractor는 일반적인 VGGNet, ResNet과 유사하므로 따로 설명하지 않고, 나머지 두 부분만 설명한다.
3.1 Attention branch
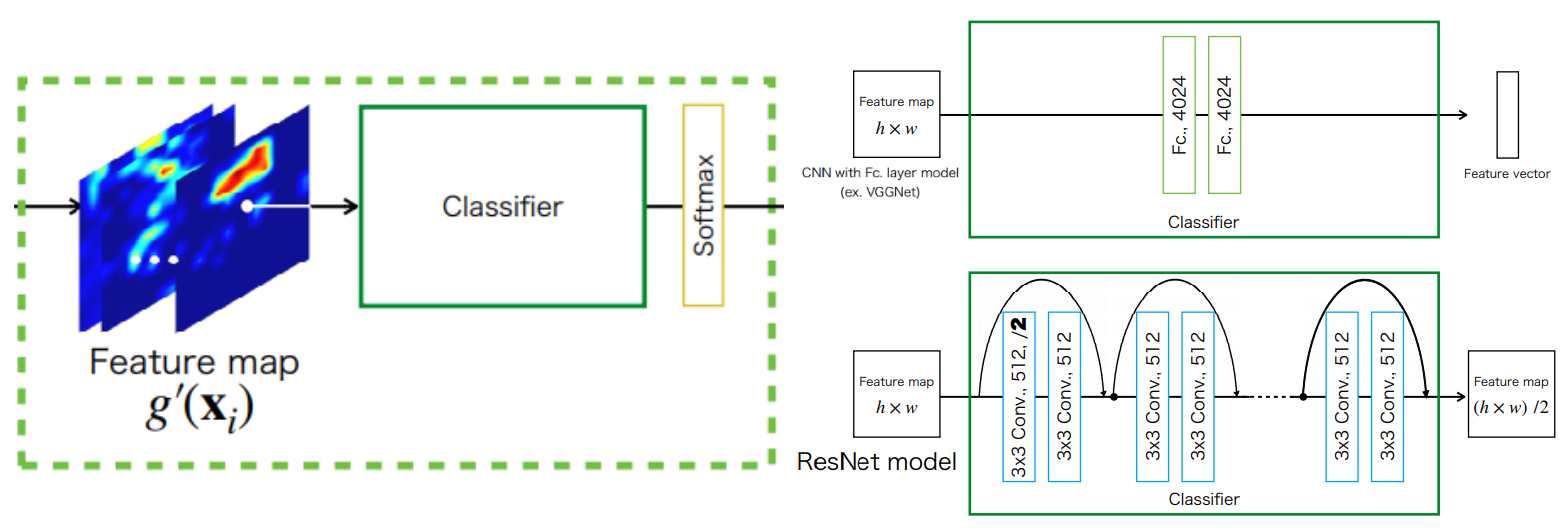
CAM은 마지막에 $K\times3\times3 \;\mathrm{Conv}$, $\mathrm{GAP}$, $\mathrm{\text{FCL with Softmax}}$를 가진다. $\mathrm{Conv}$층은 $K\times h\times w$를 출력한다. 이때 $K$는 클래스의 수를 의미하므로, 출력은 각 클래스의 attention location을 나타낸다. 이후 $\mathrm{GAP}$를 통해 1x1 feature map으로 down-sample되고, $\mathrm{\text{FCL with Softmax}}$를 거쳐 class probability을 출력한다. 마지막으로 Visualization를 위해 $\mathrm{FCL}$의 weight와 $\mathrm {Conv}$의 feature map을 multiply하여 각 클래스의 attention map을 만든다. 또한 모델의 $\mathrm{FCL}$를 $3\times 3\;\mathrm{Conv+GAP}$로 대체한다. 이는 VGGNet과 같은 $\mathrm{FCL}$를 가진 baseline 모델들이 $\mathrm{GAP}$로 사용했을때 성능이 저하되는 것을 보상하면서, $\mathrm{FCL}$로 인해 사라지는 localization 정보를 보존한다.
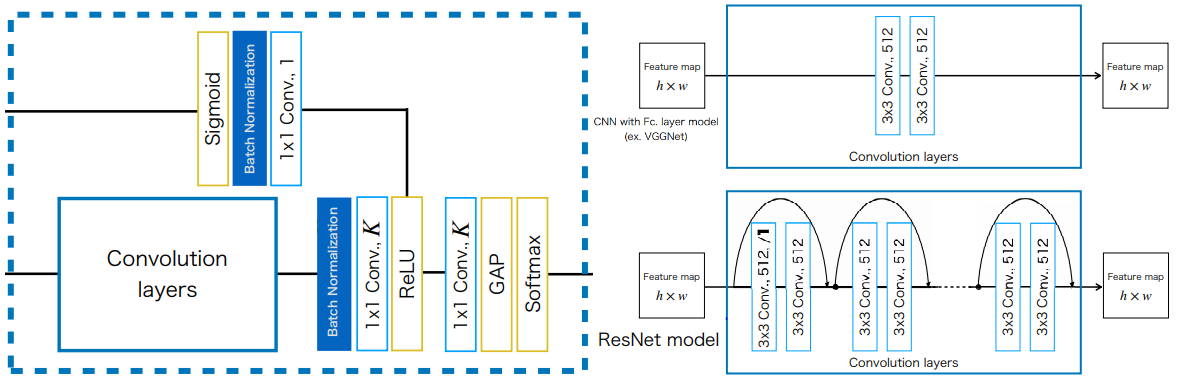
Attention branch에서 Convolution layers중 CNN with $\mathrm{FCL}$의 경우 기존 네트워크라면 $\mathrm {FCL}$이 나오는 부분이지만 $\mathrm {Conv}$으로 대체되었다.
Attention branch는 CAM과 유사하지만, attention mechanism을 학습에 적용시키기위해 구조가 약간 다르다. CAM같은 경우 모델의 학습이 끝나고, 그 모델의 feature map과 $\mathrm{Softamx}$의 $\mathrm{FCL}$이 가지는 weight를 사용하기 때문에 학습 도중에 이를 활용할 수 없다. 하지만 ABN은 attention map을 학습에 활용할 것이므로, 이를 위해 $\mathrm{Softmax}$의 $\mathrm{FCL}$을 $K\times 1\times 1\;\mathrm{Conv}$로 대체하여 각 클래스의 attention location $K\times h \times w$를 만들고 $1\times 1\times 1\;\mathrm{Conv}$를 통해 attention map을 만든다. 이와 함께 다른 갈래로 $\mathrm{GAP}$를 이용해 각 class probability 또한 출력한다.
3.2 Perception branch
Perception branch는 Attention branch와 Feature extractor에서 만든 feature map과 attention map을 모두 이용해서 최종적인 class probability를 만든다. 식으로 다음과 같이 간단히 나타낼 수 있다.
\[g'_c(\mathrm x_i) = M(\mathrm x_i)\cdot g_c(\mathrm x_i) \tag 1\]- $g_c(\mathrm x_i)$ : feature map, $M(\mathrm x_i)$ : attention map
(1)식에 비해 attention map에서 높은 값을 강조하면서 낮은 값이 0이 되지 않도록 식을 다음과 같이 수정할 수 있다.
\[g'_c(\mathrm x_i) = (1+M(\mathrm x_i))\cdot g_c(\mathrm x_i) \tag 2\]3.3 Training
ABN은 두 branch를 모두 사용하여 학습한다.
\[L(\mathrm x_i)=L_{att}(\mathrm x_i)+L_{per}(\mathrm x_i) \tag 3\]- $L_{att}(\mathrm x_i)$ : attention branch의 training loss
- $L_{per}(\mathrm x_i)$ : perception branch의 training loss
각 branch의 loss는 일반적인 classification과 동일한 $\mathrm{Softmax}$와 $\mathrm{CrossEntropy}$이다.
3.4 ABN for multi-task learning
ABN은 대부분의 image recogniton task에 적용가능하고, multi-task learning에도 마찬가지이다. 하지만 기존 구조는 하나의 attention map만 만들어 multi-task learning에는 적합하지 않다. 따라서, 각 task당 하나의 attention map을 만들도록 아래와 같이 구조를 바꾼다.
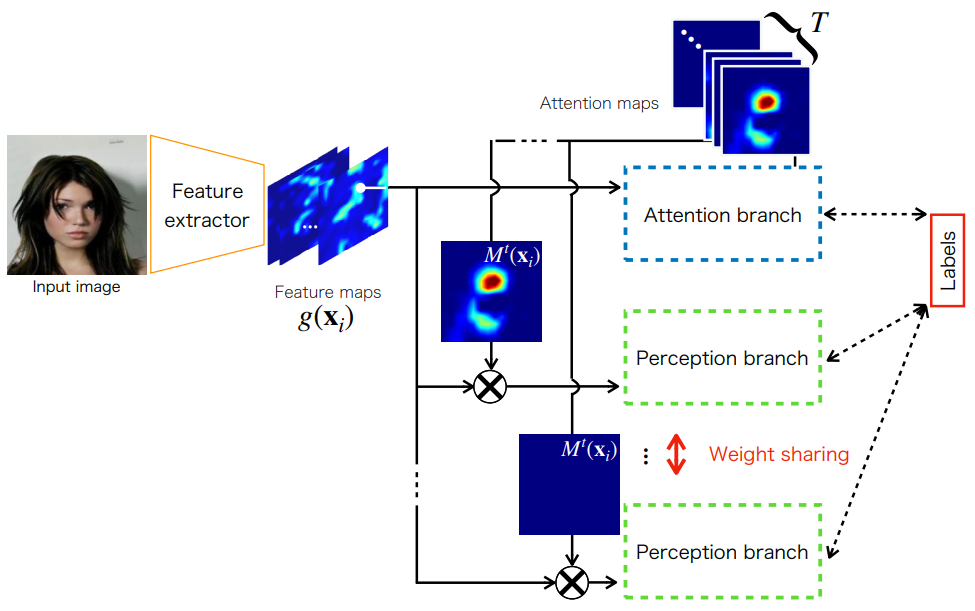
위 구조는 feature map에 $T\times 1 \times 1\;\mathrm{Conv}$를 적용해 $T\times h \times w$를 만든 후, 이를 이용해 $\mathrm{GAP}$를 통해 probability를, 다른 쪽으로는 각 task $t$에 해당하는 attention map을 만든다. 그리고 이후 과정은 기존의 ABN과 유사하게 다음 식으로 나타낼 수 있다.
\[g'^t_c(\mathrm x_i)=M^t(\mathrm x_i)\cdot g_c(\mathrm x_i) \tag 4\] \[\mathrm O(g'^t_c(\mathrm x_i))=p_{per}(g'^t_c(\mathrm x_i);\theta) \tag 5\]- $\mathrm O(g’^t_c(\mathrm x_i))$ : 각 task의 probability matrix, task의 category가 2라면 $T\times 2$이다.
4. Experiments
4.1 Experimental details on image classification
- SGD with momentum
- Batchsize : $256$
- Training Epochs
- CIFAR10/CIFAR100 : $300$
- SVHN : $40$
- ImageNet : $90$
- Learning Rate Scheduler
- Initial lr $0.1$, divided by $10$ at $50\%$, $75\%$ of total epochs
- Data Augmentation
- CIFAR10/CIFAR100/SVHN : $32\times 32$ images
- $4$ pixel zero padding and $32\times 32$ random cropping
- Random horizontal flipping
- ImageNet : $224\times 224$ images
- Resize to $256\times256$ and $224\times224$ random cropping
- Random horizontal flipping
- CIFAR10/CIFAR100/SVHN : $32\times 32$ images
4.2 Image classification
Analysis on attention mechanism : Attention map을 이용할때 단순히 곱하는 것(1)과 곱하고 더하는 것(2)의 차이를 비교해본다. 실험에는 CIFAR100을 사용했다.
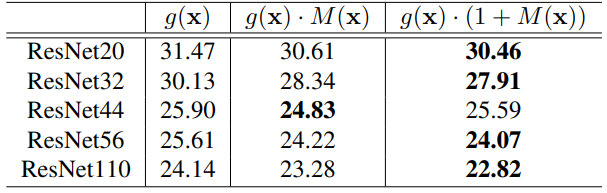
대부분의 경우 후자가 효과가 더 좋았으므로, 별다른 언급이 없으면 후자를 사용한다.
Accuracy on CIFAR, SVHN and ImageNet : 각 데이터셋에서 다양한 모델의 Baseline, CAN, ABN의 성능을 평가한다.
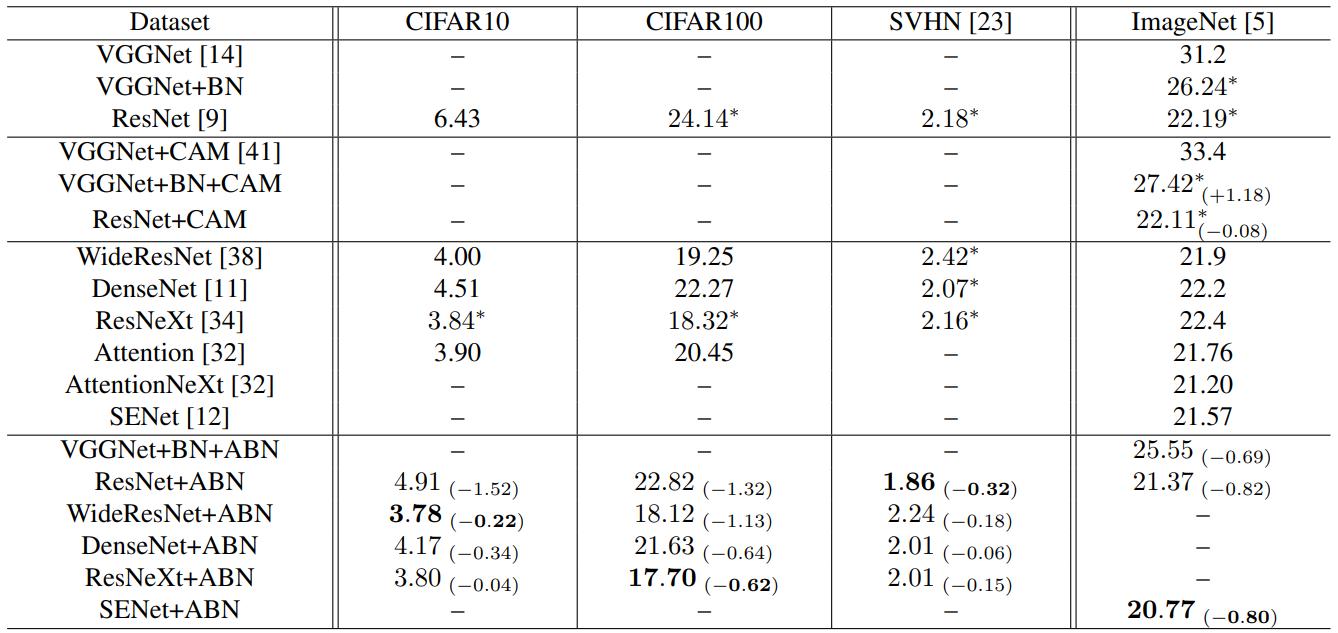
$*$는 원문에서 가져온 성능이 아닌 재실험해서 얻은 성능
- CAM은 $\mathrm{FCL}$를 제거하기 때문에 VGGNet+BN+CAM의 경우는 오히려 성능이 떨어지지만, ResNet+CAM에서는 소폭 상승한다.
- ABN은 어떤 모델을 사용하더라도 성능이 향상된다.
Visualizing attention maps : Grad-CAM, CAM, ABN의 시각화 성능을 비교한다.
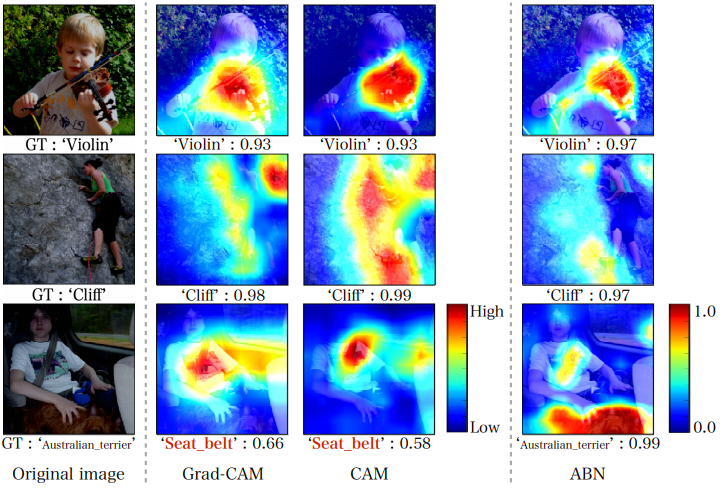
top-1 result의 attention map을 시각화 함
- 세 모델 모두 어느정도 정확한 부분을 강조하지만, ABN이 더 디테일 하다.
- 세번째 행의 경우 전형적인 multi object problem인데, Grad-CAM과 CAM은 seat belt를 강조한 반면 ABN은 정확히 australian terrier를 강조하면서, seat belt까지 강조한다. 즉, 이미지에 다수의 물체가 존재해도 잘 작동한다.
4.3 Fine-grained recognition
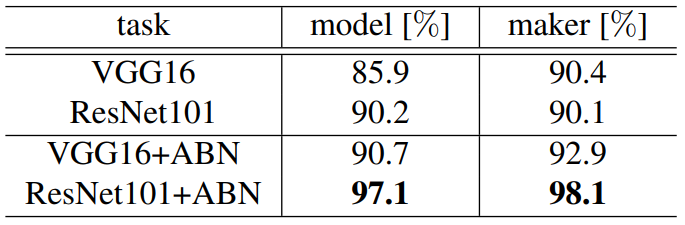
복합적인 자동차 데이터셋 CompCars를 이용해 ABN의 fine-grained recognition 성능을 평가한다. CompCars는 $75$개의 메이커들의 $432$ 종류의 자동차들을 가진 $36,451$개의 훈련용, $15,626$개의 테스트용 이미지로 이루어진다.실험에는 VGG16, ResNet101을 사용한다.
Fine-grained recognitoin이란 동일한 카테고리에 속하는 여러 물체들의 차이를 인식하는 것이다.

Experimental details
- SGD with momentum
- Batchsize : $32$
- Training Epochs : $50$
- Learning Rate Scheduler
- Initial lr $0.01$, divided by $10$ at $25$, $35$ epochs
- Resizing image to $323\times224$ with maintaining aspect ratio
Results
-
ABN을 쓴 모델의 성능이 더 좋다.
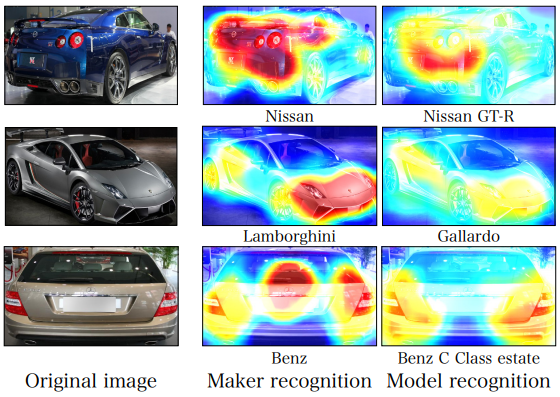
-
결과를 시각화해보면 동일한 데이터셋으로 각 task를 학습했음에도 attention map이 다름을 볼 수 있다.
-
ABN을 사용한 모델과 그렇지 않은 모델의 t-SNE를 비교해본다. 사용한 모델은 attention map을 더한 feature이 차량의 자세와 세부적인 차의 형태에 따라 clustering 되지만 그렇지 않은 모델은 차량의 자세에 따라 clustering 된다.

4.4 Multi-task Learning
Multi-task의 한 예인 multiple facial attributes recognition에서 ABN의 성능을 평가한다. 총 $40$개의 facial attributes를 가진 $182,637$개의 훈련용, $19,962$개의 테스트용 데이터셋 CelebA를 이용한다.
Experimental details
- SGD with momentum
- Training Epochs : $10$
- Learning Rate : $0.01$
Results
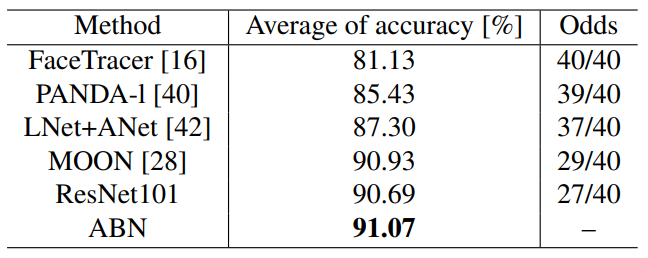
Odds는 40개의 facial attributes에 대해 기존 방법보다 성능이 더 좋은 attributes의 개수
-
ABN이 가장 성능이 좋고, ResNet과 비교했을때도 27개의 facial task에서 성능 향상이 있다.
-
구체적인 facial task에 따른 attetion map을 보면 다음과 같다.

5. Conclusion
- Attention mechanism을 도입해 Response-based visual explanation을 확장한 ABN을 제안한다.
- ABN은 성능을 향상시키면셔 visual explanation를 수행한다.
- 다양한 CNN 모델과 task에 적용 가능하다.
- 추후 강화학습에 적용할 예정이다.

Leave a comment