관련 링크 : https://arxiv.org/abs/1807.05520
Self-Supervised Learning : Deep Clustering(2018)
Abstract
Computer vision에서 광범위하게 적용되는 unsupervised method중 하나인 Clustering을 개량한 Deep Clustering을 제안한다. 이 방법은 잘 알려진 k-means 알고리즘을 이용해 feature들을 clustering하고, 이를 이용해 각 feature에 label을 할당하여 supervision으로 사용한다.
1. Introduction
Pretrained CNN은 다양한 vision task에서 일반화 성능이 좋은 features들을 얻기위해 사용되었다. ImageNet이라는 거대한 데이터셋 덕분에 pretrained model은 지속적으로 발전했다. 하지만 최근 연구에서 ImageNet 데이터셋은 사람에 의해 만들어졌으므로, 만든 사람들의 편견들을 반영한다는 경험적인 증거를 밝히면서 한계를 지적했다.
Stock and Cisse의 논문으로 ImageNet의 일부 편견들이 모델의 의사 결정과정에 큰 영향을 끼치고, 이는 그 모델을 운영하는 사회의 가치와 부합하지 않는다고 주장했다. 아래 사진은 그 예시들로, 동양인들은 탁구에, 흑인들은 농구로 예측하는 경향이 있다.

따라서 이런 편견들을 완화하기 위해 더 큰 데이터셋이 필요했다. 하지만 인터넷의 데이터의 metadata를 label로 사용하면 오히려 예측할 수 없는 결과를 내놓아 supervision없이 대용량의 데이터를 학습시킬수 있는 방법이 필요해졌다.
본 논문은 이런 unsupervised 방법중에 clustering 방법을 응용했다. 하지만 clustering은 고정된 feature들을 분류하기 위해 고안되었고, 따라서 clustering과 동시에 feature를 학습시키면 모델이 모든 feature를 0으로 만드는 trivial solution을 찾아내 학습 시킬 수 없다. 따라서 clustering과 feature training을 각각 분리 시키켜 모델을 학습시켰다. 간단히 아래 그림과 같이 요약할 수 있다.
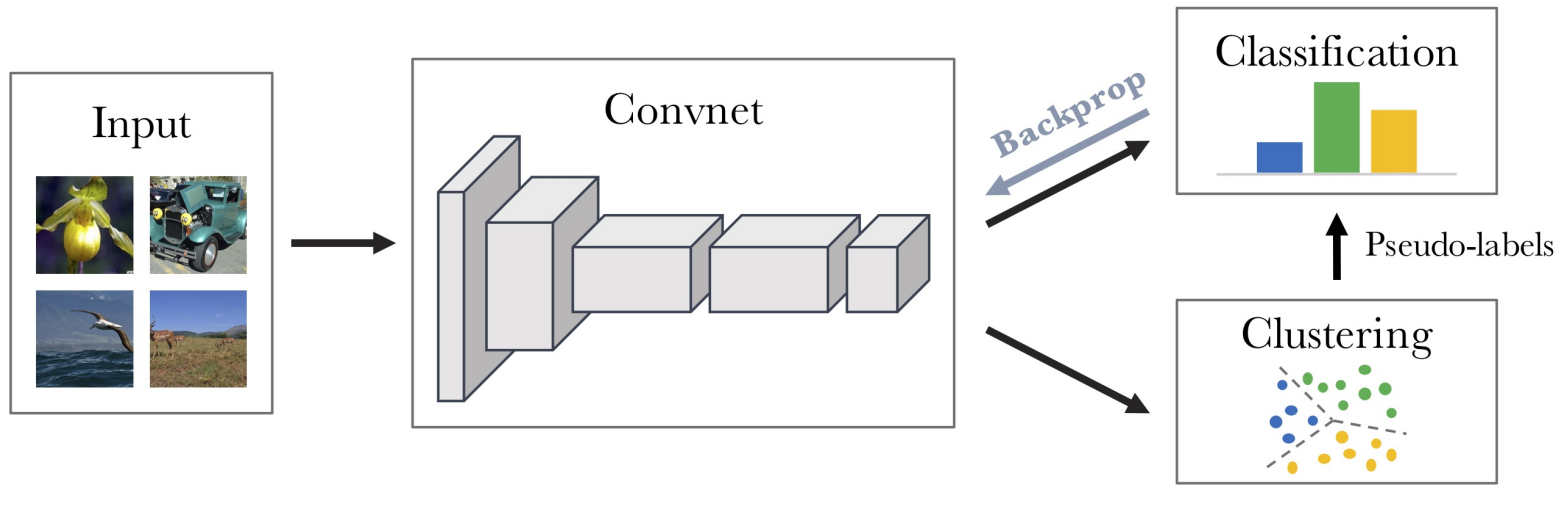
최종적으로 본 논문은 다음과 같은 공헌을 했다.
- k-means 알고리즘에 약간의 추가과정을 통해 end-to-end unsupervised method를 제안
- 많은 transfer task에서 다른 unsupervised method보다 좋은 성능을 보임
- ImageNet처럼 잘 정돈되지 않은 데이터셋에서 이전 SOTA보다 높은 성능을 냄
- Unsupervised feature learning의 evaluation protocol에 대한 고찰
2. Related Work
- Unsupervised learning of features : 기존 방법들 중 clustering을 고려한 방법들이 많았지만, 실제로 실험되진 않았다.
- Self-supervised learning : 데이터 그 자체에서 얻을 수 있는 pseudo-label을 이용해 pretext task를 학습시켜 유의미한 feature를 얻는 방법이다. 이미지를 분할시켜 뒤섞은 후, 원래 위치를 예측하는 pretext task등에서 비디오의 시공간적 특성을 이용하는 방법까지 다양한 방식이 있다. Clustering과는 다르게 데이터 자체에 대한 이해가 요구된다.
- Generative models : Unsupervised learning이 이용되는 대표적인 분야지만, GAN의 discriminator를 feature extractor로 사용해 보았을때 성능이 좋지 않았다.
3. Method
3.1 Preliminaries
Convnet은 이미지가 충분하다면, 이를 고정된 차원의 벡터 공간으로 맵핑하는 좋은 선택이다. 이 과정은 수식으로 표현된 다음과 같은 문제를 최적화하면서 수행한다.
\[\min_{\theta, W} \frac {1}{N}\sum ^N_{n=1}\ell(g_W(f_\theta(x_n)),y_n)\tag 1\]- $x_n$ : $X = \{x_1, x_2, \ldots, x_N\}$의 원소로 $N$개의 이미지를 가진 데이터셋에 속한다.
- $y_n$ : 이미지의 label로 클래스가 $K$개 있다면 각 원소가 $[0, 1]$에 속하는 $K$차원 벡터이다.
- $\ell$ : negative log-softmax로 cross-entropy와 동일하다.
- $f_\theta$ : 입력 이미지를 $d$차원 벡터로 맵핑한다. $\theta$는 convnet의 파라미터를 뜻한다.
- $g_W$ : $d$차원 벡터를 $K$차원 벡터로 맵핑한다. $W$는 분류기의 파라미터를 뜻한다.
3.2 Unsupervised learning by clustering
Convnet은 가우시안 분포에서 무작위로 샘플한 $\theta$를 사용해도 $12\%$정도의 성능을 보여준다. 이는 무작위로 예측했을때의 성능인 $0.1\%$보다 훨씬 높은 수치로, convnet의 구조가 입력신호에 대한 사전 확률을 주기 때문이다. 본 논문이 제안하는 Deep Clustering은 이러한 강점을 이용하는 방법으로, clustering을 통해 얻은 centroid matrix로 pseudo-label을 만들고 이를 supervision으로 사용한다. 이때 사용하는 clustering 방법은 k-means 알고리즘이다,
참고할 만한 연구가 없었기 때문에 표준적인 k-means를 사용했고, 부록에서 다른 알고리즘을 사용했을때도 좋은 성능을 보임을 증명했다.
이때 pseudo-label을 구하는 과정은 다음 수식으로 나타낼 수 있다.
\[\min_{C\in \mathbb R^{d\times k}}\frac {1}{N}\sum^N_{n=1}\min_{y_n\in\{0,1\}^k}\|f_\theta(x_n)-Cy_n\|^2_2\qquad \text{such that}\qquad y_n^\top1_k=1\tag 2\]- $C$ : centroid matrix로 $f_\theta(x_n)$의 차원이 $d$라면, $d\times K$차원의 행렬이다. $K$는 centroid의 수이다.
- $y_n$ : 구하고자 하는 pseudo-label이다.
- Clustering을 통해 $C$를 구하고, 이를 통해 $y_n$을 구한다.
- $y_n^\top 1_k=1$을 통해서 평범한 CNN 모델의 출력처럼 각 클래스의 확률로 나타낼 수 있다.
위 식을 통해서 opitmal한 $C$와 $y_n$을 구할 수 있지만, 이 과정은 $y_n$을 구하기 위함이므로 $C$는 학습에 사용하지 않는다. 또 Clustering과정과 파라미터 업데이트를 동시에 수행하면 trivial solution에 빠지기 쉬우므로 이를 완화할 방법을 소개한다.
3.3 Avoiding trivial solution
- Empty clusters Clustering 알고리즘은 결정 경계를 배우는 모델인데, 이런 모델의 optimal solution중에는 모델이 모든 입력을 하나의 cluster로 할당하는 것이 있다. 이는 간단히 clustering동안 입력이 할당되지 않은 cluster를 입력이 할당된 무작위 cluster와 동일하게 놓고 다시 수행해 해결할 수 있다.
- Trivial parametrization 또 다른 trivial solution은 clustering 알고리즘이 잘 동작해도, 많은 데이터들의 몇몇 cluster에만 할당된다면 식 (1)이 최소가 되도록 $f_\theta$가 특정 몇몇 cluster에 속하는 feature만 만들어 내도록 학습 될 수 있다. 이는 supervised learning에서도 데이터셋의 각 클래스의 균형이 무너지면 발생 할 수 있다. 이는 간단히 각 cluster에 할당된 데이터 수의 역수를 loss에 곱해주면 해결 할 수있다.
3.4 Implementation details
- Convnet architectures
- 이전 연구들과 비교를 위해 AlexNet과 VGG-16 Net을 사용했다. 두 아키텍쳐 모두 Batch Normalization을 사용했다.
-
기존 unsupervised method에서 색상이 부정적인 효과를 가져다 주었으므로, Sobel filter를 통해 색을 제거하고 대비를 증가시켰다.

- Training data : 별다른 언급이 없다면 ImageNet 데이터셋을 이용해 학습한 DeepCluster 모델을 사용한다.
- Optimization
- Center cropped된 이미지에 horizontal flip, random size crop등의 augmentation을 적용해 학습시켰다.
- $\ell_2$ regularization과 $0.9$의 momentum, $256$의 배치 사이즈를 사용했다.
Learning rate나 Optimizer는 별 다른 언급이 없다.
- k-means를 이용한 clustering은 ImageNet에서는 매 에폭마다 수행해 주었는데, 이 과정이 총 학습시간의 $1/3$을 차지했다. 따라서 특정한 $n$ 에폭마다 수행해봤는데, 매 에폭마다 수행하는게 효과가 가장 좋았다. 또 다른 uncurated 데이터셋인 Flickr에서는 이 과정이 정확도에 미치는 영향이 모호해 ImageNet과 동일한 과정을 따랐다.
- Hyperparameter selection : PASCAL VOC object classification같은 downstream task의 하이퍼파라미터를 사용했다.
4. Experiments
4.1 Preliminary study
본 논문은 Normalized Mutual Information이란 방법을 통해 동일한 데이터의 다른 형태인 $A$, $B$ 사이의 공유된 정보를 측정한다.
\[\mathrm{NMI}(A;B)=\frac {\mathrm I(A;B)}{\sqrt{\mathrm H(A)\mathrm H(B)}}\]- $\mathrm I$는 상호 정보량, $\mathrm H$는 엔트로피를 나타낸다.
- $A$, $B$가 독립적이라면 $0$에 가깝고 반대라면 $1$에 가깝다.
이를 이용해 두 가지 실험을 수행하고, $k$의 개수가 성능에 미치는 영향을 확인해본다.
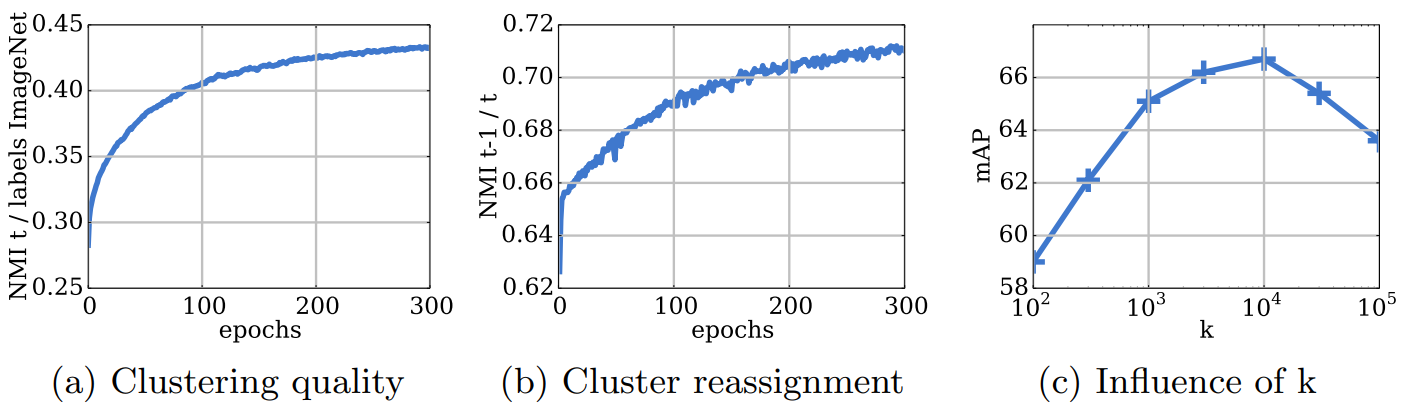
- (a)에서는 true label과 pseudo-label의 NMI를 계산해서 모델이 class level information을 예측하는 능력을 측정한다. 즉, 이 값이 높다면 pseudo-label이 true label과 유사하므로 모델의 성능이 좋다.
- (b)에서는 $t-1$ 에폭과 $t$ 에폭에서의 의 cluster의 NMI를 계산해 모델의 안정성을 측정한다. 이 값이 증가하면 매 에폭마다 cluster가 새로운 위치로 재할당 되는 빈도가 줄어든다. 또 실험결과 $0.8$ 이상으로 증가하지 않는데, 이는 매 에폭마다 $20\%$이상의 cluster가 재할당 됨을 의미한다.
- (c)에서는 $k$의 값이 성능에 PASCAL VOC detection 성능에 미치는 영향을 보여준다. ImageNet 데이터셋을 사용했으므로 $10^3$가 최적이라고 예상했지만, 실제로는 $10^4$가 최적이고 이는 downstream task에서 어느정도 큰 $k$를 사용하는게 유리함을 알려준다.
4.2 Visualilzations
-
First layer filters RGB 이미지와 Sobel filter가 적용된 이미지로 각각 학습된 두 모델의 첫번째 층의 feature들을 비교해본다. 아래 사진의 좌측은 RGB 이미지로 학습된 모델로, object classfication에 별 다른 영향을 주지 못하는 색상에 관한 정보들에 치중되었다면 우측은 무늬에 치중된 정보들을 학습했다.

-
Probing deeper layers

특정 필터의 activation이 최대가 되도록하는 이미지를 만들어 시각화 했다. 각 층의 두번째 열은 YFCC100M 데이터셋에서 가장 activation이 높은 9개의 이미지를 보여준다.
- 층이 깊어질수록 필터들이 더 구체적인 정보들을 보인다.
- 두 번째 행에서 conv3과 conv5의 가장 activation이 높은 이미지들이 유사하고, 시각화 이미지 역시 어느 정도 유사한 것에서 conv3이 conv5보다 더 discriminative 하다는 이전 연구들을 어느정도 증명할 수 있다.

위 실험과 동일하게 YFCC100M 데이터셋에서 가장 activation이 높은 이미지들을 보여준다. 이때 기준 층은 마지막 층이다.
- 첫 번째 행은 서로 연관된 객체들을 포함한 이미지가 특정 필터의 activation을 최대화 시킴을 보여준다.
- 두 번째 행은 비슷한 스타일의 이미지가 특정 필터의 activation을 최대화 시킴을 보여준다. Filter 119는 배경이 흐리고 객체가 강조되는 스타일, Filter 182는 원근법에 의해 가까운 객체가 더 잘 보이는 스타일의 사진들이 모여있다.
4.3 Linear classification on activations
Convnet을 고정시키고 linear classficiation을 수행하면 feature의 일반화 성능이나 어떤 층부터 task specific해지는지 알 수 있다. 이를 실험을 통해 확인한다.
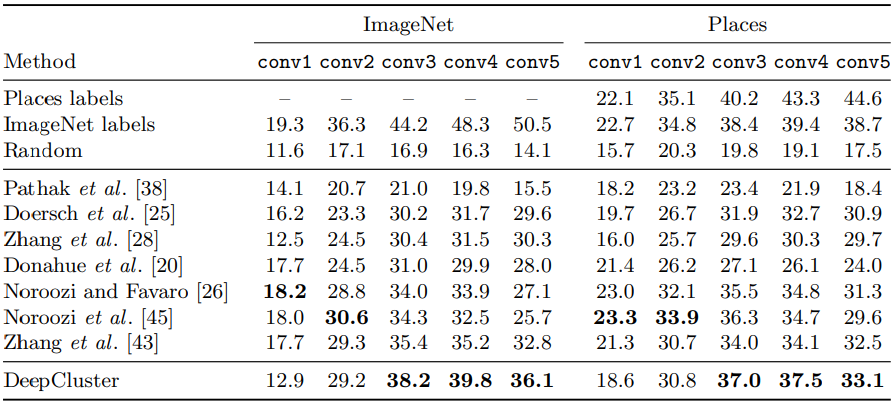
Places, ImageNet label, Random등은 supervised method로, 성능 비교의 기준점이 된다. Random은 최저 성능, ImageNet은 도달하고자 하는 성능으로 볼 수 있다. 부록에서 다른 방법들의 수치는 single crop의 성능임을 알고 본 논문의 방법은 10 crop의 성능이라 공정한 비교가 아님을 밝힌다. 하지만 single crop에서의 성능이 약간 더 좋거나 나빠도 $3\%$이므로 큰 맥락에서는 다르지 않다고 덧붙인다.
- Supervised method들은 층이 깊어질수록 성능이 좋아지지만, 다른 방법들은 마지막층보다 그 전층에서의 성능이 더 높다. 이는 각 방법들이 마지막 층에서는 학습할때 수행된 task에 specific해지기 때문이다.
- Places데이터셋에서 ImageNet으로 학습된 모델의 성능을 측정해보면 unsupervised method처럼 마지막층 보다 그 전층에서 성능이 더 높다. 또 DeepCluster와도 큰 차이가 없다. 이는 target task의 domain이 선학습된 모델의 domain과 상당히 다르다면, label을 이용한 supervision의 효과가 약해짐을 뜻한다.
4.4 Pascal VOC 2007
여러 downstream task에서의 성능을 평가한다.
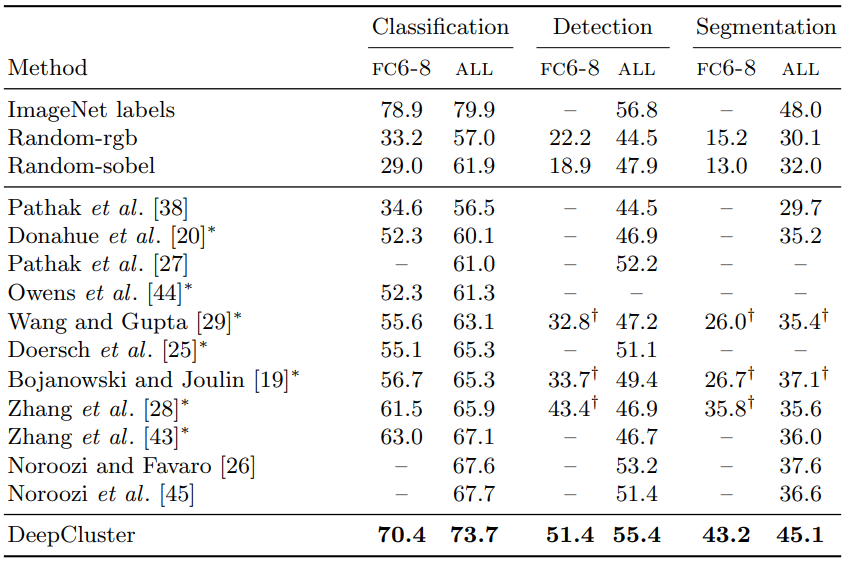
Detection은 fast-rcnn, Segmentation은 FCN을 이용했다. $\dagger$는 직접 실헙한 결과들이고, $*$는 성능 향상을 위한 initialization을 도입했을때 결과이다.
- 당연하게도 모든 층을 finetuning한 ALL의 성능이, 최종 분류기만 학습한 FC6-8보다 더 좋다.
- 많은 unsupervised method가 모든 층을 finetuning 했을때 Random으로 초기화한 convnet과 비슷한 성능을 보인다. 하지만 feature만 봤을때는 격차가 상당하다.
5. Discussion
기존의 unsupervised method 평가 방식은 imageNet으로 학습한 AlexNet 모델의 class-level task 성능을 측정하는 것이었다. 본 논문에서는 DeepCluster의 효과를 더 자세히 알기위해 다양한 데이터셋, 다양한 모델 아키텍쳐, instance-level task의 성능을 평가한다.
5.1 ImageNet versus YFCC100M
앞서 논의했듯이 DeepCluster는 고르게 분포된 cluster를 선호하고, $k$값에 영향을 받는다. 하지만 ImageNet 데이터셋은 각 클래스당 샘플수가 일정하고 $k$값은 데이터셋의 클래스수와 어느정도 연관이 있으므로, 이 방법이 이런것을 고려할 필요 없는 다른 방법들보다 유리하게 시작했다고 볼 수 있다. 따라서 이런 요소들의 중요성을 비교하기 위해 클래스당 샘플의 수가 불균형하고 포함된 클래스의 수가 몇개인지 모르도록 YFCC100M에서 무작위로 1M개의 데이터를 뽑아 DeepCluster를 학습시켜 성능을 비교한다.
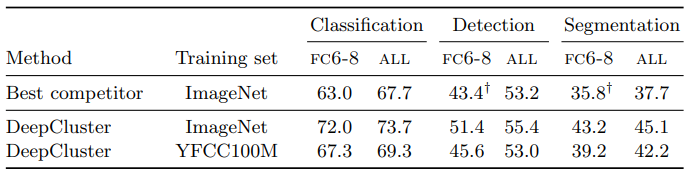
- 여전히 DeepCluster가 다른 방법들보다 성능이 뛰어나다. 즉, uncurated 데이터셋에서도 의미있는 feature들을 학습할 수 있다.
5.2 AlexNet versus VGG
Supervised method에서 VGG같은 더 깊은 모델을 사용하면 성능이 증가하므로, unsupervised method에서도 그럴 것이라고 예상하고 실험을 진행했다.
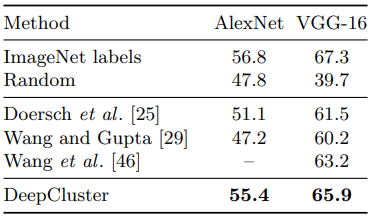
Pascal VOC 2007 object detection task 수행했고, 모든 모델은 finetuning했다.
- 더 깊은 모델을 사용했을때 성능이 증가했다. 하지만 Random의 경우 오히려 줄어들었는데, 전체 층을 finetuning 했을때 결과이므로 DeepCluster의 필요성이 더욱 드러난다.
- 성능은 증가했으나 supervised method와의 차이는 여전하다.
5.3 Evaluation on instance retrieval
기존의 성능 측정 방식은 class level task이므로, intance retrieval task를 통해 각각을 잘 구분 할 수 있는지 평가해본다.
class level task는 같은 클래스에 속한 시각적으로 다른 이미지를 같다고 말하지만, instance level task는 클래스에 상관없이 시각적으로 다른 이미지를 다르다고 말할 수 있는지를 물어 본다고 생각하면 될 것 같다.
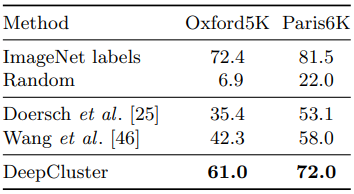
Instance-level image retrieval task를 실험했다. DeepCluster에만 Sobel filter를 적용했다.
- Random의 경우 class level task와 다르게 처참한 성능을 보인다. 이는 pretrained model의 필요성을 보여준다.
- 다른 방법들에 비해 DeepCluster가 성능이 좋다. Oxford5K의 경우 Sobel filter를 사용했을때 성능이 $5.5\%$ 높았지만, 이 차이가 $19\%$의 격차를 뒤집을 정도는 아니다.
6. Conclusion
- Clustering 알고리즘을 이용한 unsupervised method를 제안한다.
- DeepCluster는 큰 데이터셋을 이용했을때 기존의 transfer task에서 최고성능을 보인다.
- Input data이 아닌 모델의 구조적 강점을 극대화 시켰으므로 입력 데이터에 관한 지식을 필요로하지 않는다.
Leave a comment