관련 링크 : https://arxiv.org/abs/2106.14881
- 간단한 Conv Stem으로 학습 안정성을 높일 수 있음을 보임
Intro
ViT는 NLP분야에서 Transformer 모델의 성공에 근거해, CNN의 Locality Prior를 Global Processing으로 대체해 새로운 가능성을 제시했다. ViT 이후 Computer Vision에 다양한 Transformer 연구가 진행되었고, 여러 분야에서 SOTA를 달성했다. 하지만 ViT 계열은 아직 많은 문제점을 가지고 있고, CNN의 지배적인 위치를 빼앗기에는 부족하다. 이는 CNN에 비해 성능의 관점에서 상대적으로 높은 Upper Bound를 가지고 있긴 하지만, 학습 안정성이 떨어져 낮은 Lower Bound를 가지고 있기 때문이다.
학습 안정성이 떨어진다는 말은 Training Scheme을 구성하는 Optimizer의 종류, 하이퍼 파라미터들의 영향이 크다는 뜻이고 이는 CNN 모델에서 통용된 많은 직관들이 통하지 않기 때문이다. 즉, 기존 연구들의 방대한 지식을 사용하기 힘들어지는데 이를 포기할 정도로 Transformer 계열이 아직 뛰어나진 않다.
그렇다면, Transformer의 이런 단점은 어디서 기인한 것일까? 포괄적으로 말하면 대부분 Vision에 적합한 Inductive Bias의 부족이 원인이라고 말한다. 오늘 소개할 논문 역시 큰 맥락에서 Inductive Bias의 부족을 원인으로 지적하며, 가장 많이 지적되는 무식한 패치화 과정을 개선하고자 이를 Conv Layer로 대체한다. 그런데, ViT를 읽어본 사람은 의문이 들 것이다. ViT에서도 패치화 과정의 문제를 인식해 이를 ResNet으로 대체한 후 Hybrid ViT라 지칭해 실험을 진행했고, 그 결과가 큰 차이가 나지 않았음을 봤기 때문이다. 별 차이가 나지 않는걸 확인 했는데, 어떻게 개선했다는 걸까?
Hybrid ViT와 저자들의 방식의 가장 큰 차이점은 ResNet과 같은 깊은 모델을 사용하는게 아니라, 5~7개의 층만 가지는 얕은 모델을 사용하고 비교하는 모델끼리 동일한 연산량을 가지도록 설계해 비교했다는 점이다. ViT에 CNN의 Inductive Bias를 집어 넣으려는 이전 연구들이 Early Local Attention이나 CNN Teacher Model 같은 새로운 방법을 제시했다면, 이 논문은 Navie하게 CNN을 이용해 이를 도입하면서 연산량을 기준으로 동일한 비교를 하려 했다는 것도 다른 점이다.
ViT에서 Hybrid를 먼저 제안 했고, 비슷한 연구들이 있었기 때문에 Novelty가 떨어진다고 생각했는지, 저자들은 최적화된 패치화 방법을 제시하는 논문이 아니라 간단한 Inductive Bias의 도입으로 학습 안정성이 증가한다는 점을 보여주는 논문이라고 강조한다.
그럼 먼저 저자들이 패치화 과정을 담당하는 Patchfy Stem을 Conv Stem으로 어떻게 대체했는지 간단히 살펴보자.
Conv Stem
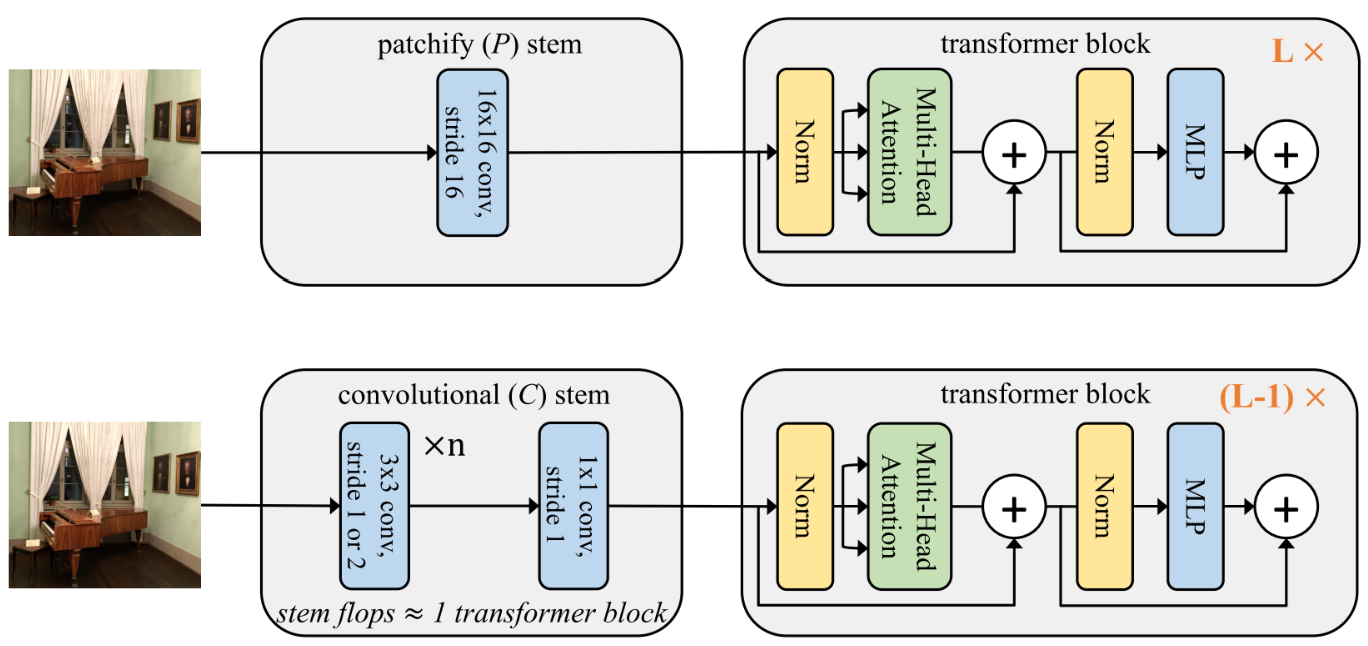
기존 Patchfy Stem($P$)가 Kernel size가 16이고 Stride가 16인 Conv라면, 저자들은 Conv Stem($C$)를 일반적인 CNN 모델 설계에 이용되는 Kernel Size가 3이고 Stride가 1 혹은 2인 Conv를 이용해 만들고, 채널을 맞추기 위해 마지막에 Kernel Size가 1, Stride가 1인 Linear Layer와 동일한 Conv를 붙였다. 그리고 Conv Stem이 Patchfy Stem보다 많은 연산량을 요구할 수 밖에 없기 때문에, 연산량 추가에도 전체 연산량은 동일하게 만들기 위해서 위 그림에서 나타난 것 처럼, Conv Stem의 연산량을 Transformer Block 하나와 동일하게 만든 후 Transformer Block의 층을 하나 제거한다.
위 표 처럼 Conv Stem의 채널은 Stride가 2일 경우 채널 2배, 1일 경우 그대로 만들도록 설계한다. $S1$~$S4$는 비슷한 Flop을 유지하면서 마지막 3x3 Conv를 Patchfy하게 바꿔 크기를 점점 늘린 경우로, $P$에 가깝게 만들 수록 성능이 하락하는 모습을 볼 수 있다.

그리고 기존 ViT의 Tiny, Small, Base, Large 표기 대신에 비교를 용이하게 하기 위해 1GF, 4GF, 18GF, 36GF로 각각 바꿔서 나타내고 각 Stem에 따라 ViT의 아래 첨자로 $C$와 $P$를 붙여 표기한다. 세부사항은 다음과 같다.
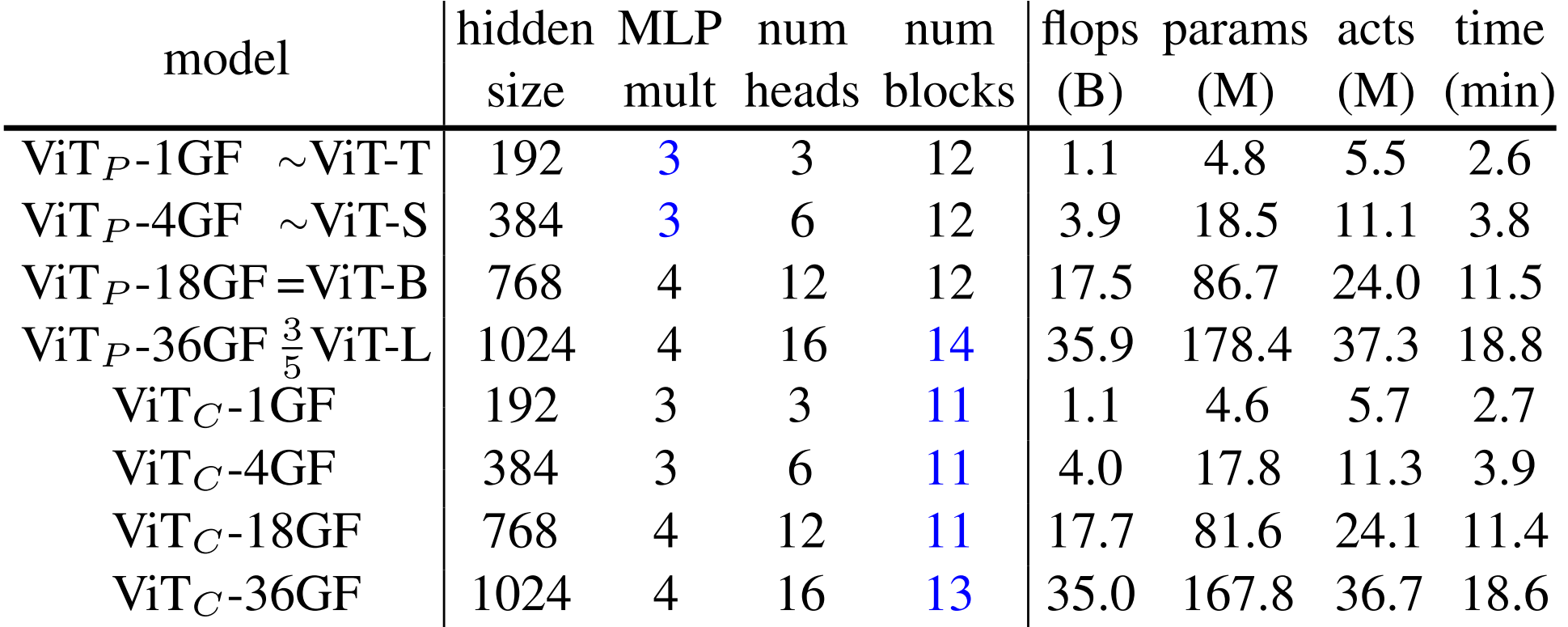
파란 숫자는 Reference 모델에서 수정된 부분을 의미한다. $\text{ViT}_C$ 모델은 대응되는 $\text{ViT}_P$ 모델을 참조해서 만들었다.
Experiments
저자들은 Conv Stem으로 인한 성능 향상보다, 학습 안정성의 변화를 중점적으로 다룬다. 학습 안정성은 총 세 가지를 통해 확인한다. 순서대로 살펴보자.
-
Training Length Stability
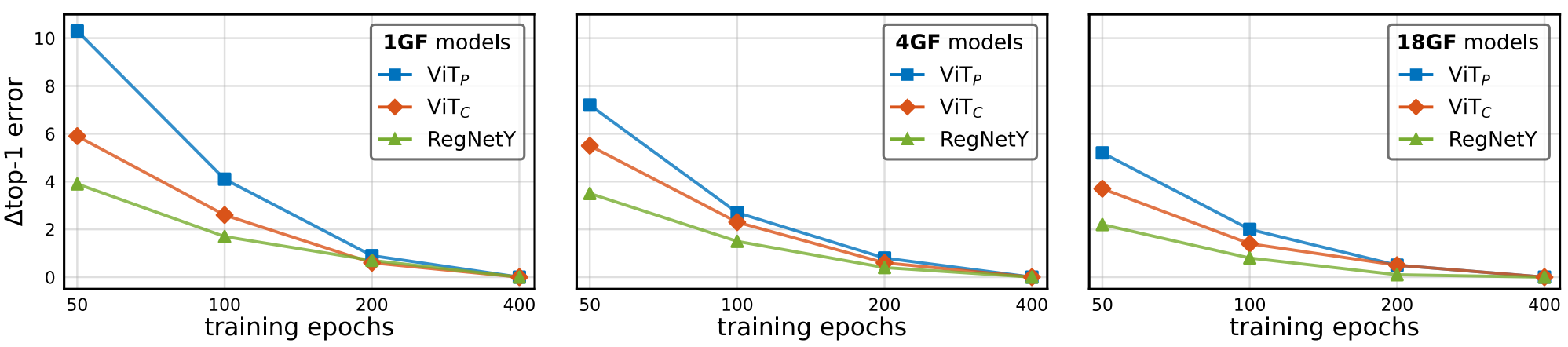
$\text{ViT}_C$ 모델이 CNN Baseline인 RegNetY와 비슷한 경향성을 보이며 $\text{ViT}_P$보다 빠르게 수렴하는 것을 볼 수 있다.
RegNetY는 학습 안정성이 좋은 SOTA CNN이다.
-
Optimizer Stability
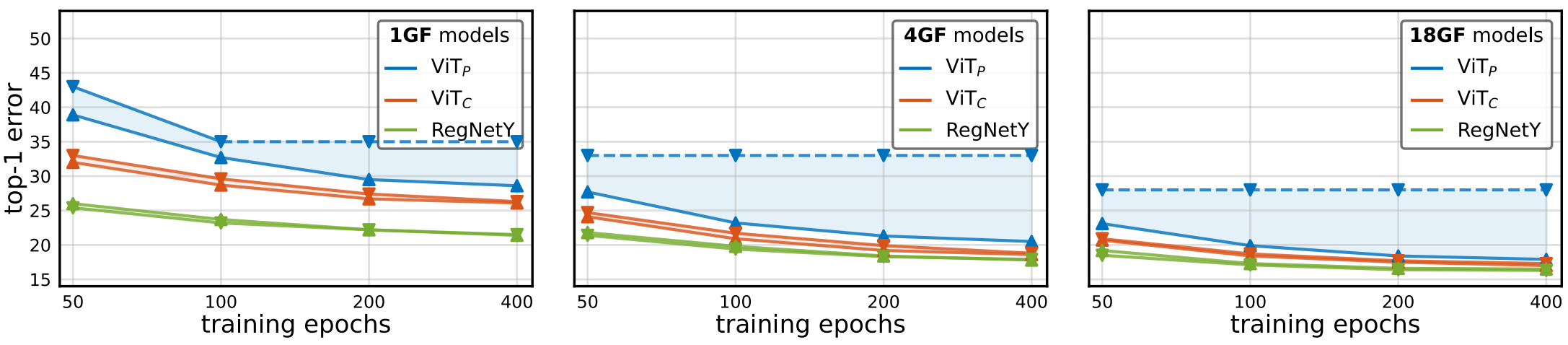
▲은 AdamW, ▼은 SGD를 사용했을 때 결과이다. $\text{ViT}_C$가 Optimizer에 따른 성능 차이가 RegNetY와 비슷하게 작음을 확인할 수 있다.
-
Hyperparameter($lr$ and $wd$) Stability
하이퍼파라미터의 영향을 확인하기 위해서는 다양한 하이퍼 파라미터에 대한 실험 결과가 있어야 한다. 따라서, 먼저 각 모델별 최적의 하이퍼 파라미터 근처의 값들을 동일 간격으로 64개 뽑아서 그려본다.
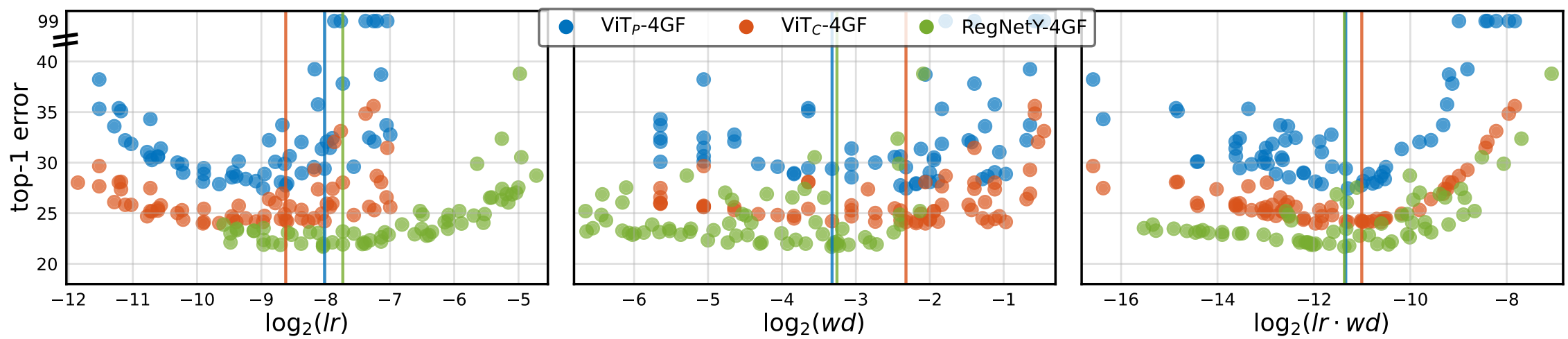
위 그래프는 AdamW를 이용해 학습시킨 결과다. 수직선은 최적의 파라미터다.
그리고 이를 이용해 Top-1 Error에 대한 누적 분포를 그린다.
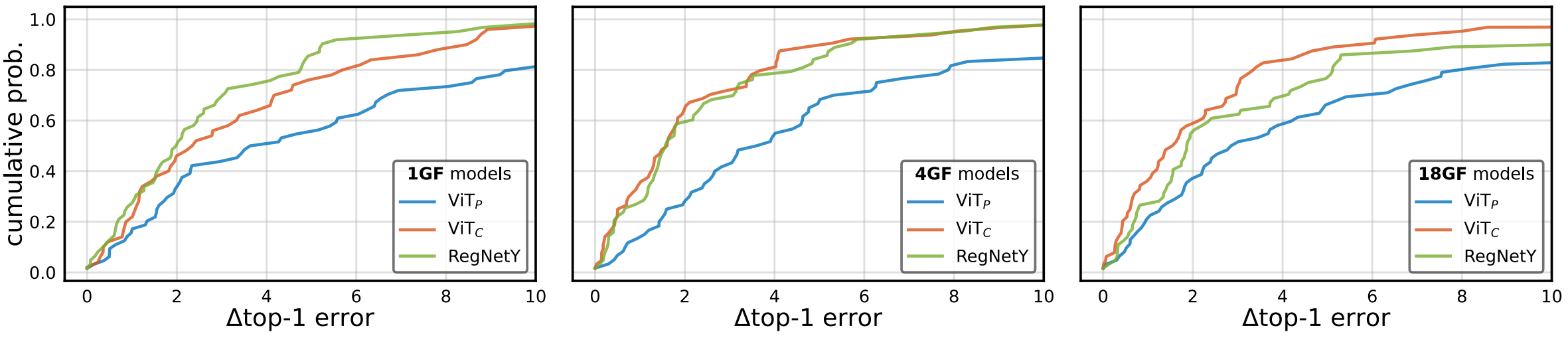
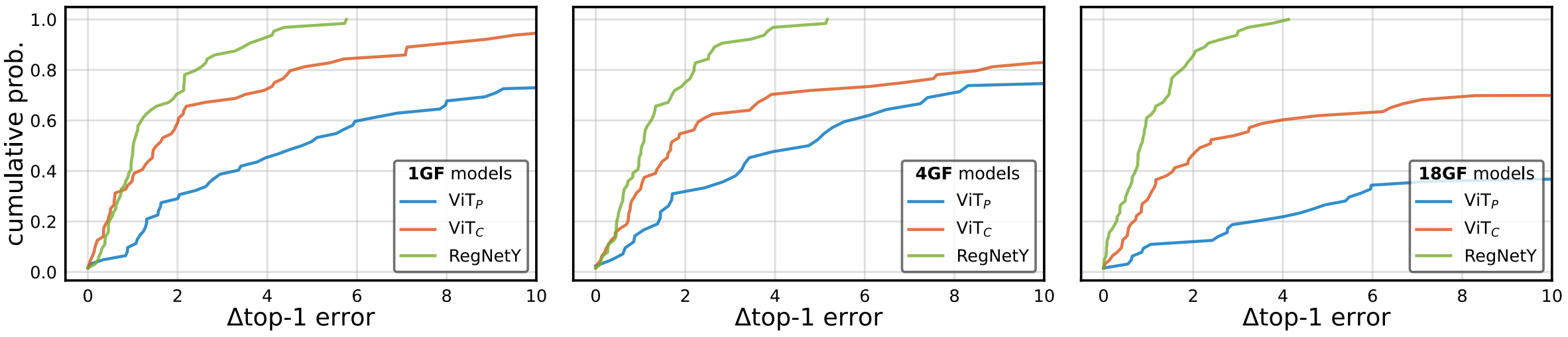
첫 행은 AdamW, 두 번째 행은 SGD의 결과에 대한 누적 분포이다.
누적분포이므로 결과 그래프가 가파르다면 Error가 낮은 결과값이 많다는 의미이므로 하이퍼 파라미터에 관계 없이 모델의 성능이 잘 나온다는 의미이다. 따라서, $\text{ViT}_C$가 $\text{ViT}_P$에 비해 상대적으로 RegNetY 정도로 하이퍼 파라미터의 변화에 Robust함을 확인할 수 있다.
학습 안정성 외에도 최고성능에 대한 비교 실험도 수행하는데, $\text{ViT}_P$ 보다 성능이 좋고 Large Scale로 확장하면 RegNet보다도 좋아진다 정도의 결과를 보여준다. 간단히 결과표만 보고 넘어가자.
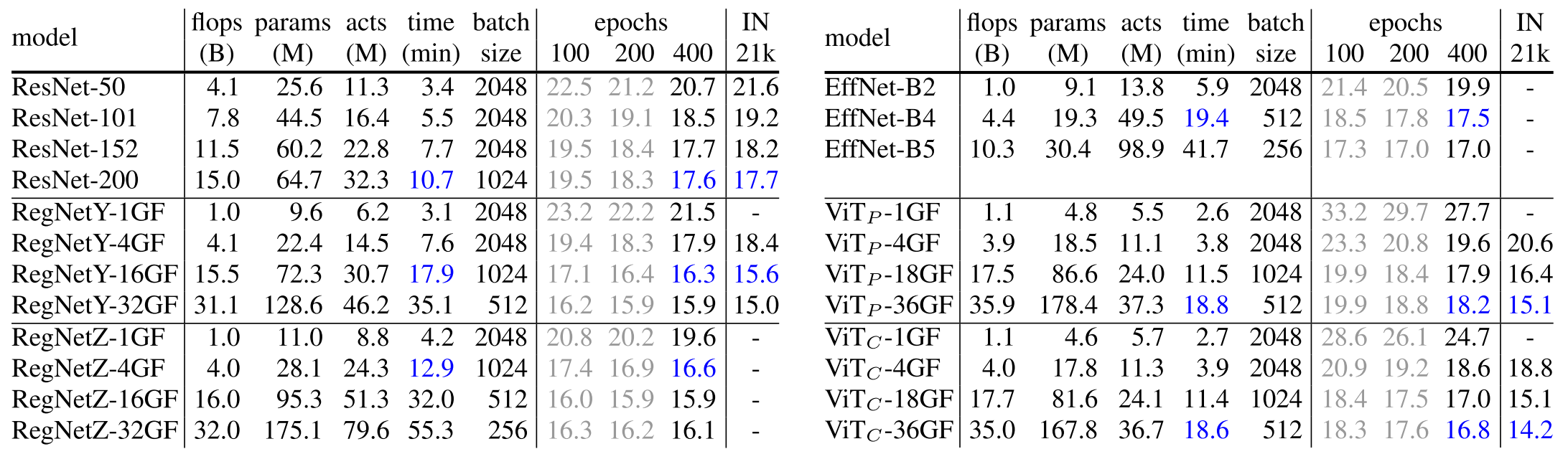
파란색 숫자는 한 Epoch당 20분 안으로 학습할 때 모델별 최고성능을 표시한 것이다.
Remarks
ViT 계열에 Inductive Bias를 넣는 논문들을 살펴보다가 발견해서 리뷰 한 논문. 몇몇 연구들이 ViT의 초기 층에서 Redundancy가 많음을 지적했는데 이를 간단한 Conv로 대체해서 Redundancy를 줄이면서 Vision에 유의미한 Inductive Bias를 추가해 간단한 방법으로 유의미한 결과를 보인게 아닌가 싶다.

Leave a comment