관련 링크 : https://arxiv.org/abs/1608.06993
Architecture : DenseNet(2016)
Abstract
최근 연구에서 CNN은 입력에 가까운 층과 출력에 가까운 층을 연결하면 더 깊고, 정확하고, 학습시키기 쉬워질 수 있음이 밝혀졌다. 따라서 본 논문에서는 이러한 직관을 활용해 각 층이 다른 모든 층과 연결되는 DenseNet을 도입한다. 일반적인 CNN은 $L$개의 층은 $L$개의 연결을 가지지만, DenseNet은 ${L(L+1)}\over 2$개를 가진다. 또한 DenseNet은 vanishing-gradient 약화, feature propagation 및 reuse 강화, 파라미터수 감소 등의 장점을 가진다.
1. Introduction
CNN의 연구가 층의 깊이를 늘려가는데 집중이되면서, 입력이나 gradient가 많은 층을 거치면서 사라지는 문제가 발생했다. ResNet이나 Highway Net은 층 사이에 identity connection을 연결해서 이를 해결했고, Stochastic depth는 확률적으로 층을 빼고 학습시켜서 해결하려 했다. FractalNet은 Fractal구조의 block을 이용해 구조를 짜고, 학습시 확률적으로 특정 패스를 선택해 학습시켜 해결하려 했다. 이 방법들의 공통점은 입력에 가까운 층과 출력에 가까운 층 사이에 경로를 만들어줬다는 것이다.
Stochastic Depth Review : 원문 FractalNet Review : 원문
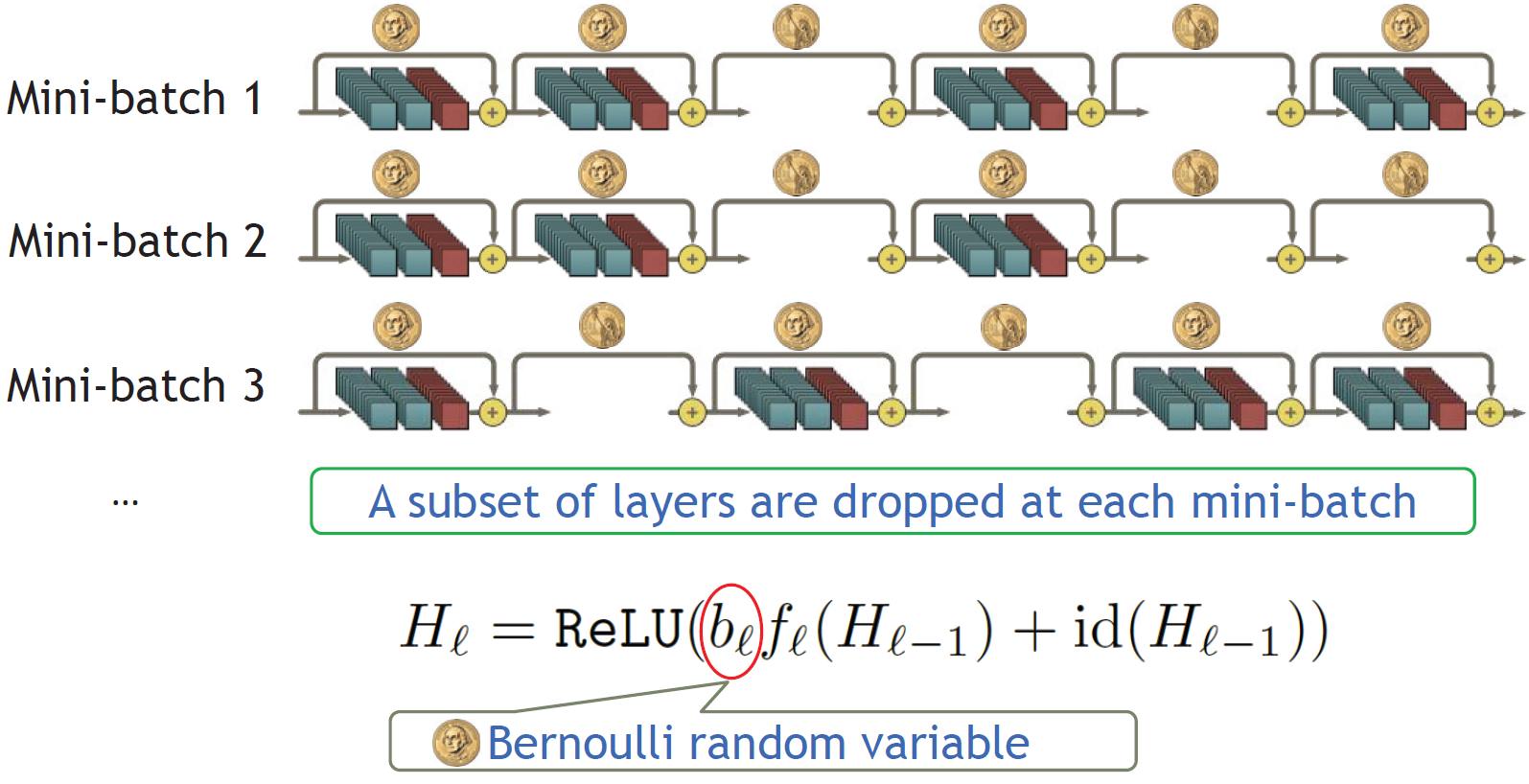
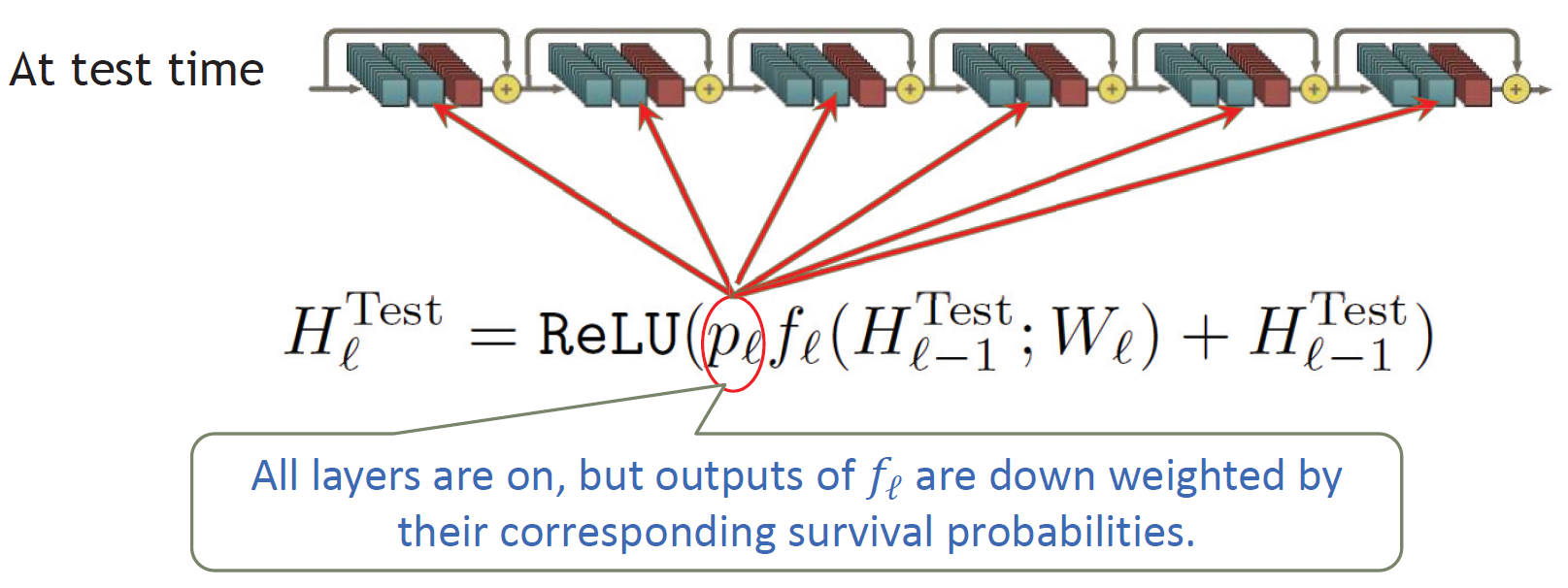
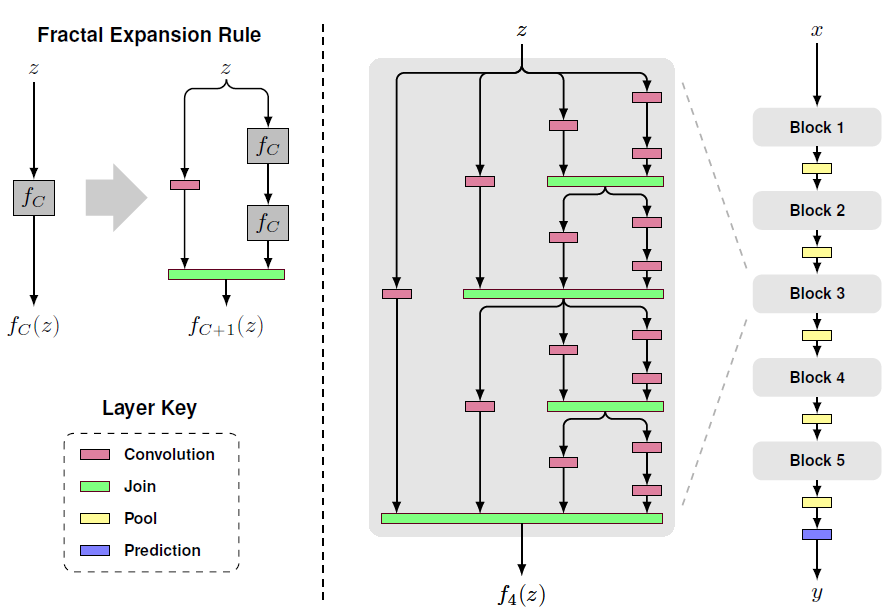
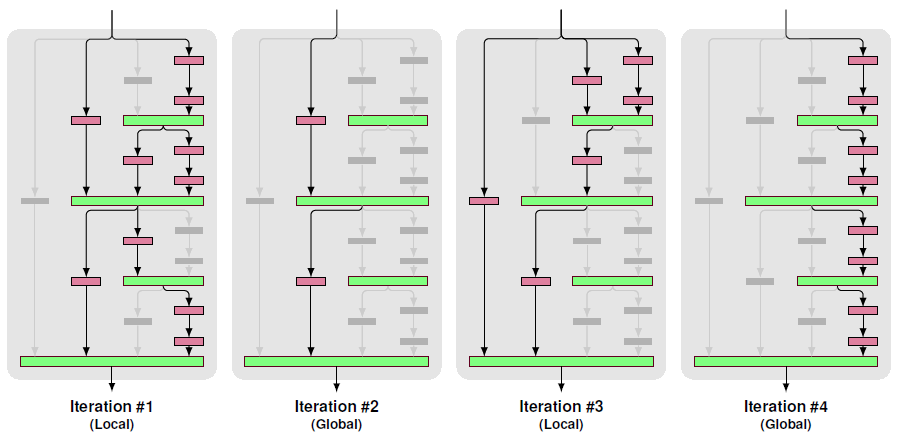
따라서 이 직관을 극대화시키기 위해 모든 층을 서로 연결시킨다. 연결시킬때 ResNet과는 다르게 summation이 아니라 concatenating을 사용한다.
일반적인 CNN은 이전 층에서 넘어온 정보 중 필요한 부분을 보존하면서 새로운 특징을 찾아 학습해 각 층이 가지는 차별화된 정보가 작았다. ResNet에선 필요한 부분을 보존하기위해 shortcut을 이용해 각 층의 차별화된 정보량을 늘렸다. 하지만 Stochastic Depth 논문에서 여전히 많은 층이 거의 기여하지 않음을 볼 수 있다.
DenseNet은 모든층이 shortcut으로 연결시켜 차별화된 정보를 극대화시켰고, 불필요한 층을 없애기 위해 깊이와 너비를 줄였으므로 파라미터수가 감소했다. 또 각 층은 loss function과 input signal 모두에서 gradient를 접근 할 수 있어 정보의 흐름을 향상시킨다.
2. Related Work
네트워크 구조에 관한 연구는 인공신경망 연구와 함께 발전해왔고, DenseNet의 구조와 유사한 아이디어는 예전에도 존재했다. 그 당시에는 작은 데이터셋에 효과적임만 밝혀졌고, 깊은 네트워크에는 적용되지 않았다. 하지만 최신 네트워크들은 많은 층수를 가지고, 많은 층수는 네트워크 구조간의 차이를 크게 만들어주는 요소이다.
HighwayNet은 100층 이상의 네트워크를 학습시킨 연구들 중 하나로, 게이팅 유닛을 이용해 정보를 우회시키는 방법을 이용했다. ResNet도 이와 유사한 방법을 사용했고, 차이점은 게이팅 유닛을 사용하지 않고 identity mapping을 이용한 우회로를 사용한 점이다. ResNet은 발표당시 많은 기록을 갈아치웠다.
ResNet의 후속 연구인 Stochastic Depth에서는 1202층의 ResNet을 성공적으로 학습시켰다. 핵심 방법은 학습시 무작위로 몇몇 층을 제외시키는 것인데, 이는 Deep ResNet이 불필요한 층을 많이 가지고 있음을 말해주었고 이는 DenseNet에 영감을 주었다.
우회로를 사용하는 방법 외에는 네트워크의 넓이를 늘리는 방법이 연구되었다. GoogleNet에서는 Inception Module을 이용해 다양한 사이즈의 필터로 만들어진 feature map을 합쳤다. Resnet In Resnet 연구에서는 폭이 넓어진 ResNet이 연구되었고 Wide Residual Network에서는 폭이 넓어지는게 성능을 향상시킴이 밝혀졌다. 이와 비슷한 결과는 Fractal Net에서도 볼 수 있다.
본 논문에서는 위의 방법들처럼 깊이와 폭을 늘려서 네트워크의 표현력을 늘리는 것 대신에, 특징 재사용에 초점을 둔다. 추가로, Network In Network(1x1 conv), Deeply Supervised Network(auxiliary classifier) 등의 방법도 사용했다.
3. DenseNets
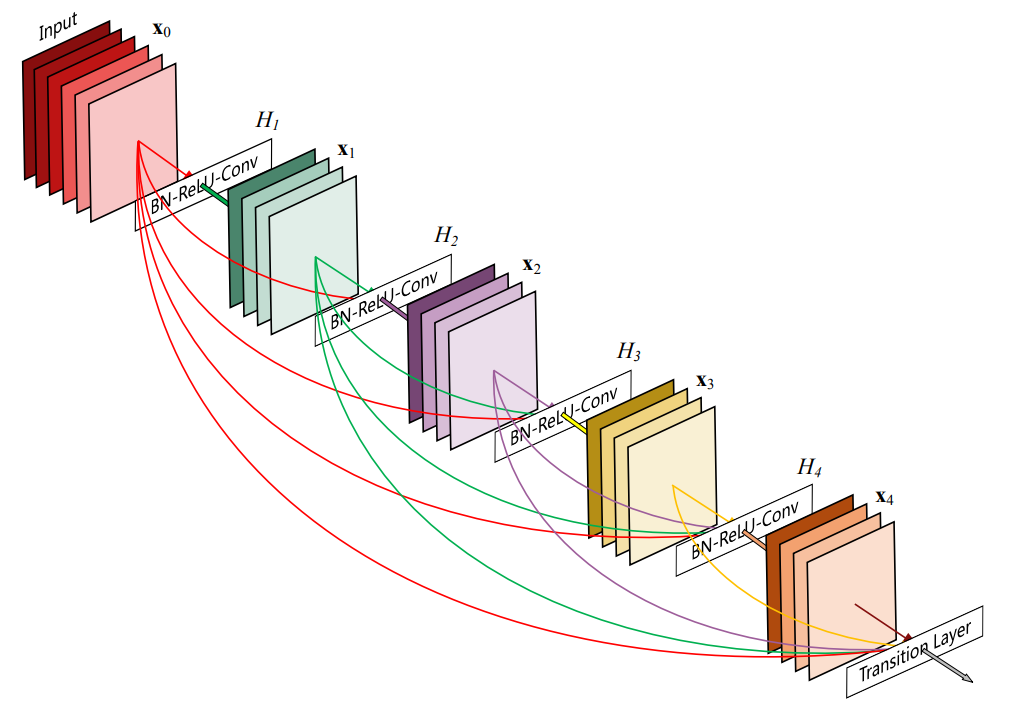
위 그림은 5층 dense 블럭으로, growth rate $k=4$이다.

위 그림은 ImageNet을 제외한 데이터셋에서 사용된 DenseNet의 대략적인 구조이다.
-
네트워크는 $L$개의 층으로 구성되고, 각 층은 비선형 변환 $H_{\ell}(\cdot)$을 실행한다. $H_{\ell}(\cdot)$는 BN-ReLU-Conv(3x3)의 합성함수이다.
-
위 그림에서 각 층의 연결 패턴은 다음과 같이 나타낼 수 있다.
\[\mathbf x_{\ell}=H_{\ell}([\mathbf x_0, \mathbf x_1,\ldots , \mathbf x_{\ell -1}])\]$[\mathbf x_0, \mathbf x_1,\ldots , \mathbf x_{\ell -1}]$는 $0, \dots ,\ell- 1$ 층에서 만든 feature map의 concatenation을 말한다.
-
Concat을 위해 입력과 출력의 resolution이 같아야하므로, 한 블럭안에서는 pooling하지 않고, 블럭과 블럭을 연결하는 Transition 층에서만 Pooling한다. Transition 층은 BN-Conv(1x1)-average Pooling(2x2)으로 이루어져 있다.
-
각 $H_{\ell}$은 growth rate라고 명명한 $k$개의 feature map을 만든다. 즉, $\ell ^{th}$층은 $k_0 +k \times (\ell -1)$개의 feature map을 입력으로 받아 $k$개의 feature map을 출력으로 내보낸다. ($k_0$는 입력 이미지의 채널 수이다.)
DenseNet에서는 한 블록안에서 각 층이 이전의 모든 feature map에 접근할 수 있고, 이는 집단 지식, 즉 global state에 접근 할 수 있음을 뜻한다. $k$를 growth rate라고 한 까닭은 각 층의 새로운 정보가 global state에 기여하는 정도를 결정하기 때문이다.
-
각 층이 받아들이는 입력의 수가 많으므로, 효율적인 계산을 위해 bottleneck 층을 도입한다. 따라서 이 경우 $H_\ell$은 BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)으로 이루어지고, 이러한 구조를 DenseNet-B라 한다. 실험에서 1x1 Conv는 $4k$의 feature map을 만든다.
-
모델의 compactness를 향상시키기 위해 transition 층에서 feature map 수를 줄인다. 하나의 dense 블럭이 $m$개의 feature map을 만든다면, compression factor $\theta$를 이용해 transition 층 이후 $[\theta m]$개의 feature map을 만든다. 실험에서는 $\theta = 0.5$를 사용하고, 이를 적용한 구조를 DenseNet-C라 한다.
bottleneck과 compression을 둘 다 사용하면 DenseNet-BC
Implementation Details
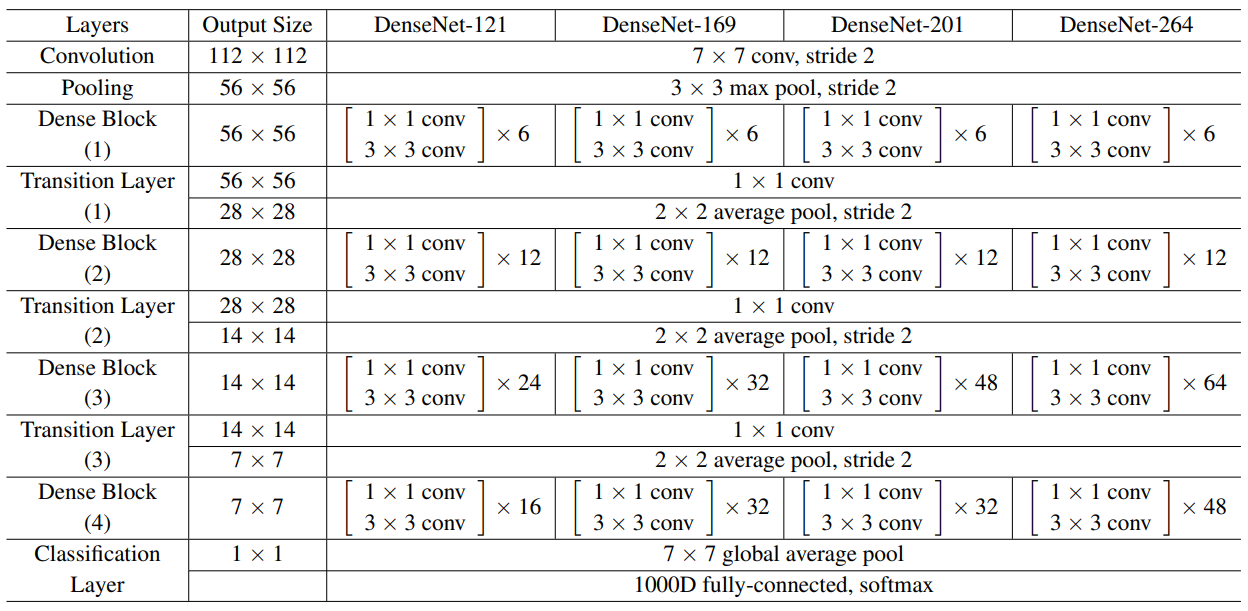
ImageNet을 제외한 데이터셋에서는 위 그림의 구조를 사용했다. 첫번째 Dense 블럭 전의 Conv(3x3)는 입력이미지의 채널을 16(DenseNet-BC의 경우 growth rate의 두배)으로 만들어 준다. 이 경우 기본 DenseNet 구조에서 $\{L=40, k=12\}$, $\{L=100, k=12\}$, $\{L=100, k=24\}$를, DenseNet-BC에서 $\{L=100, k=12\}$, $\{L=250, k=24\}$, $\{L=190, k=40\}$를 사용했다.
ImageNet 데이터셋에서는 DenseNet-BC 구조로 첫번째 Dense 블럭 전의 Conv에서는 $2k$개의 feature map을 만든다. 자세한 구조는 다음과 같다.($k=32$이고, Conv는 BN-ReLU-Conv를 뜻함)
4. Experiments
4.1 Datasets
CIFAR, SVHN, ImageNet을 사용하였고, 관례대로 다른 연구에서 사용된 Data Augmentation을 그대로 사용했다. 결과표에 augmentation을 한 경우는 “+”마크를 표시했다. 유명한 데이터셋들이라 자세한 설명은 생략한다.
4.2 Training
모든 데이터셋에서 weight decay는 $10^{-4}$, Nesterov momentum은 $0.9$를 사용했고, He initalization을 적용했다. Data augmentation을 사용하지 않은 CIFAR, SVHN데 데이터셋에서는 첫번째 conv를 제외하고 0.2 비율의 dropout 층을 추가했다.
- CIFAR : batch size=64, epoch=300, learning rate=0.1(divided by 10 at 50%, 75%)
- SVHN : batch size=64, epoch=40, learning rate=0.1(divided by 10 at 50%, 75%)
- ImageNet : batch size=256, epoch=90, learning rate=0.1(divided by 10 at 30, 60 epoch)
4.3 Classification Results on CIFAR and SVHN

굵은 글씨는 기존 SOTA를 능가한 것, 파란색은 최고 성능을 뜻한다.
- SVHN에서 250층 DenseNet-BC의 성능이 100층 DenseNet보다 좋지 않다. 이는 SVHN은 250층의 네트워크가 필요할 정도로 어려운 과제가 아니라 overfitting되었음을 말해준다.
- 기본 DenseNet에서 $L$과 $k$가 증가함에 따라 성능이 증가함을 확인 할 수 있다. 예외적으로 C10에서는 $k$의 증가가 overfitting을 일으켰지만, DenseNet-BC에서는 이 부분이 어느정도 해결되었음도 확인할 수 있다.
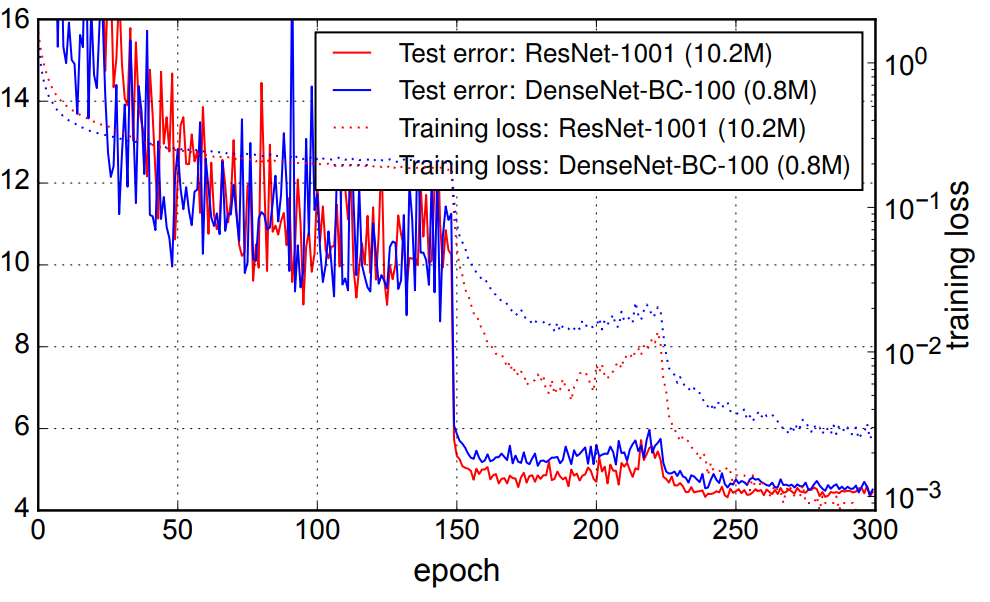
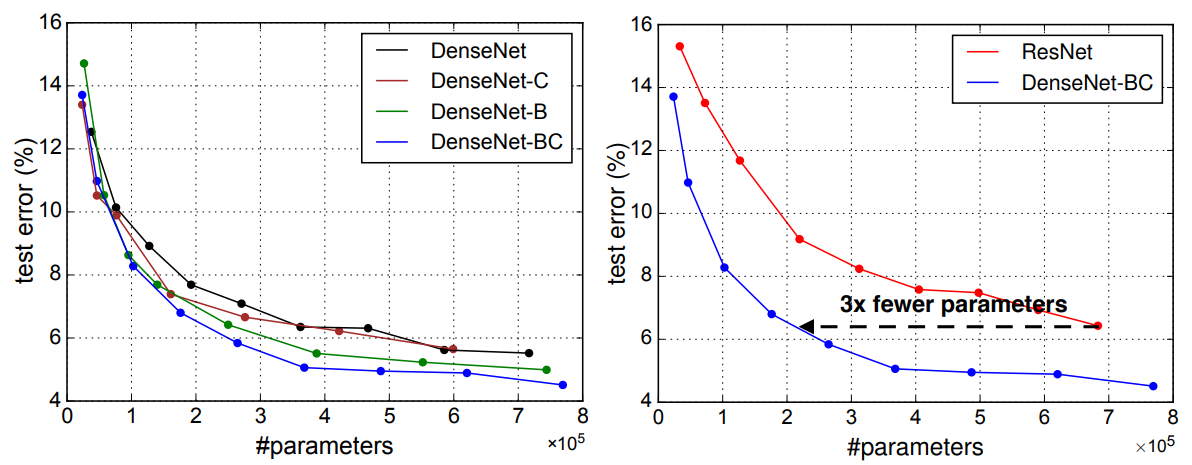
- DenseNet은 다른 네트워크보다 파라미터를 효율적으로 사용한다. 다음 그림을 보면 명확히 이해할 수 있다.
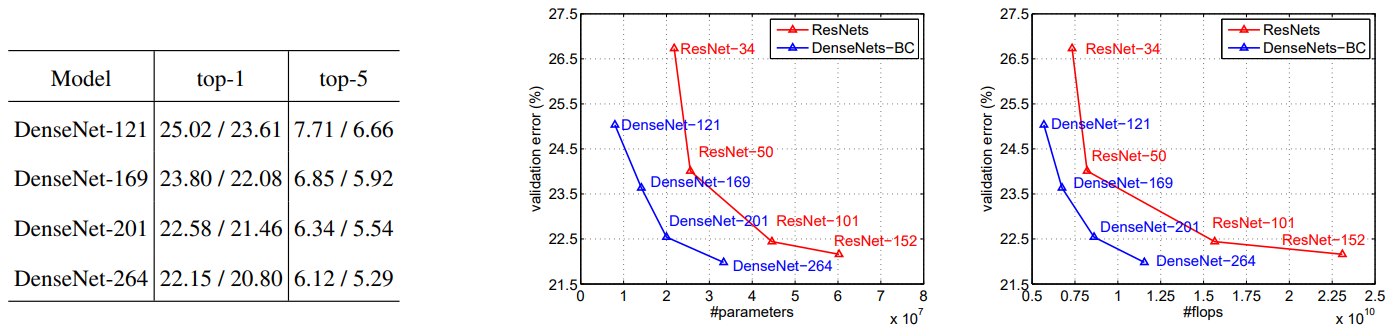
4.4 Classification Results on ImageNet
ResNet과 DenseNet을 공정히 비교하기 위해서 Pytorch의 ResNet 구현에서 네트워크만 DenseNet-BC로 바꾸고, 대부분의 하이퍼파라미터는 ResNet에 맞춰진채 실험했다.
결과적으로, 훨씬 적은 파라미터와 계산량을 가지고 좋은 성능을 보여주었다.
5. Discussion
DenseNet과 ResNet은 많은점이 유사하지만 결과적으로 상당히 다르게 작동한다.
- 각 층이 만든 feature map은 그 이후 모든 층이 접근할 수 있으므로 feature reuse가 높아져서 파라미터를 효율적으로 사용한다. ResNet과 비교했을때 1/3의 파라미터로 동일한 성능을 보였다.
-
모든 층이 shortcut을 통해 loss function과 연결되어 있으므로 중간층이 discriminative feature를 배울 수 있다. 이는 Deeply supervised net에서 사용된 auxiliary classifier와 유사한 효과다.
-
위에서 말한 Feature Reuse를 자세히 보자.
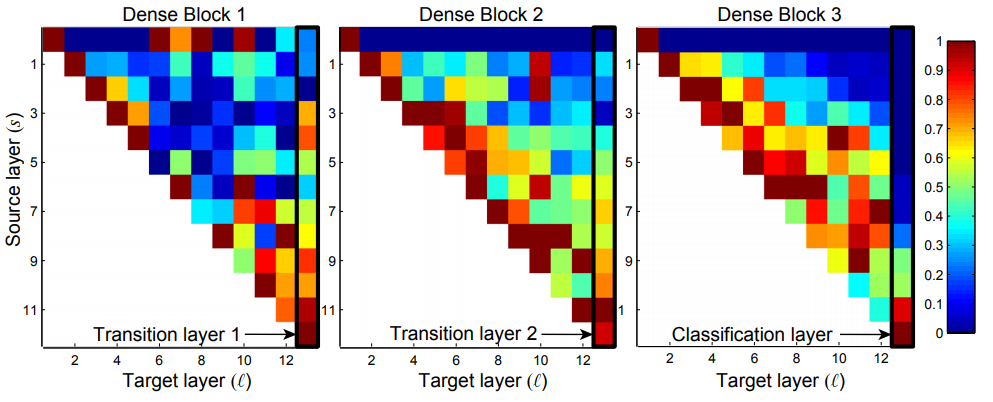
- 위 그림은 C10+로 학습시킨 $L=40$, $k=12$인 DenseNet의 weight의 $L1$ norm을 평균내고 normalize한 것이다. 각 점 $(s, \ell)$은 $s$층과 $\ell$층 사이의 weight를 뜻하고, 첫행은 Dense 블럭의 인풋, 마지막 열은 transition/classification 층을 뜻한다.
- 위 그림에서 각 열을 보면, 각 층이 다른 층에서 온 feature map에 가중치를 분산시켜놓고 있음을 볼 수 있다. 이는 블럭의 초기 층에서 만들어진 feature가 마지막 층에서도 사용 됨을 뜻한다.
- Transition 층의 weight도 각 층의 feature map에 고루 분산되어 있으므로 DenseNet의 입력부터 출력까지 정보의 흐름이 원활함을 알 수 있다.
- 두번째와 세번째 블럭의 첫번째 행에서 이전 블럭에서 온 feature map에 가중치를 적게 준 것으로 보아 transition 층의 출력에는 많은 불필요한 feature들이 있음을 알 수 있다. 그리고 이는 Compresstion factor를 이용한 DenseNet-BC가 성능이 더 좋은 이유를 뒷받침한다.
- Classification층을 보면 블럭안의 마지막 층에 가중치를 높게두는 것을 볼 수있다. 이는 네트워크의 마지막에 high-level feature들이 있음을 말해준다.
6. Conclusion
본 논문이 제안한 DenseNet은 feature map 크기가 같은 두 층 사이에 shortcut을 만들어 degradation이나 overfitting없이 간단히 수백층의 네트워크를 학습시킬 수 있었다. 또한 feature reuse를 증가시켜 redundancy를 낮춰서 적은 파라미터를 가지고 더 좋은 성능을 보였다.


Leave a comment